深入浅出计算机组成原理学习笔记:第三十六讲
平时进行服务端软件开发的时候,我们通常会把数据存储在数据库里。而服务端系统遇到的第一个性能瓶颈,往往就发生在访问数据库的时候。
这个时候,大部分工程师和架构师会拿出一种叫作“缓存”的武器,通过使用Redis或者Memcache这样的开源软件,在数据库前面提供一层缓存的数据,
来缓解数据库面临的压力,提升服务端的程序性能。
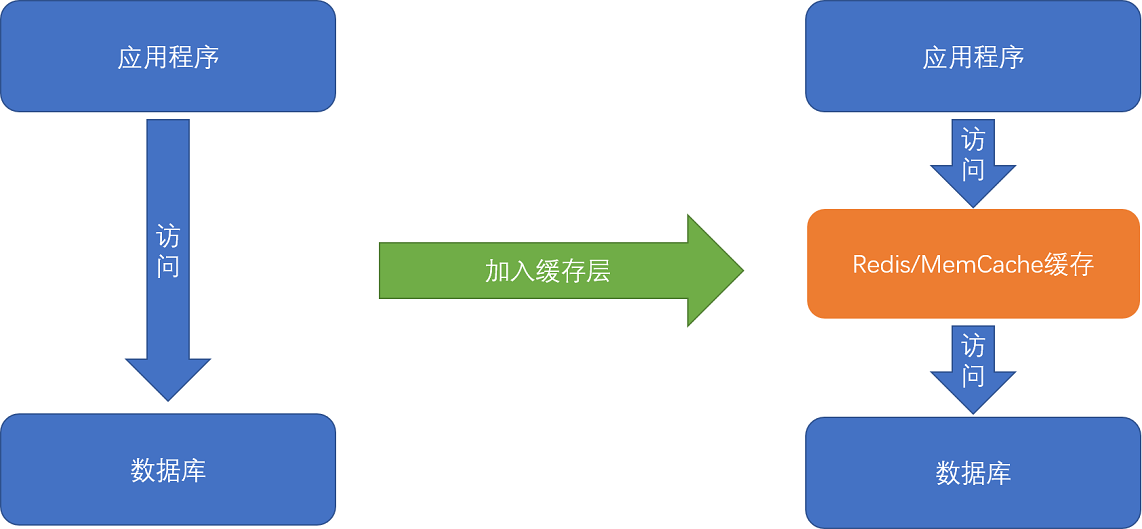
在数据库前添加数据缓存是常见的性能优化方式
那么,不知道你有没有想过,这种添加缓存的策略一定是有效的吗?或者说,这种策略在什么情况下是有效的呢?如果从理论角度去分析,
添加缓存一定是我们的最佳策略么?进一步地,如果我们对于访问性能的要求非常高,希望数据在1毫秒,乃至100微妙内完成处理,我们还能用这个添加缓存的策略么?
一、局部性原理
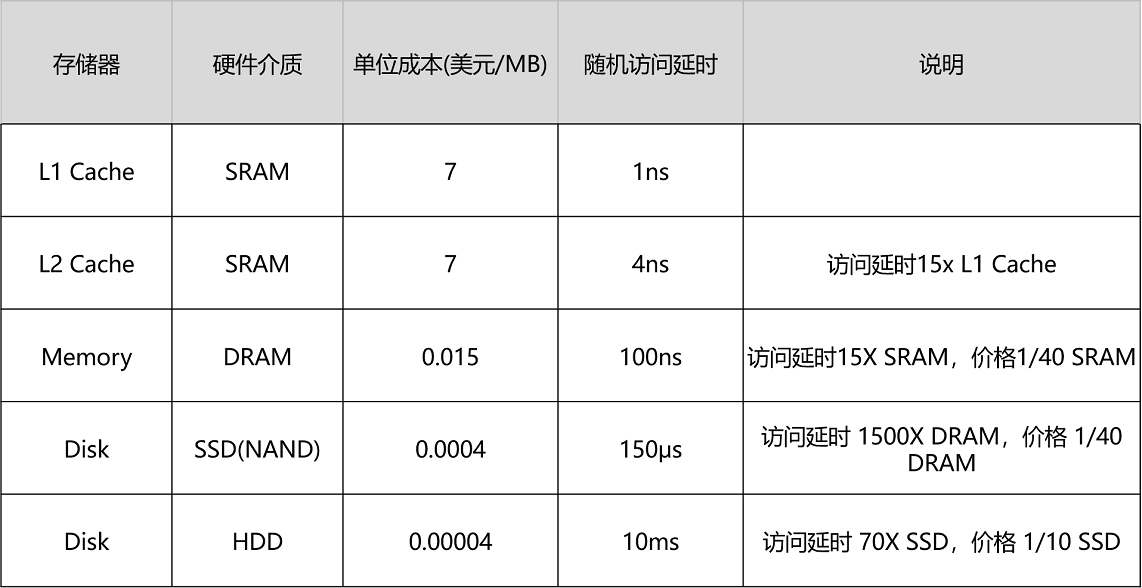
可以看到,不同的存储器设备之间,访问速度、价格和容量都有几十乃至上千倍的差异。
1、时间局部性
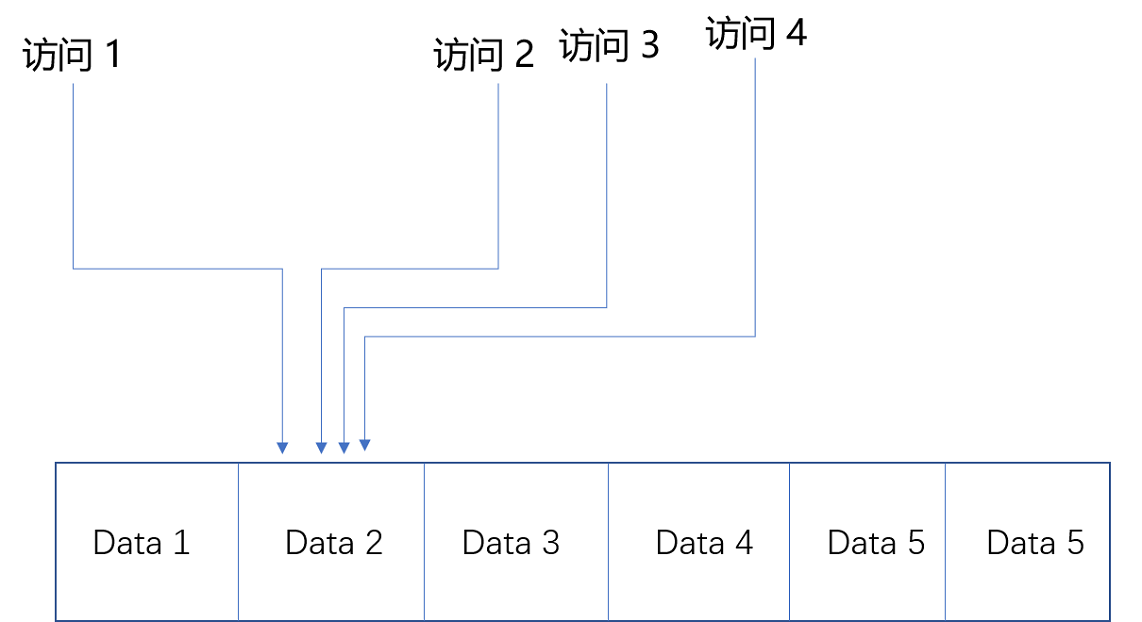
同一份数据在短时间内会反复多次被访问
2、空间局部性

相邻的数据会被连续访问

3、局部性和空间局部性实际在存储中的应用

二、具体案例分析过程
1、案例需求描述

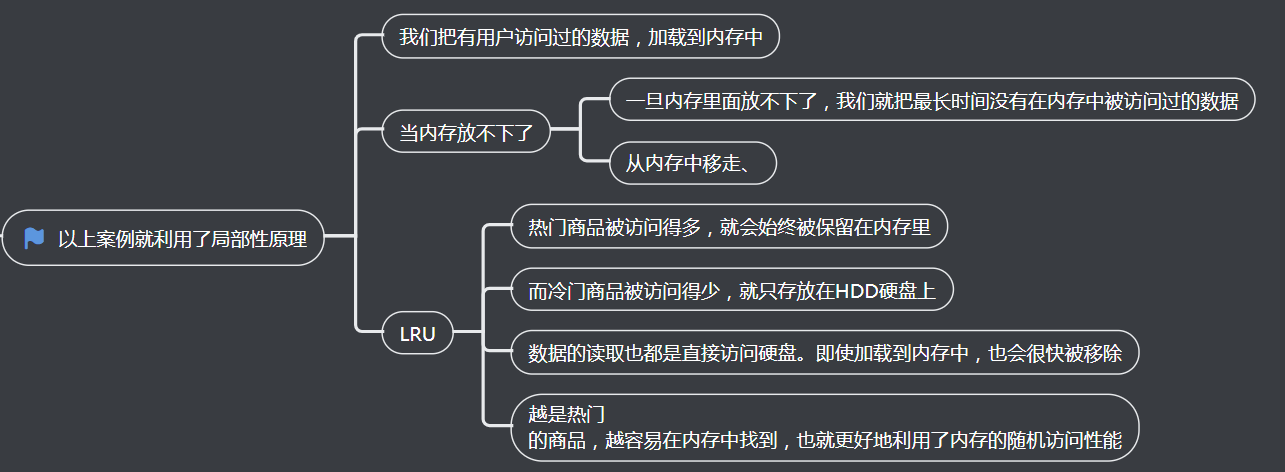
2、把数据放在内存

3、在内存里放前1%的热门商品

4、以上案例就利用了局部性原理
三、如何花最少的钱,装下亚马逊的所有商品?
1、痛点

2、内存的随机访问请求需要100ns

3、估算每天的活跃用户为1亿

4、缓存没有命中
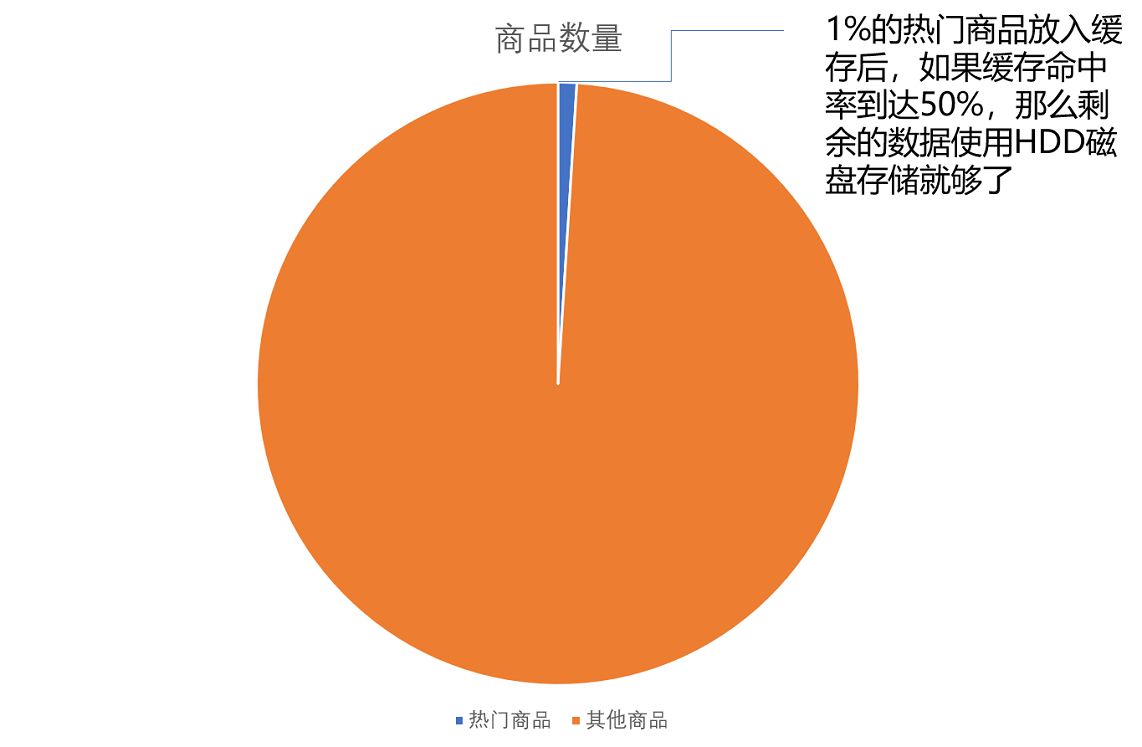

当然,这里我们只是一个简单的估算。在实际的应用程序中,查看一个商品的数据可能意味着不止一次的随机内存或者随机磁盘的访问。对应的数据存储空间也不止要考虑数据,
还需要考虑维护数据结构的空间,而缓存的命中率和访问请求也要考虑均值和峰值的问题。
通过这个估算过程,你需要理解,如何进行存储器的硬件规划。你需要考虑硬件的成本、访问的数据量以及访问的数据分布,然后根据这些数据的估算,来组合不同的存储器,
能用尽可能低的成本支撑所需要的服务器压力。而当你用上了数据访问的局部性原理,组合起了多种存储器,你也就理解了怎么基于存储器层次结构,来进行硬件规划了。
四、总结延伸
这一讲,我们讲解了计算机存储器层次结构中最重要的一个优化思路,就是局部性原理。
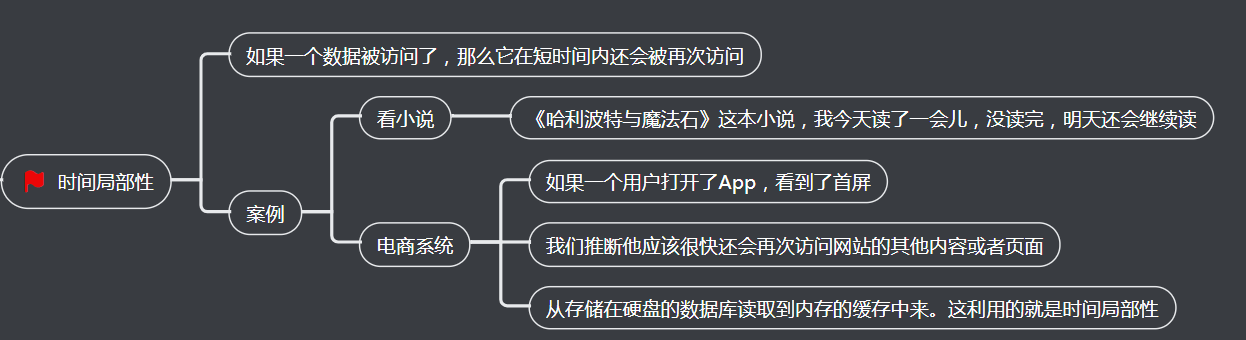
在实际的计算机日常的开发和应用中,我们对于数据的访问总是会存在一定的局部性。有时候,这个局部性是时间局部性,就是我们最近访问过的数据还会被反复访问。
有时候,这个局部性是空间局部性,就是我们而局部性的存在,使得我们可以在应用开发中使用缓存这个有利的武器。比如,通过将热点数据加载并保留在速度更快的存储设备里面,
在速度更快的存储设备里面,我们可以用更低的成本来支撑服务器。
通过亚马逊这个例子,我们可以看到,我们可以通过快速估算的方式,来判断这个添加缓存的策略是否能够满足我们的需求,以及在估算的服务器负载的情况下,
需要规划多少硬件设备。这个“估算+规划”的能力,是每一个期望成长为架构师的工程师,必须掌握的能力。
最后,回到这一讲的开头,我问了你这样一个问题,在遇到性能问题,特别是访问存储器的性能问题的时候,是否可以简单地添加一层数据缓存就能让问题迎刃而解呢?
今天这个亚马逊网站商品数据的例子,似乎给了我们一个“Yes”的答案。那么,这个答案是否放之四海皆准呢?后面的几讲,我们会深入各种应用场景,进一步来回答这个问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构