Linux性能优化实战学习笔记:第六讲
一、环境准备
1、安装软件包
终端1
机器配置:2 CPU,8GB 内存 预先安装 docker、sysstat、perf等工具
1 2 3 4 | [root@luoahong ~]# docker -vDocker version 18.09.1, build 4c52b90[root@luoahong ~]# rpm -qa|grep sysstatsysstat-12.1.2-1.x86_64 |
终端2
机器配置:1 CPU,2GB 内存 预先安装ab 等工具
1 2 3 4 5 | [root@nfs ~]#yum -y install httpd-tools [root@nfs ~]# ab -VThis is ApacheBench, Version 2.3 <$Revision: 1430300 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/ |
2、实战拓谱图
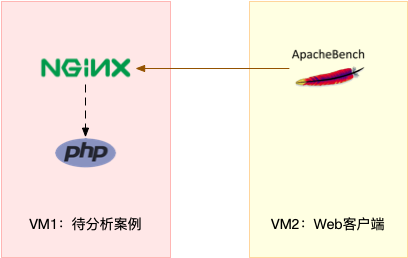
3、环境模拟
终端一
1 2 | docker run --name nginx -p 10000:80 -itd feisky/nginx:sp$ docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp |
终端二
测试nginx是否启动
1 2 3 | # 192.168.118.97 是第一台虚拟机的 IP 地址$ curl http://192.168.118.97:10000/It works! |
性能测试
1 2 3 4 5 6 7 8 | # 并发 100 个请求测试 Nginx 性能,总共测试 1000 个请求$ ab -c 100 -n 1000 http://192.168.118.97:10000/This is ApacheBench, Version 2.3 <$Revision: 1706008 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, ...Requests per second: 87.86 [#/sec] (mean)Time per request: 1138.229 [ms] (mean)... |
继续压力测试
1 | ab -c 5 -t 600 http://192.168.118.97:10000/ |
二、定位问题(top、pidstat、ps)
1、top定位

2、pidstat定位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | [root@luoahong ~]# pidstat 1Linux 3.10.0-957.5.1.el7.x86_64 (luoahong) 05/04/2019 _x86_64_ (2 CPU)03:41:55 PM UID PID %usr %system %guest %wait %CPU CPU Command03:41:56 PM 0 3 0.00 2.94 0.00 0.00 2.94 0 ksoftirqd/003:41:56 PM 0 9 0.00 6.86 0.00 27.45 6.86 0 rcu_sched03:41:56 PM 0 14 0.00 15.69 0.00 9.80 15.69 1 ksoftirqd/103:41:56 PM 0 7500 4.90 2.94 0.00 0.98 7.84 0 vmtoolsd03:41:56 PM 0 9451 0.00 1.96 0.00 0.00 1.96 1 dockerd03:41:56 PM 27 9928 0.00 0.98 0.00 0.00 0.98 0 mysqld03:41:56 PM 0 10133 0.98 0.00 0.00 0.00 0.98 1 containerd-shim03:41:56 PM 0 10804 0.00 0.98 0.00 4.90 0.98 1 kworker/1:003:41:56 PM 0 10835 0.98 3.92 0.00 0.00 4.90 1 containerd-shim03:41:56 PM 101 10891 0.00 5.88 0.00 15.69 5.88 0 nginx03:41:56 PM 1 84378 0.98 2.94 0.00 3.92 3.92 0 php-fpm03:41:56 PM 1 84388 0.00 1.96 0.00 3.92 1.96 1 php-fpm03:41:56 PM 1 84395 0.98 0.98 0.00 4.90 1.96 1 php-fpm03:41:56 PM 1 84411 0.00 0.98 0.00 3.92 0.98 0 php-fpm03:41:56 PM 1 84413 0.00 1.96 0.00 8.82 1.96 1 php-fpm03:41:56 PM 0 102735 0.00 0.98 0.00 0.00 0.98 1 pidstat |
3、top再次定位
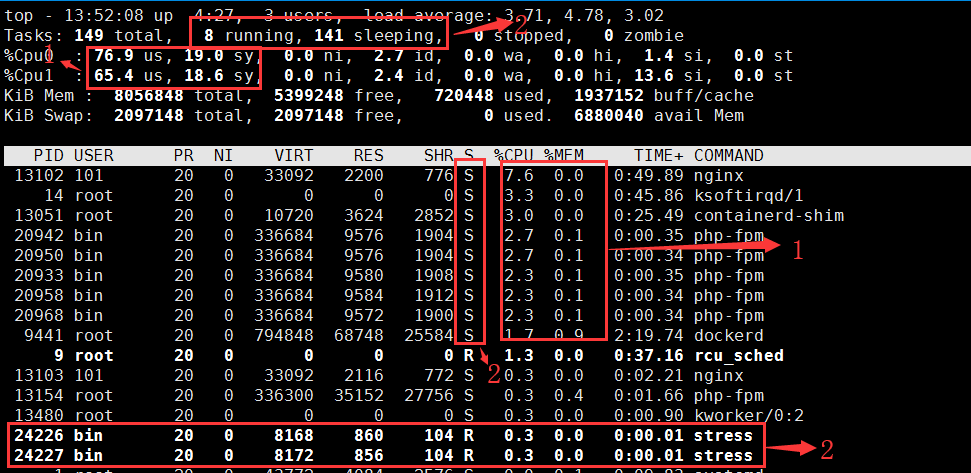
你有没有发现,nginx和所有的PHP-FPM都处于sleep状态,二真正处于Running(R)状态的,却是几个 stress 进程,这几个stree比较奇怪,需要我们做进一步的分析
4、pidstat再次定位
1 2 3 4 | [root@luoahong perf-tools]# pidstat -p 24226Linux 3.10.0-957.5.1.el7.x86_64 (luoahong) 05/04/2019 _x86_64_ (2 CPU)03:47:45 PM UID PID %usr %system %guest %wait %CPU CPU Command |
奇怪、居然没有任何输出。难道是pidstat命令出问题了吗?在怀疑西能工具出问题前,最好还是先用其他工具交叉确认一下
5、ps定位
1 2 | [root@luoahong perf-tools]# ps aux|grep 24226root 66566 0.0 0.0 112708 980 pts/0 S+ 15:46 0:00 grep --color=auto 24226 |
还是没有输出,现在终于发现问题,原来这个进程已经不存在了,所以pidstat就没有任何输出,既然进程都没了
那西能问题应该跟着没了吧。我们在top命令确认一下;
1 2 3 4 5 6 7 8 9 10 11 | top...%Cpu(s): 80.9 us, 14.9 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6882 root 20 0 12108 8360 3884 S 2.7 0.1 0:45.63 docker-containe 6947 systemd+ 20 0 33104 3764 2340 R 2.7 0.0 0:47.79 nginx 3865 daemon 20 0 336696 15056 7376 S 2.0 0.2 0:00.15 php-fpm 6779 daemon 20 0 8184 1112 556 R 0.3 0.0 0:00.01 stress... |
可是,刚刚看到的stree进程不存在了,怎么还在运行呢?原来这次stree进程的pid跟前面不一样了,原来的pid不见了现在的是6779
进程的 PID 在变,这说明什么呢?在我看来要么是这些进程在不停地重启,要么就是全新的进程,这无非也就两个原因
第一原因:进程在不停地崩溃重启,比如因为段错误、配置错误等等这时,进程在退出后可能又被监控系统自动重启了。
第二原因:这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现(上面的案例,我们碰巧发现了)
6、用pstree | grep [xx],这样定位到具体的调用方法里。
1 2 3 | [root@luoahong ~]# pstree | grep stress | | | |-2*[php-fpm---sh---stress---stress] | | | |-php-fpm---sh---stress |
三、定位到具体的代码
1、用grep [xx] -r [项目文件]
查找是不是代码在调用stree命令
1 2 3 4 5 6 7 | # 拷贝源码到本地$ docker cp phpfpm:/app .# grep 查找看看是不是有代码在调用 stress 命令$ grep stress -r appapp/index.php:// fake I/O with stress (via write()/unlink()).app/index.php:$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status); |
2、找到具体代码位置
找到了,果然是app/index.php
1 2 3 4 5 6 7 8 9 10 11 | cat app/index.php<?php// fake I/O with stress (via write()/unlink()).$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) { echo "Server internal error: "; print_r($output);} else { echo "It works!";}?> |
3、给请求加入 verbose=1 参数后,就可以查看 stress的输出
1 2 3 4 5 6 7 8 9 10 | [root@nfs ~]# curl http://192.168.118.97:10000/?verbose=1Server internal error: Array( [0] => stress: info: [103660] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd [1] => stress: FAIL: [103661] (563) mkstemp failed: Permission denied [2] => stress: FAIL: [103660] (394) <-- worker 103661 returned error 1 [3] => stress: WARN: [103660] (396) now reaping child worker processes [4] => stress: FAIL: [103660] (400) kill error: No such process [5] => stress: FAIL: [103660] (451) failed run completed in 0s) |
从这里我们可以猜测,正式由于权限错误,大量的stress进程在启动是初始化失败,进而导致用户CPU使用率的升高
4、perf验证定位是否准确
1、perf record -g 记录
1 2 3 | perf record -g docker cp perf.data phpfpm:/tmpdocker exec -i -t phpfpm bash |
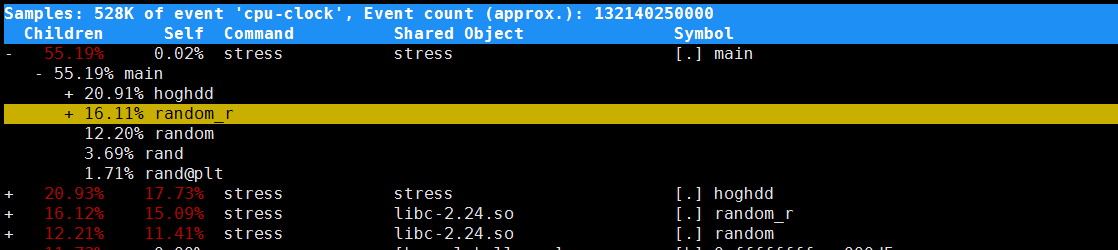
2、 用perf report查看是否可以定位到问题
1 2 3 | cd /tmp/apt-get update && apt-get install -y linux-perf linux-tools procpsperf_4.9 report |
四、execsnoop和实验过程中遇到的问题
1、execsnoop查看短时进程详细信息
execsnoop 就是一个专为短时进程设计的工具它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,
包括进程 PID、父进程 PID、命令行参数以及执行的结果。
用 execsnoop 监控上述案例,就可以直接得到 strress 进程的父进程 PID 以及它的命令行参数,并可以发现大量的 stress 进程在不停启动:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | git clone --depth 1 https://github.com/brendangregg/perf-toolscd perf-tools/[root@luoahong perf-tools]# ./bin/execsnoopTracing exec()s. Ctrl-C to end.Instrumenting sys_execve PID PPID ARGS 70342 70322 gawk -v o=1 -v opt_name=0 -v name= -v opt_duration=0 [...] 70344 50765 <...>-70344 [001] d... 2372.510629: execsnoop_sys_execve: (SyS_execve+0x0/0x30) 70343 70341 cat -v trace_pipe 70340 0 /usr/local/bin/stress -t 1 -d 1 70346 70339 /usr/local/bin/stress -t 1 -d 1 70347 70344 /usr/local/bin/stress -t 1 -d 1 70351 50796 <...>-70351 [000] d... 2372.553884: execsnoop_sys_execve: (SyS_execve+0x0/0x30) 70352 50775 <...>-70352 [000] d... 2372.555010: execsnoop_sys_execve: (SyS_execve+0x0/0x30) 70353 70351 /usr/local/bin/stress -t 1 -d 1 70355 50776 <...>-70355 [000] d... 2372.557869: execsnoop_sys_execve: (SyS_execve+0x0/0x30) 70357 70355 /usr/local/bin/stress -t 1 -d 1 70356 70352 /usr/local/bin/stress -t 1 -d 1 |
execsnoop所用的ftrace是一种常用的动态追踪技术,一般用于分析linux内核的运行时为
2、pstree的安装
1 | yum install psmisc |
3、小结
如果碰到不好解释的CPU问题时,比如现象:
通过top观察CPU使用率很高,但是看下面的进程的CPU使用率好像很正常,通过pidstat命令查看cpu也很正常。但通过top查看task数量不正常,处于R状态的进程是可疑点。
首先要想到可能是短时间的应用导致的问题,如下面的两个:
(1)应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过top等工具发现不了
(2)应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用很多CPU资源


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构