数据结构与算法之美学习笔记:第十九讲
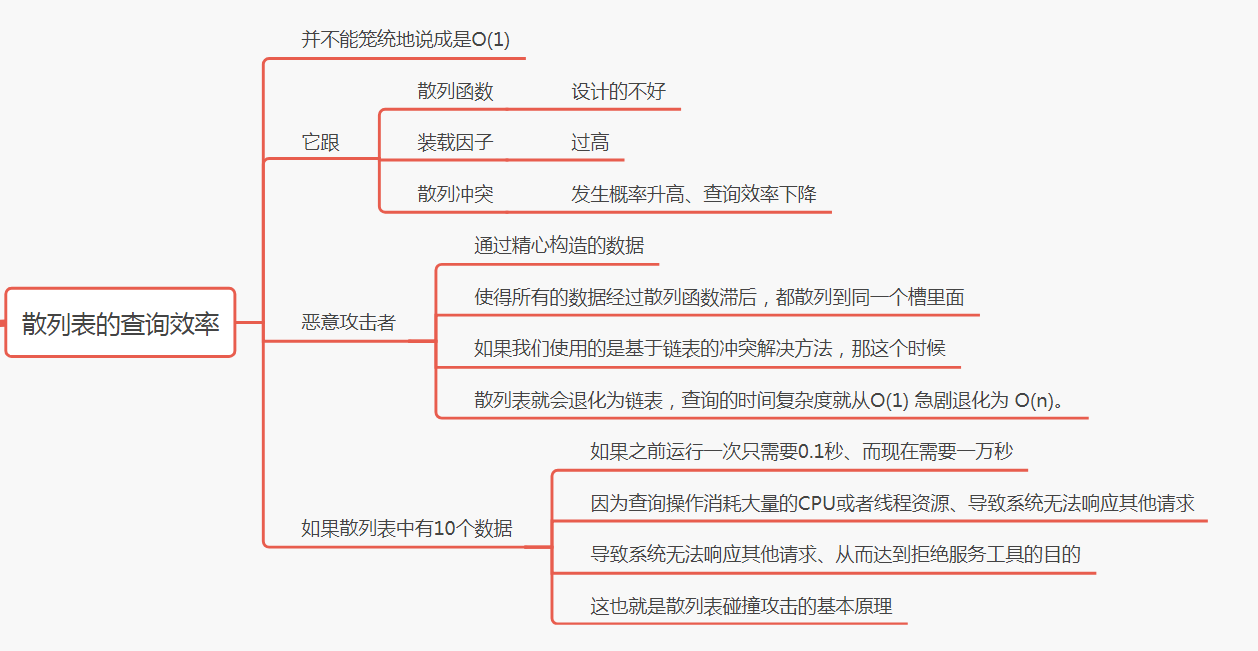
通过上一节的学习,我们知道,散列表的查询效率并不能笼统地说成是O(1)。它跟散列函数、装载因子、散列冲突等都有关系。如果散列函数设计得不好,
或者装载因子过大,都可能导致散列冲突发生的概率升高,查询效率下降。
在极端情况下,有些恶意的攻击者,还有可能通过精⼼构造的数据,使得所有的数据经过散列函数之后,都散列到同一个槽里。如果我们使用的是基于链表的冲突解决冲法,
那这个时候,散列表就会退化为链表,查询的时间复杂度就从O(1)急剧退化为O(n)。
如果散列表中有10万个数据,退化后的散列表查询的效率就下降了10万倍。更直接点说,如果之前运⾏100次查询只需要0.1秒,那现在就需要1万秒。
这样就有可能因为查询操作消耗耗量CPU或者线程资源,导致系统无法响应其他请求,从而达到拒绝服务攻击(DoS)的⽬的。这也就是散列表碰撞攻击的基本原理
今天,我们就来学习一下,如何设计一个可以应对各种异常情况的⼯业级散列表,来避免在散列冲突的情况下,散列表性能的急剧下降,并且能抵抗散列碰撞攻击?
一、散列表的查询效率
二、如何设计散列函数
1、散列函数的设计不能太复杂

2、散列函数生成的值要尽可能随机并且均匀分布

3、散列函数的设计方法

三、装载因子过大了怎么办
1、会有什么后果

2、数据集合

3、动态散列表

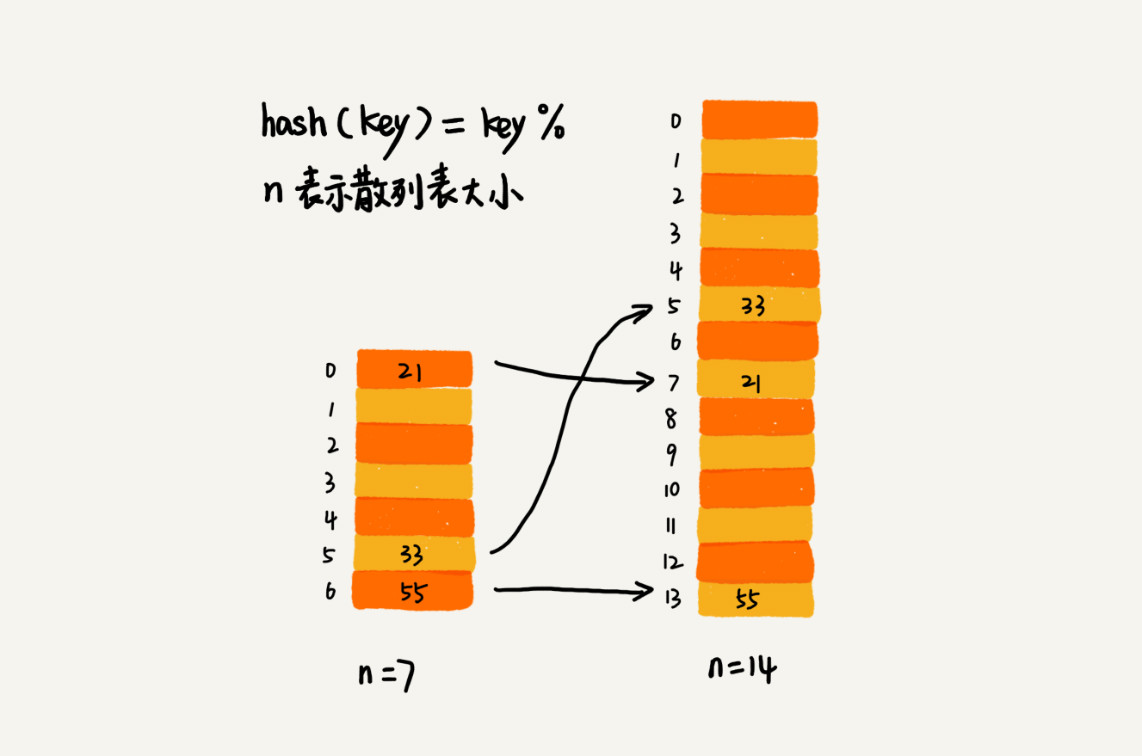
4、动态扩容
1、方法

2、存在的问题

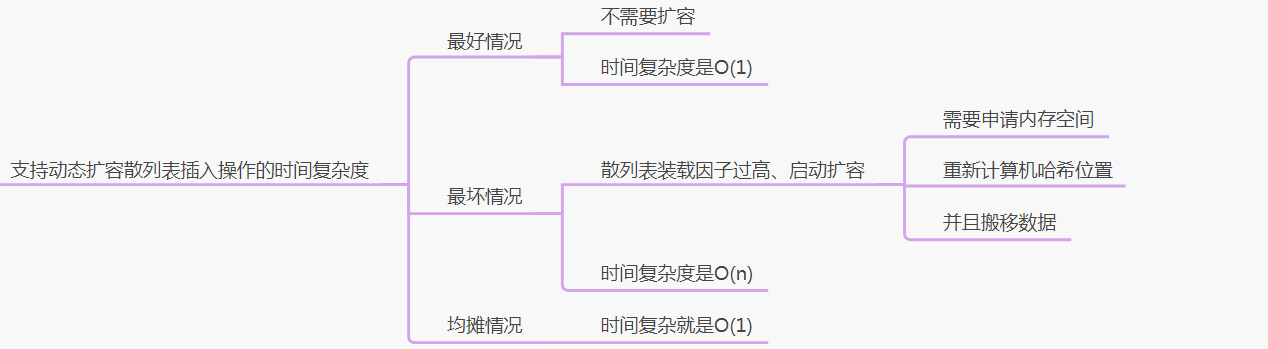
3、支持动态扩容散列表插入操作的时间复杂度
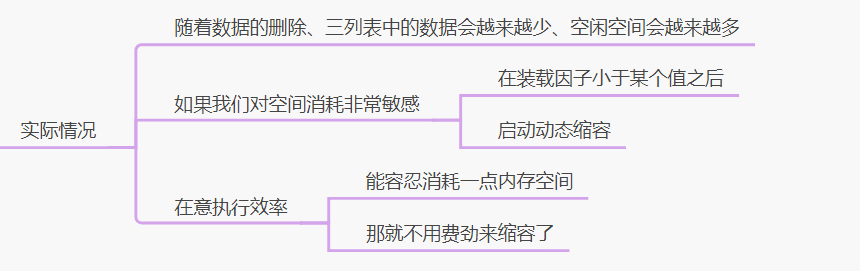
4、实际情况
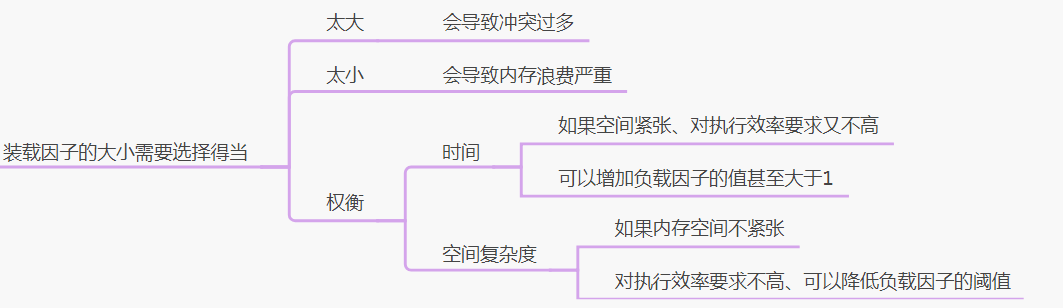
5、装载因子的大小需要选择得当
四、如何避免低效地扩容
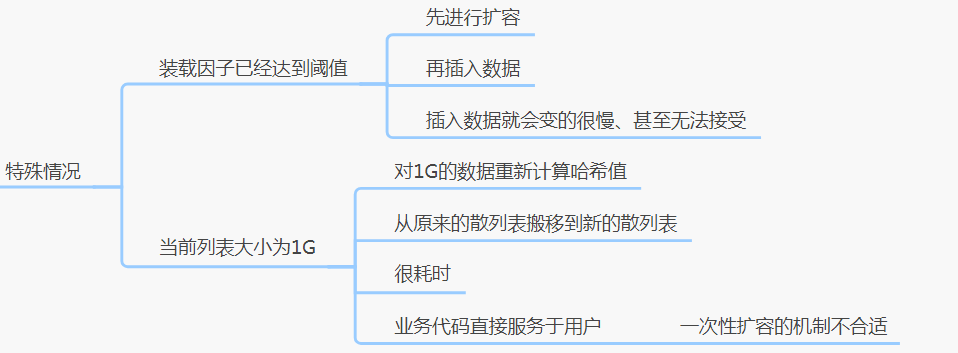
1、正常情况

2、特殊情况
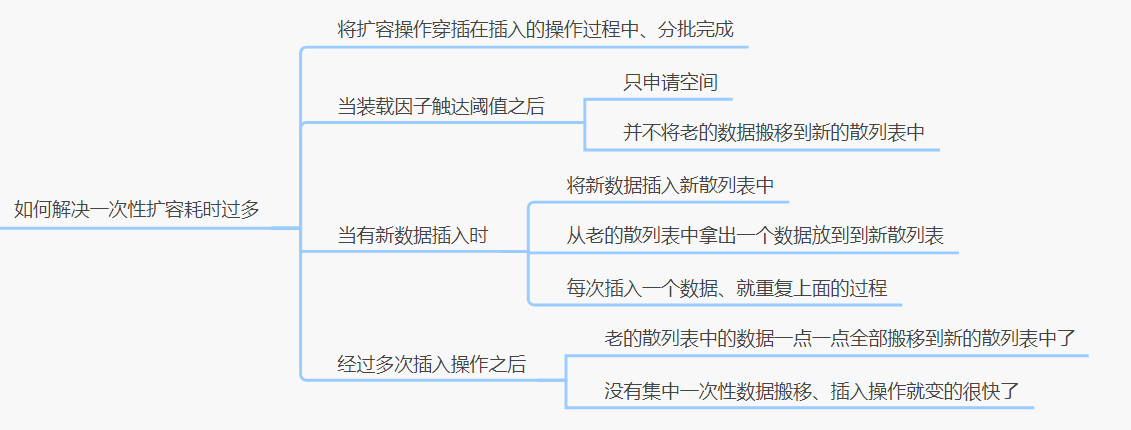
3、如何解决一次性扩容耗时过多

4、多次插入期间查询操作如何处理

五、如何选择冲突解决方法
1、实际的软件开发中常用

2、开放寻址法
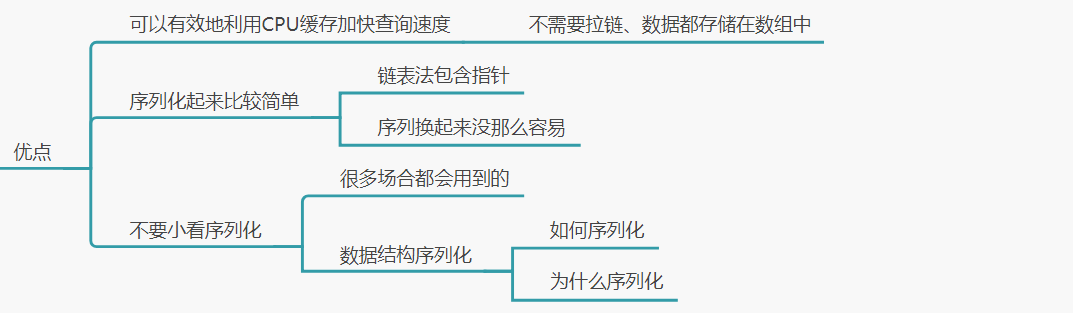
1、优点
2、缺点

3、总结

3、链表法
1、优点

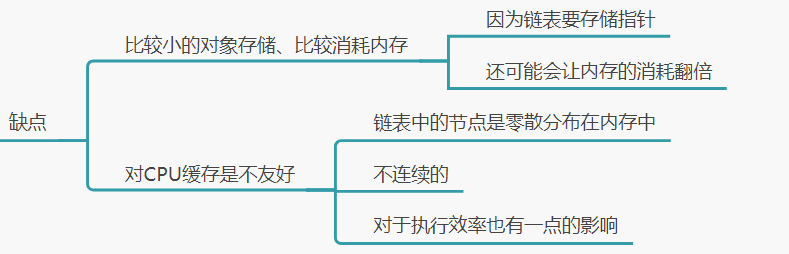
2、缺点
3、实际应用

4、总结
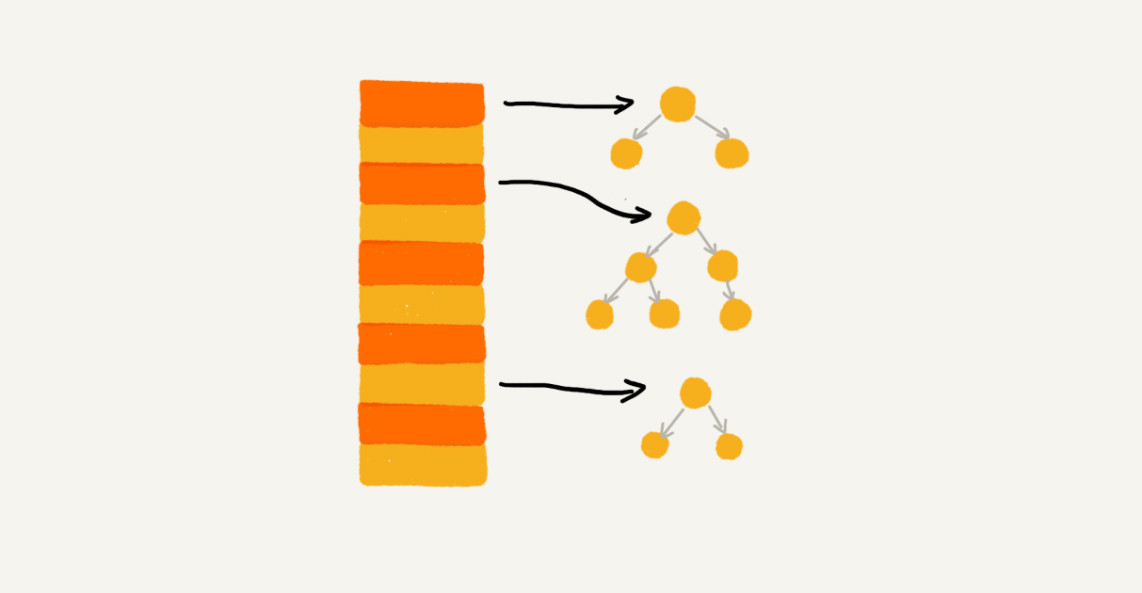

六、工业级散列表举例分析
1、初试大小

2、装载因子和动态扩容

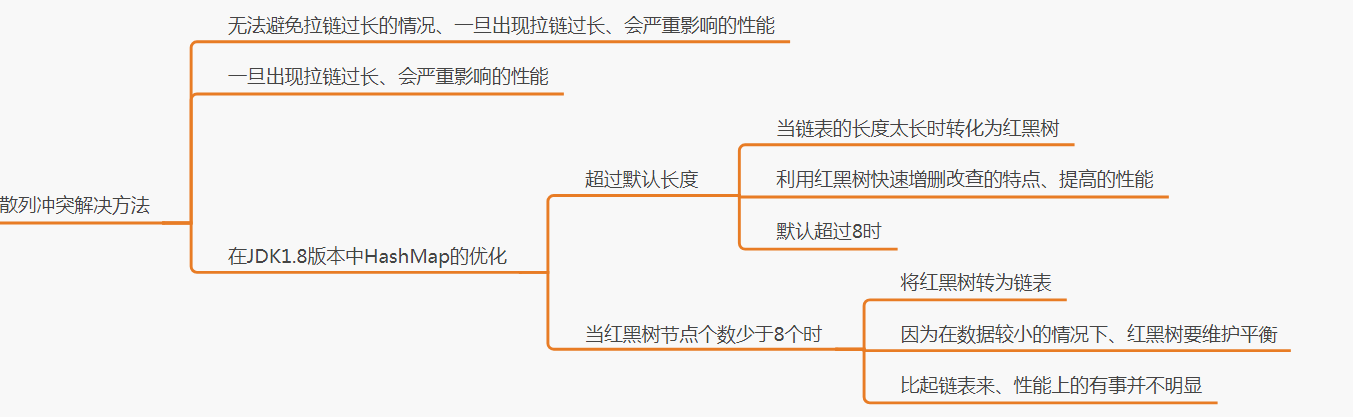
3、散列冲突解决方法
4、散列函数

其中,hashCode()返回的是Java对象的hash code。比如String类型的对象的hashCode()就是下面这样:
public int hashCode() {
int var1 = this.hash;
if(var1 == 0 && this.value.length > 0) {
char[] var2 = this.value;
for(int var3 = 0; var3 < this.value.length; ++var3) {
var1 = 31 * var1 + var2[var3];
}
this.hash = var1;
}
return var1;
}
七、解答开篇

作者:罗阿红
出处:http://www.cnblogs.com/luoahong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号