深入剖析Kubernetes学习笔记:“控制器”模型(16)
一、Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已
1、属性字段和吊环

2、操作这些“集装箱”的逻辑

二、kube-controller-manager组件
我在前面介绍 Kubernetes 架构的时候,曾经提到过一个叫作 kube-controller-manager 的组件。
实际上,这个组件,就是一系列控制器的集合。我们可以查看一下 Kubernetes 项目的 pkg/controller 目录:
$ cd kubernetes/pkg/controller/ $ ls -d */ deployment/ job/ podautoscaler/ cloud/ disruption/ namespace/ replicaset/ serviceaccount/ volume/ cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/ ...
这个目录下面的每一个控制器,都以独有的方式负责某种编排功能。而我们的 Deployment,正是这些控制器中的一种。
实际上,这些控制器之所以被统一放在 pkg/controller 目录下,就是因为它们都遵循 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。
三、控制循环
比如,现在有一种待编排的对象 X,它有一个对应的控制器。那么,我就可以用一段 Go 语言风格的伪代码,为你描述这个控制循环:
for {
实际状态 := 获取集群中对象 X 的实际状态(Actual State)
期望状态 := 获取集群中对象 X 的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
1、在具体实现中,实际状态往往来自于 Kubernetes 集群本身

2、而期望状态,一般来自于用户提交的 YAML 文件。

3、控制器模型的实现

4、控制循环

5、PodTemplate

6、控制器的组成
至此,我们就可以对 Deployment 以及其他类似的控制器,做一个简单总结了

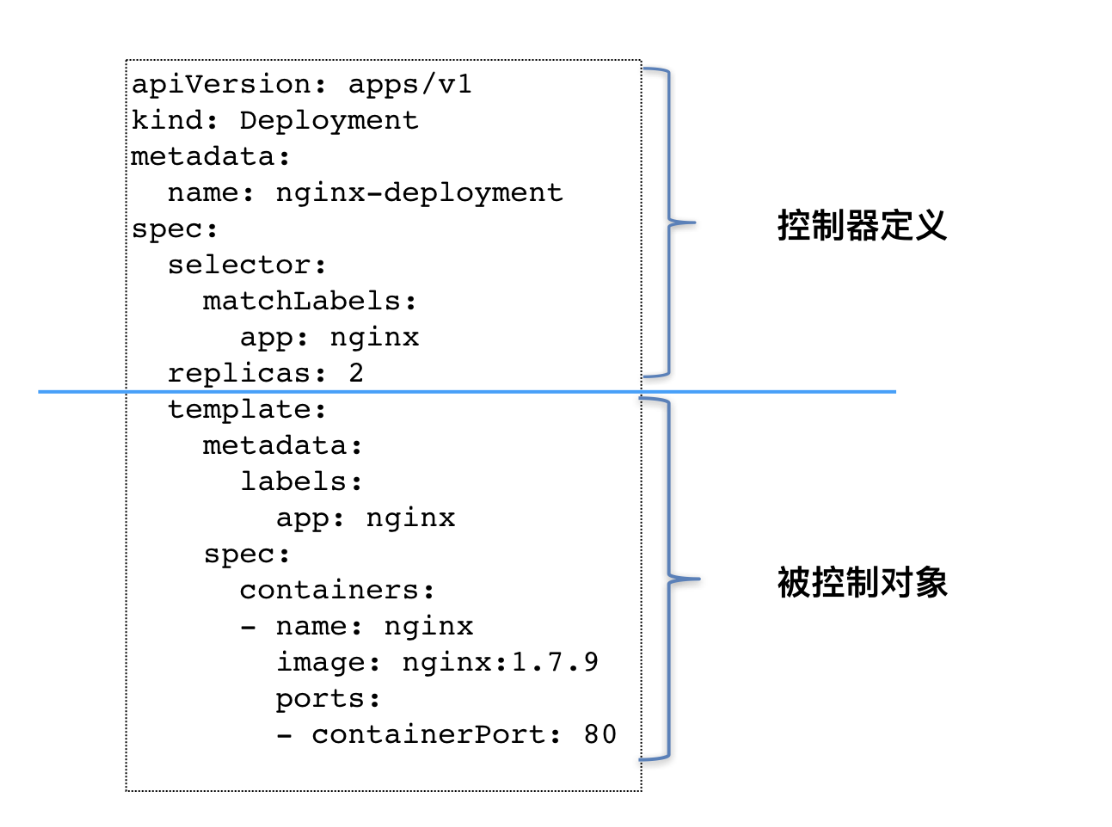
这就是为什么?
作者:罗阿红
出处:http://www.cnblogs.com/luoahong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号