数据结构与算法之美学习笔记:第二十讲
一、LRU 缓存淘汰算法
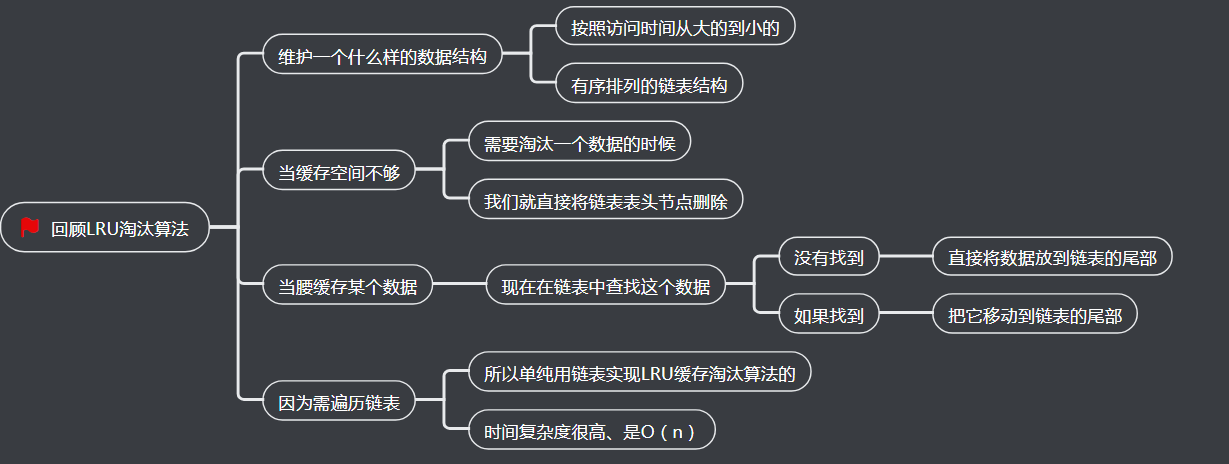
1、回顾LRU淘汰算法
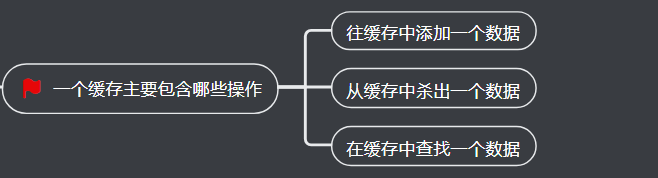
2、一个缓存主要包含哪些操作
3、单独使用链表和组合使用对比
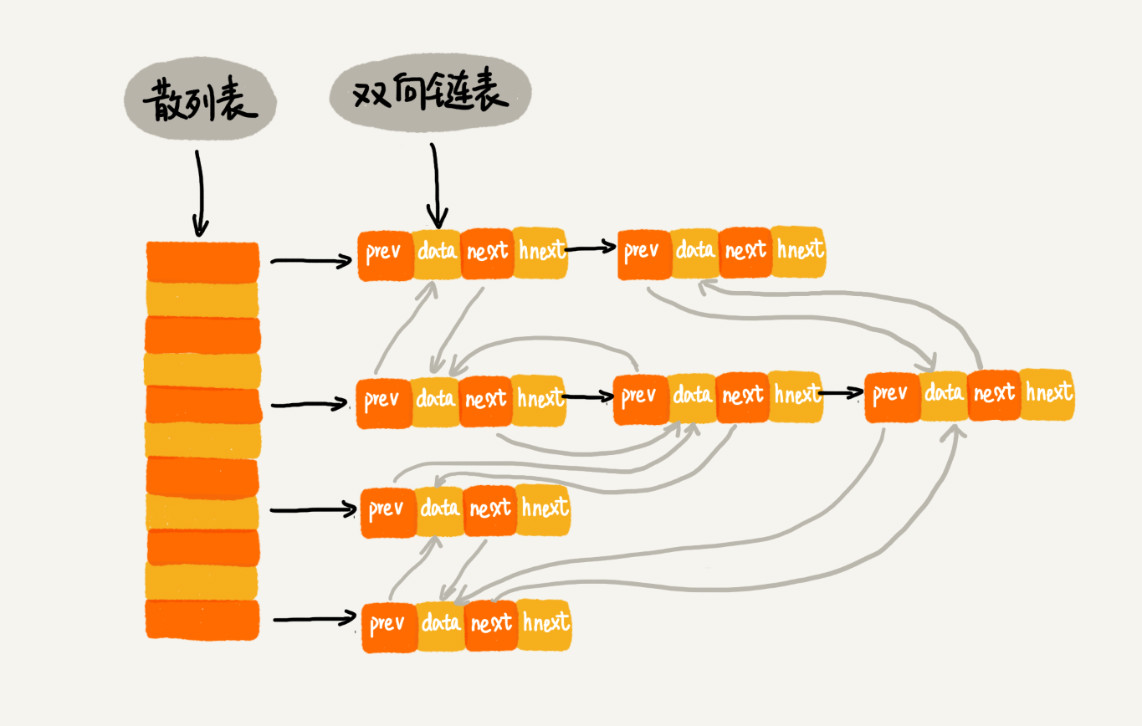

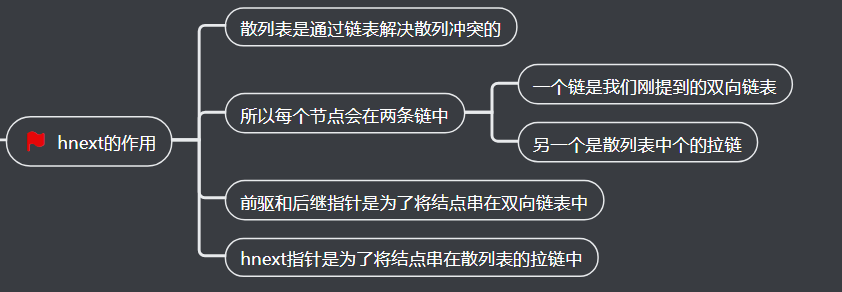
4、hnext的作用
5、如何把时间复杂度降到O(1)
在缓存中查找一个数据

从缓存中删除一个数据

往缓存中添加一个数据

二、Redis有序集合
1、有序集合
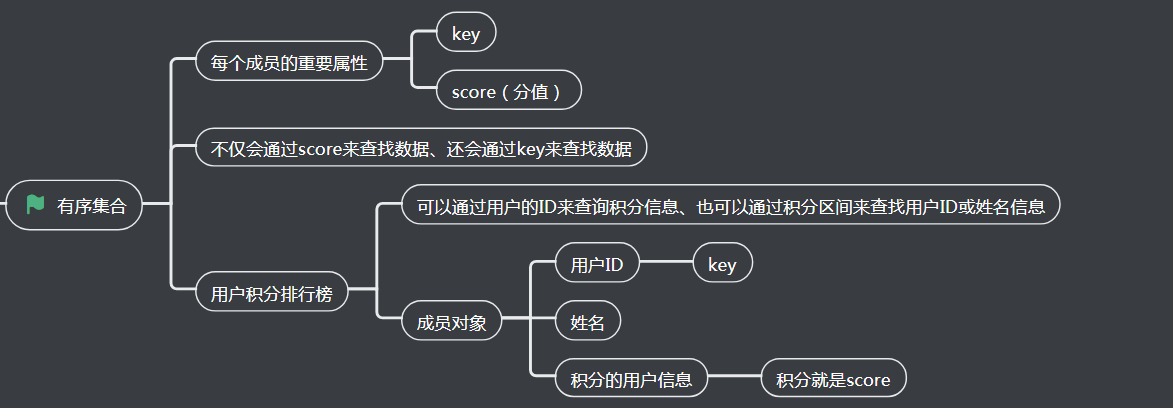
2、有序集合的操作

3、单独和组合使用比较

三、Java LinkedHashMap
如果你熟悉 Java,那你几乎天天会用到这个容器。我们之前讲HashMap 底层是通过散列表这种数据结构实现的。而 LinkedHashMap 前面比 HashMap 多了一Linked”,
这里的“Linked”是不是说,LinkedHashMap 是一个通过链表法解决散列冲突的散列表呢?
实际上,LinkedHashMap 并没有这么简单,其中的“Linked”也并不仅仅代表它是通过链表法解决散列冲突的。关于这一点,在我是初学者的时候,也误解了很久
我们先来看一段代码。你觉得这段代码会以什么样的顺序打印 3,1,5,2 这几个 key 呢?原因又是什么呢?
HashMap<Integer, Integer> m = new LinkedHashMap<>();
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
我先告诉你答案,上面的代码 会按照数据插入的顺序依次来打印,也就是说,打印顺序就是
,你有没有觉得奇怪?散列表中的数据是经过散列幻术打乱之后无规律存储的,
这里是如何实现按照数据的插入顺序来遍历数据,你可以看下面这段代码:
你可能已经猜到,也是通过散列表和链表组合在一起实现的,实际上,它不仅支持按照插入顺序遍历数据
还支持按照问顺序来遍历数据,你可以看下这段代码
// 10 是初始大小,0.75 是装载因子,true 是表示按照访问时间排序
HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
m.put(3, 26);
m.get(5);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
这段代码的结果是1,2,3,5我来抉剔分析一下,为什么这段代码会按照这样的顺序来打印
每次调用put()函数往 中添加数据的时候,都会将数据添加到链表的尾部,所以,在前四个操作完成之后,链表中的数据是下面这样的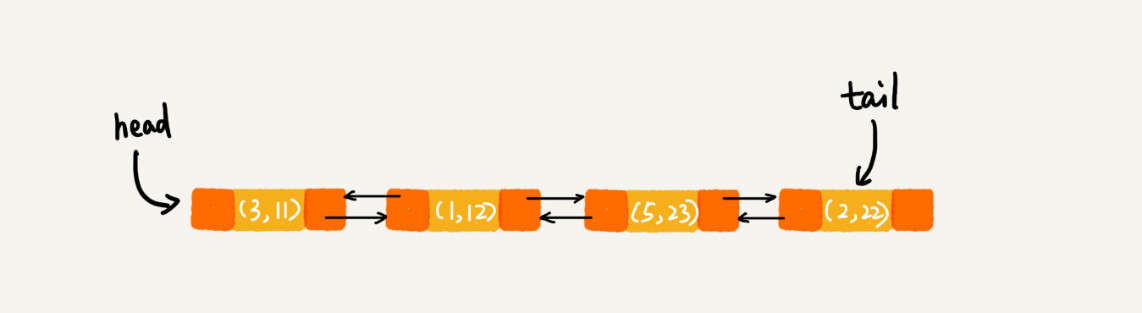
在第 8 行代码中,再次将键值为 3 的数据放入到 LinkedHashMap 的时候,会先查找这个键值是否已经有了,
然后,再将已经存在的 (3,11) 删除,并且将新的 (3,26) 放到链表的尾部。所以,这个时候链表中的数据就是下面这样:
当第 9 行代码访问到 key 为 5 的数据的时候,我们将被访问到的数据移动到链表的尾部。所以,第 9 行代码之后,链表中的数据是下面这样:
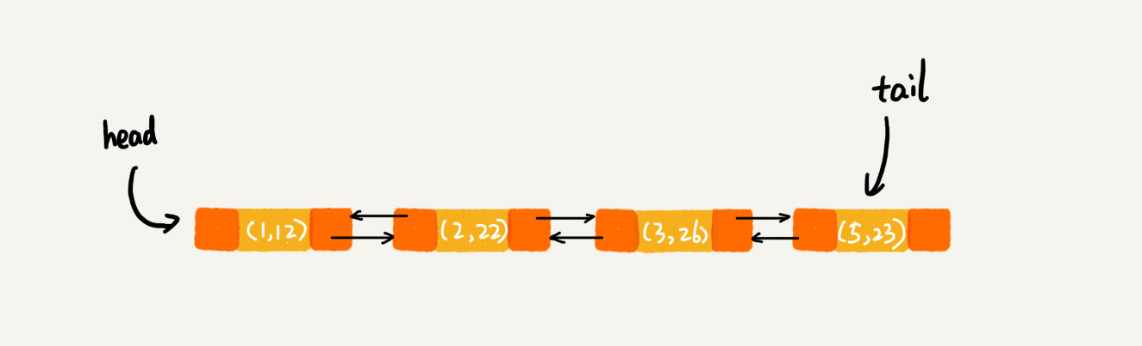
所以,最后打印出来的数据是1,2,3,5从上面的分析,你有没有发现,按照访问时间排序的,本身就是一个支持淘汰策略的缓存系统?实际上,
他们两个的实现原理也是一模一样的,我也就不再啰嗦了
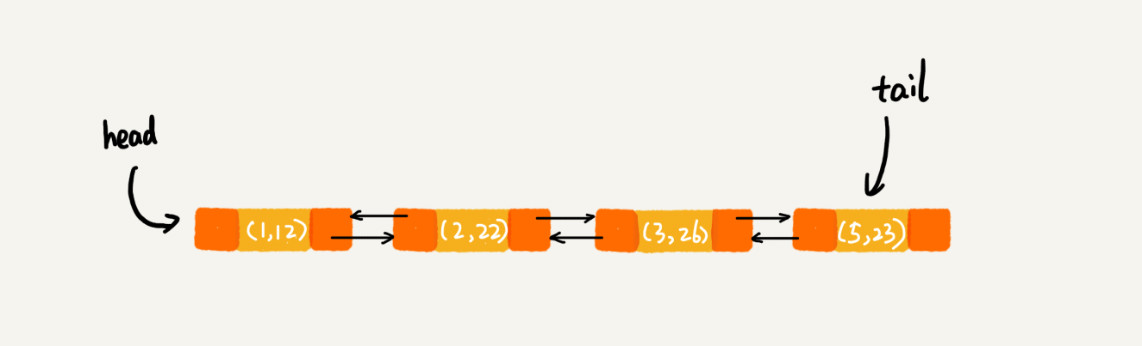
我现在来总结一下,实际上,LinkedHashMap 是通过双向链表和散列表这两种数据结构组合实现的LinkedHashMap 中的“Linked”实际上是指的双向链表,并非指用链表法解决散列冲突
四、解答开篇 & 内容小结
1、散列表
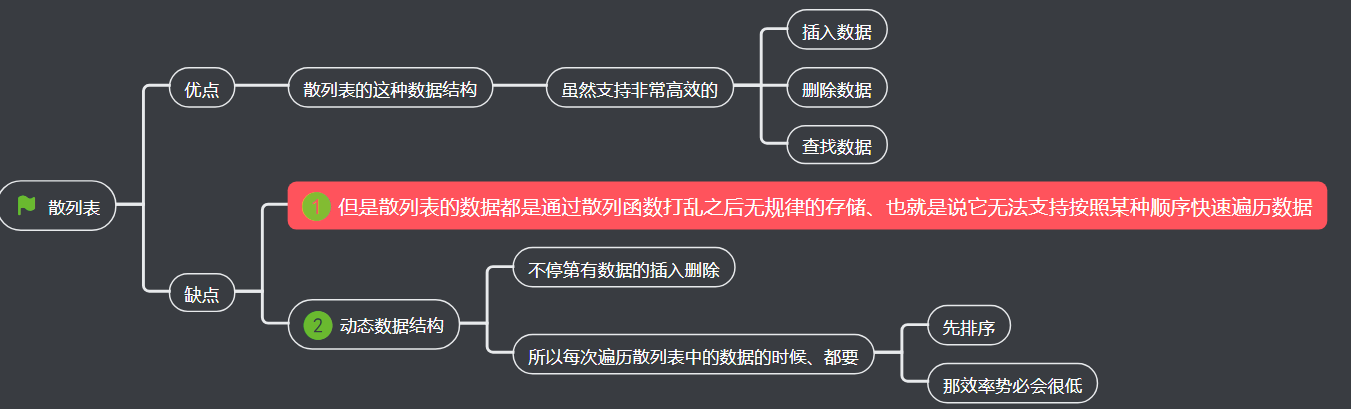
2、组合使用

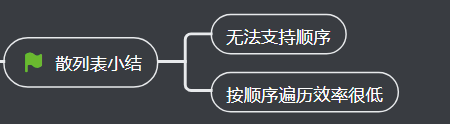
3、散列表小结