金融量化分析【day110】:Pandas的Series对象
一、pandas简介安装
pandas是一个强大的python数据分析的工具包
pandsa是基于NumPy构建的
1、pandas的主要功能
1、具备对其功能的数据结构DataFrame、Series
2、集成时间序列功能
3、提供丰富的数学运算和操作
4、灵活处理缺失数据
2、安装方法
1 | pip install pandas |
3、引用方法
1 | import pandas as pd |
二、Series对象
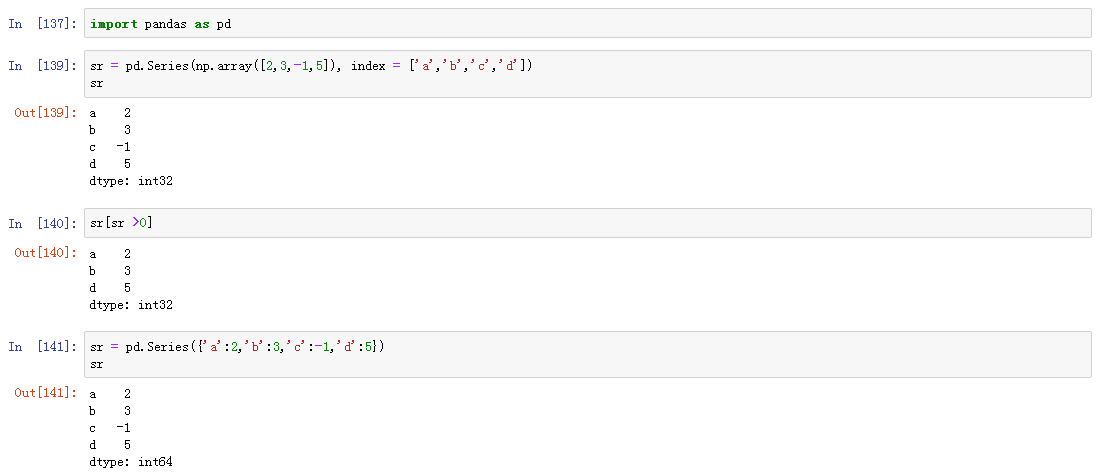
1、pandas的Series对象是一个带索引数据构成的一维数组,可以用一个数组创建Series对象
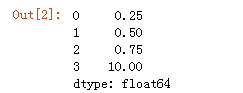
1 2 3 4 | import numpy as npimport pandas as pddata = pd.Series([0.25,0.5,0.75,10])data |

2、Series是通用NumPy数组
1 | data = pd.Series([0.25,0.5,0.75,10],index=['a','b','c','d']) |

1 | data = pd.Series([0.25,0.5,0.75,10],index=['2','5','3','7']) |

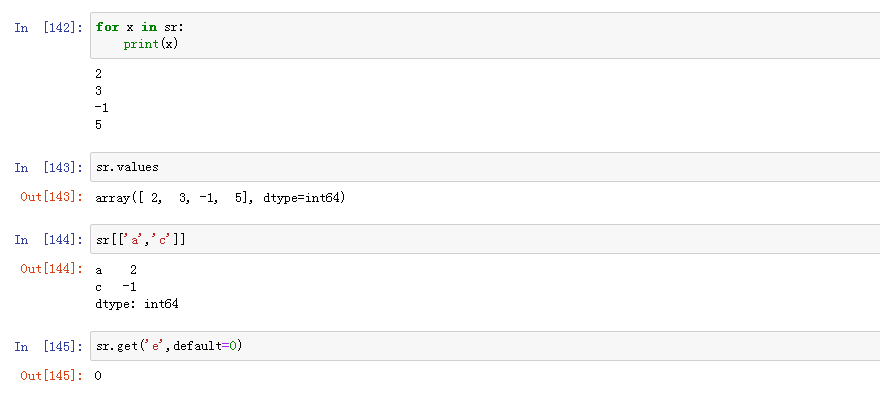
3、Series是特殊的字典
1 2 3 4 | area_dict = {'California': 423967, 'Texas': 695662, 'New York': 141297,'Florida': 170312, 'Illinois': 149995}area = pd.Series(area_dict)area |

三、Series数据对齐
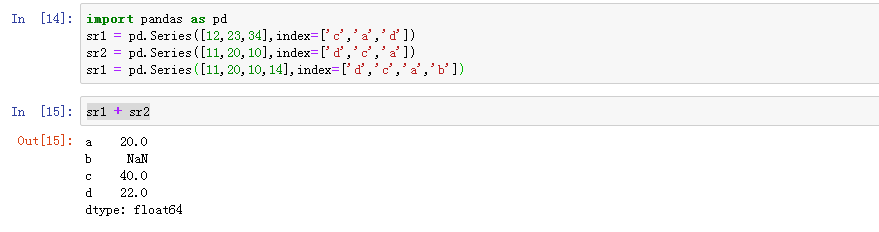
1、pandas在运算时,会按索引进行对齐然后计算,如果存在不同的索引,则结果的索引是两个操作数索引的并集
1、sr1+sr2

2、sr1+sr3
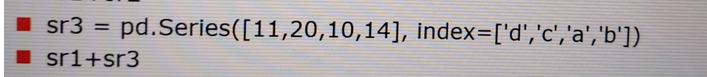


2、如何在两个Series对象相加时将缺失值设置为0?
三、缺失数据
缺失数据:使用NaN(Not a Number)来表示缺失数据,其值等于np.nan
内置的None值也会被当做NaN处理
1、发现缺失数据
1、data.isnull()创建一个布尔类型的掩码标签缺失值
1 2 3 4 | import numpy as npimport pandas as pddata = pd.Series([1, np.nan, 'hello', None])data.isnull() |

1、data[data.notnull()与data.isnull()操作相反
1 | data[data.notnull()] |
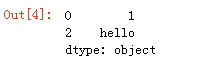
2、剔除缺失数据
1、dropna()返回一个剔除缺失值的数据(剔除任何包含缺失值的整行数据)
1 | df3.dropna() |

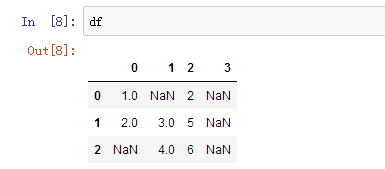
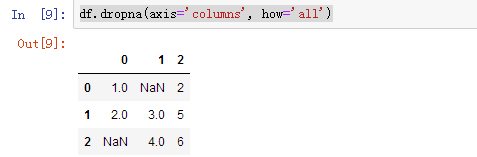
2、dropna(how='any')返回一个剔除缺失值的数据(会剔除任何包含缺失值的整列数据)
1 | df.dropna(axis='columns', how='all') |
3、dropna(how='any')返回一个剔除缺失值的数据(只要有缺失值就剔除整行或整列)
1 | df2.dropna(how='any') |

1 | df2[df2['close'].notnull()] |
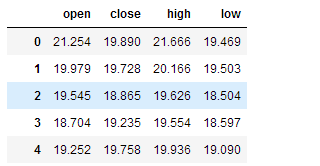
4、dropna(how='any')返回一个剔除缺失值的数据(行或列中非缺失值的最小数量)
1 | df.dropna(axis='rows', thresh=3) |

第一行和第三行被剔除了,因为他们只包含两个非缺失值
3、填充缺失数据
有时候你可你可能并不想移除缺失值,而是想把他们替换成有效的数值,有效的值可能想0,1,2那样单独的值,也可能
是经过填充(imputation)或转换(interpolation)得到的,虽然你可以通过isnull方法建立掩码来填充缺失值,但是Pandas
为此专门提供了一个fillna(0)方法,他将返回填充缺失值后的数组副本
1 2 | data = pd.Series([1, np.nan, 2, None, 3], index=list('abcde'))data |
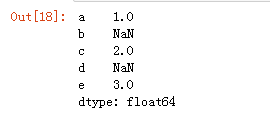
1、data.fillna(0)单独的值填充缺失值
1 | data.fillna(0) |
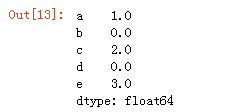
2、method='ffill' 可以用缺失值前面的有效值来从前往后填充
1 | data.fillna(method='ffill') |

3、method='bfill' 也可以用缺失值的有效值从后向前填充
1 | data.fillna(method='bfill') |

4、DataFrame的操作方法与Series类似,只是在填充时候需要设置坐标轴参数axis
1 | df.fillna(method='ffill', axis=1) |
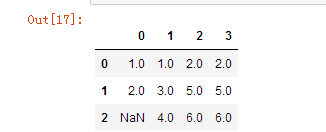
需要注意的是,假如从前往后填充式,需要填充的却是值前面没有值,那么他就仍然是缺失值
4、对不同趋势值的转换规则

作者:罗阿红
出处:http://www.cnblogs.com/luoahong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core内存结构体系(Windows环境)底层原理浅谈
· C# 深度学习:对抗生成网络(GAN)训练头像生成模型
· .NET 适配 HarmonyOS 进展
· .NET 进程 stackoverflow异常后,还可以接收 TCP 连接请求吗?
· SQL Server统计信息更新会被阻塞或引起会话阻塞吗?
· 传国玉玺易主,ai.com竟然跳转到国产AI
· 本地部署 DeepSeek:小白也能轻松搞定!
· 自己如何在本地电脑从零搭建DeepSeek!手把手教学,快来看看! (建议收藏)
· 我们是如何解决abp身上的几个痛点
· 普通人也能轻松掌握的20个DeepSeek高频提示词(2025版)