Linux性能优化实战学习笔记:第二十六讲
一、案例环境描述
1、环境准备
2CPU,4GB内存
预先安装docker sysstat工具
2、温馨提示
案例中 Python 应用的核心逻辑比较简单,你可能一眼就能看出问题,但实际生产环境中的源码就复杂多了。所以,
我依旧建议,操作之前别看源码,避免先入为主,要把它当成一个黑盒来分析。这样 你可以更好把握住,怎么从系统的资源使用问题出发,分析出瓶颈
所在的应用,以及瓶颈在应用中大概的位置
3、应用环境
1、运行目标应用
1 | docker run -v /tmp:/tmp --name=app -itd feisky/logapp |
2、确认应用正常启动
1 2 | ps -ef | grep /app.py root 18940 18921 73 14:41 pts/0 00:00:02 python /app.py |
二、故障现象
1、发现故障
1 2 3 4 5 6 7 8 9 10 11 12 | # 按 1 切换到每个 CPU 的使用情况 $ toptop - 14:43:43 up 1 day, 1:39, 2 users, load average: 2.48, 1.09, 0.63 Tasks: 130 total, 2 running, 74 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.7 us, 6.0 sy, 0.0 ni, 0.7 id, 92.7 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 92.3 id, 7.3 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8169308 total, 747684 free, 741336 used, 6680288 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 7113124 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 18940 root 20 0 656108 355740 5236 R 6.3 4.4 0:12.56 python 1312 root 20 0 236532 24116 9648 S 0.3 0.3 9:29.80 python3 |
千万记得一定要用机械硬盘
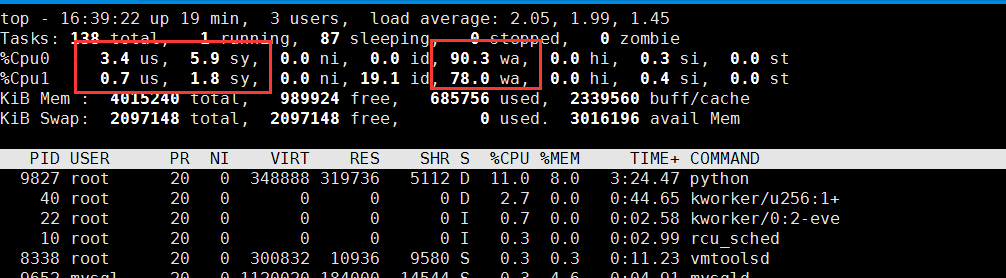
2、性能现象
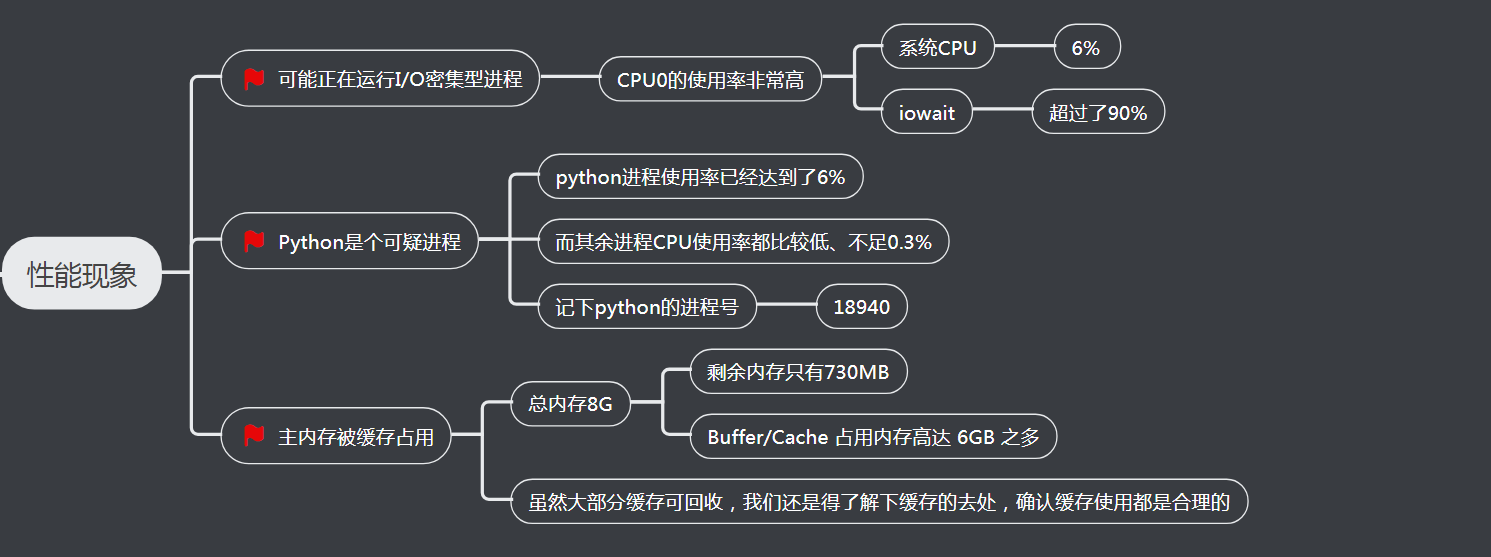
三、分析过程
1、iowait超过了90%分析
查看I/O使用情况
1 2 3 4 5 6 | # -d 表示显示 I/O 性能指标,-x 表示显示扩展统计(即所有 I/O 指标) $ iostat -x -d 1 Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 64.00 0.00 32768.00 0.00 0.00 0.00 0.00 0.00 7270.44 1102.18 0.00 512.00 15.50 99.20 |
实际测试截图

观测结果分析
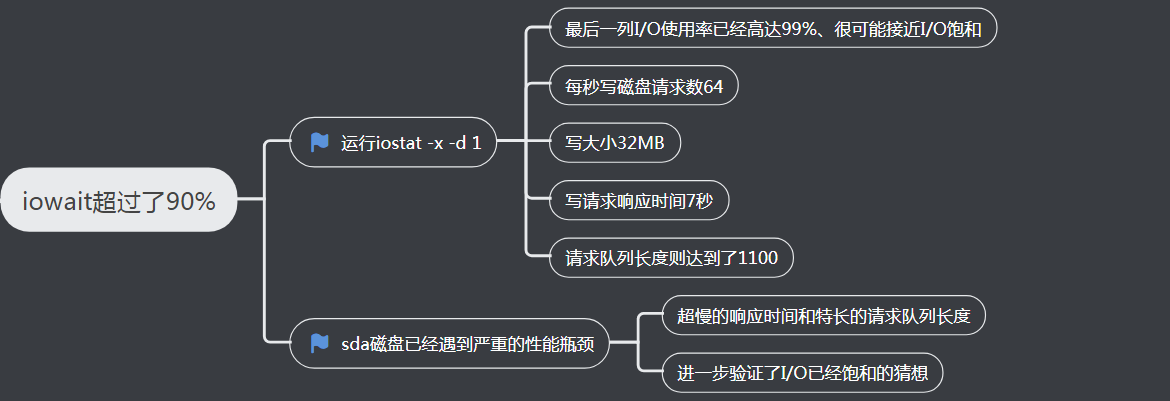
2、pidstat分析python进程
1、观察进程I/O使用情况
1 2 3 4 5 6 7 8 9 | pidstat -d 1 15:08:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 15:08:36 0 18940 0.00 45816.00 0.00 96 python 15:08:36 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 15:08:37 0 354 0.00 0.00 0.00 350 jbd2/sda1-815:08:37 0 18940 0.00 46000.00 0.00 96 python 15:08:37 0 20065 0.00 0.00 0.00 1503 kworker/u4:2 |
2、实际测试截图

3、pidstat结果观测分析
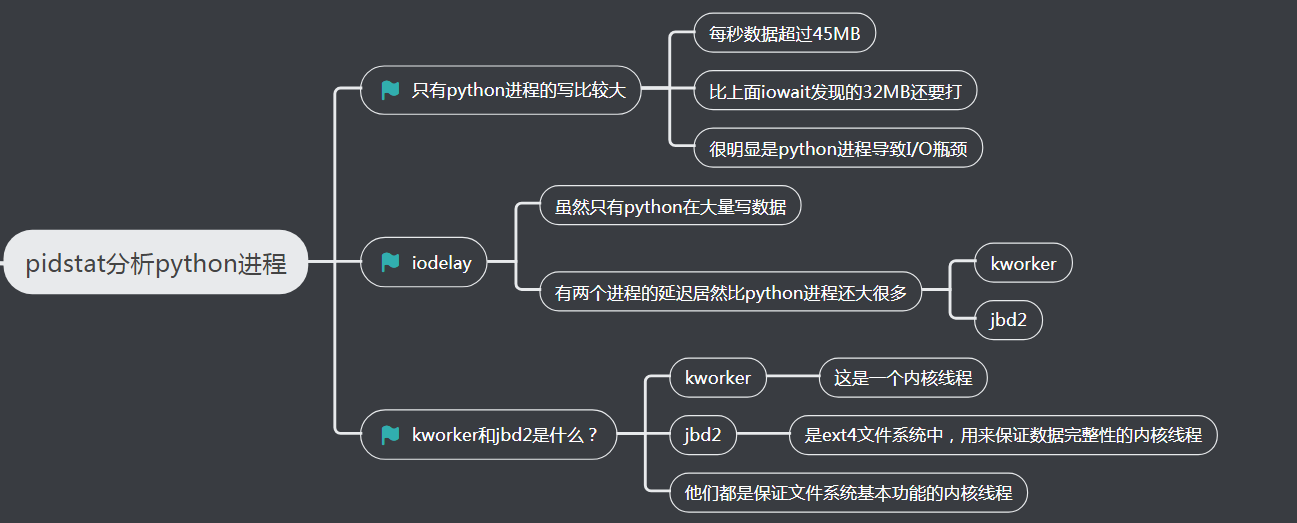
实际测试说明
1、io使用没有达到90%,而实际测试是14.9(最高)
2、每秒的写请求是64,而实际测试是85
3、写大小32MB,而实际测试是107MB
4、请求队列是1100而实际测试是23.93
3、strace分析python进程调用
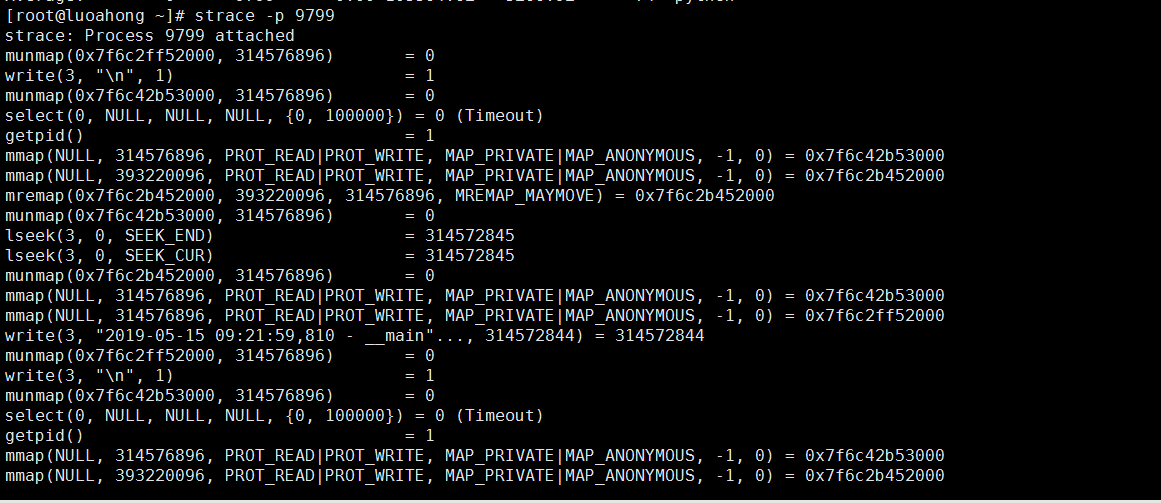
1、strace查看指定PID调用情况
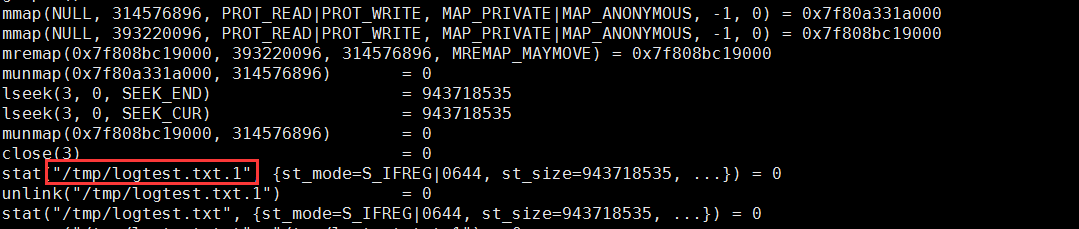
1 2 3 4 5 6 7 8 9 10 11 12 | strace -p 18940 strace: Process 18940 attached ...mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f7aee9000 mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f682e8000 write(3, "2018-12-05 15:23:01,709 - __main"..., 314572844 ) = 314572844 munmap(0x7f0f682e8000, 314576896) = 0 write(3, "\n", 1) = 1 munmap(0x7f0f7aee9000, 314576896) = 0 close(3) = 0 stat("/tmp/logtest.txt.1", {st_mode=S_IFREG|0644, st_size=943718535, ...}) = 0 |
2、实际测试截图:机械硬盘 centos
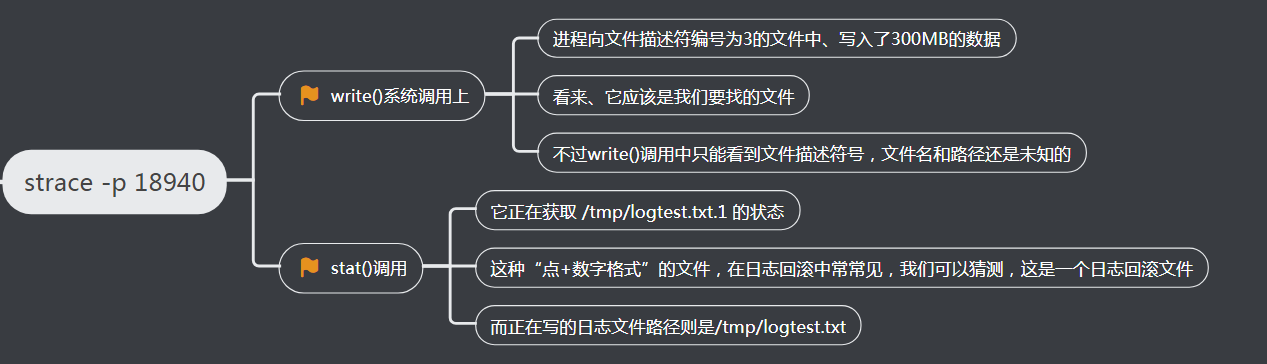
3、strace结果观测分析
4、lsof查看python进程打开了那些文件
1、查看进程打开了那些文件
1 2 3 4 5 6 7 | lsof -p 18940 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME python 18940 root cwd DIR 0,50 4096 1549389 / python 18940 root rtd DIR 0,50 4096 1549389 / … python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt |
2、实际测试截图
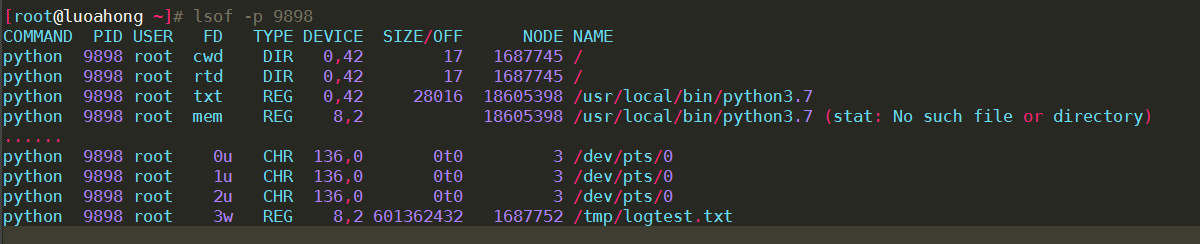
3、lsof输出观测分析

3、查看源代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # 拷贝案例应用源代码到当前目录$ docker cp app:/app.py . # 查看案例应用的源代码$ cat app.py logger = logging.getLogger(__name__) logger.setLevel(level=logging.INFO) rHandler = RotatingFileHandler("/tmp/logtest.txt", maxBytes=1024 * 1024 * 1024, backupCount=1) rHandler.setLevel(logging.INFO) def write_log(size): '''Write logs to file''' message = get_message(size) while True: logger.info(message) time.sleep(0.1) if __name__ == '__main__': msg_size = 300 * 1024 * 1024 write_log(msg_size) |
继续查看源码
1 2 3 4 5 6 7 8 9 10 | def set_logging_info(signal_num, frame): '''Set loging level to INFO when receives SIGUSR1''' logger.setLevel(logging.INFO) def set_logging_warning(signal_num, frame): '''Set loging level to WARNING when receives SIGUSR2''' logger.setLevel(logging.WARNING) signal.signal(signal.SIGUSR1, set_logging_info) signal.signal(signal.SIGUSR2, set_logging_warning) |
分析这个源码,我们发现,它的日志路径是/tmp/logtest.txt、默认记录 INFO 级别以上的所有日志,而且每次写日志的大小是 300MB。这跟我们上面的分析结果是一致的
四、解决方案
1、运行kill命令给进程发SIGUSR2 信号
1 | kill -SIGUSR2 18940 |
2、再执行top和iostat观察
top
1 2 3 | top... %Cpu(s): 0.3 us, 0.2 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st |
iowat
1 2 3 4 5 | iostat -d -x 1Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
到这里,我们不仅定位了狂打日志的应用程序,并通过调用高日志级别的方法,完美解决了I/O的性能瓶颈
五、小结
日志,是了解应用程序内部运行情况、最常用、也最高效的工具、无论是操作系统、还是应用程序、都会记录大量的运行日志,以便时候查看历史记录,
这些日志一般按照不同的级别来开启,比如,开发环境通常打开调式级别的日志,而线上环境则只记录警告和错误日志
在排查应用程序问题时,我们可以能需要,在线上环境临时开启应用程序的调试日志,有时候,事后一不小心忘了调回去,没把线上的日志调高到警告级别,
可能会导致cpu使用率、磁盘I/O等一系列的性能问题,严重时,甚至会影响同一台服务器上运行的其他应用程序
今后,在碰到这种“狂打日志”的场景时,你可以用iostat、strace、losf等工具来定位狂打日志的进程,找出相应的日志文件,再通过应用程序接口
调整日志界别来解决问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构