Linux性能优化实战学习笔记:第五讲
一、什么是CPU的使用率
1、你最常用什么指标来描述系统的CPU性能?
我想你的答案,可能不是平均负载,也不是CPU上下文切换,而是另一个更直观的指标CPU使用率
CPU使用率到底是怎么算出来的吗?
1、如何设置节拍率
1 2 | [root@luoahong ~]# grep 'CONFIG_HZ=' /boot/config-$(uname -r)CONFIG_HZ=1000 |
2、内核提供的用户节拍率是多少?
1 | USER_HZ=100 |
为了方便用户控件程序,内核还提供了一个用户控件的节拍率,它总是固定为100,也就是1/100秒,这样,用户控件程序并需要关系内核中HZ被设置成了多少
4、如何查看用户控件系统内部状态信息
1 2 3 4 5 | [root@luoahong ~]# cat /proc/stat | grep ^cpucpu 62143 14 10857 931923 669 0 3498 0 0 0cpu0 31506 4 5649 467020 228 0 628 0 0 0cpu1 30637 10 5207 464903 441 0 2870 0 0 0[root@luoahong ~]# |
这里的输出结果是一个表格,其中,第一列表示的是CPU编号,如CPU0、CPU1,而第一行没有编号的CPU
表示的是所有CPU的累加
二、CPU使用率公式
我们通常所说的 CPU使用率,就是除了空闲时间外的其他时间占总CPU时间的百分比,用公式来表示就是
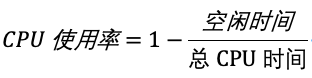
1、直接用/proc/stat 的数据,算的是什么时间段的 CPU使用率吗?
看到这里,你应该想起来了,这是开机以来的节拍数累加值,所以直接算出来的,是开机以来的平均CPU使用率,一般没啥参考价值
2、性能工具是如何计算CPU使用率的
事实上,为了计算机CPU使用率,性能能工具一般都会间隔一段时间(比如 3 秒)的两次值,做差后,再计算出这段时间的平均CPU使用率
各种性能工具所看到的CPU使用率的实际计算方法如下

性能分析工具给出的都是间隔一段时间的平均CPU使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,
你一定要保证他们用的是相同的间隔时间
三、怎么查看CPU使用率
1、top显示系统总体CPU使用情况
top显示了系统总体的CPU和内存使用情况,以及各个进程的资源使用情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # 默认每 3 秒刷新一次$ toptop - 11:00:25 up 1:35, 2 users, load average: 0.00, 0.01, 0.18Tasks: 131 total, 1 running, 130 sleeping, 0 stopped, 0 zombie%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 stKiB Mem : 8056848 total, 5665852 free, 688220 used, 1702776 buff/cacheKiB Swap: 2097148 total, 2097148 free, 0 used. 6945016 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 10150 polkitd 20 0 1267680 201924 9372 S 1.0 2.5 0:39.33 mysqld 9906 mysql 20 0 1119708 184904 5824 S 0.7 2.3 0:32.89 mysqld 8041 root 20 0 300896 6384 4956 S 0.3 0.1 0:28.40 vmtoolsd... |
2、top图解

3、 pidstat分析每个进程CPU使用情况
top并没有细分进程的用户态CPU和内核态CPU,那要怎么查看每个进程的详细情况呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 默认每 3 秒刷新一次$ toptop - 11:00:25 up 1:35, 2 users, load average: 0.00, 0.01, 0.18Tasks: 131 total, 1 running, 130 sleeping, 0 stopped, 0 zombie%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 stKiB Mem : 8056848 total, 5665852 free, 688220 used, 1702776 buff/cacheKiB Swap: 2097148 total, 2097148 free, 0 used. 6945016 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 10150 polkitd 20 0 1267680 201924 9372 S 1.0 2.5 0:39.33 mysqld 9906 mysql 20 0 1119708 184904 5824 S 0.7 2.3 0:32.89 mysqld 8041 root 20 0 300896 6384 4956 S 0.3 0.1 0:28.40 vmtoolsd...Average: 999 10150 0.20 0.40 0.00 0.00 0.60 - mysqldAverage: 0 11747 0.40 1.59 0.00 0.00 1.98 - pidstat |
4、pidstat命令图解

最后的Average部分,还计算了5组数据的平均值
四、CPU使用率过高怎么办?
1、分析思路
1、如何轻松找到CPU使用率过高的进程
通过top、ps 、pidstat等工具
2、占用CPU高的到底是代码里的那个函数?
perf和GDB
3、那么哪种工具适合在第一时间分析进程的 CPU 问题呢?
perf是Linux 2.6.31 以后内置的性能分析工具,它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析制定应用程序的性能问题
2、实时显示占用CPU时钟最多的函数
实时显示占用CPU时钟最多的函数或者指令,因此可以用来查找热点函数
1 2 3 4 5 6 | [root@luoahong ~]# perf topSamples: 724 of event 'cpu-clock', Event count (approx.): 125711088Overhead Shared Object Symbol45.11% [kernel] [k] generic_exec_single... |
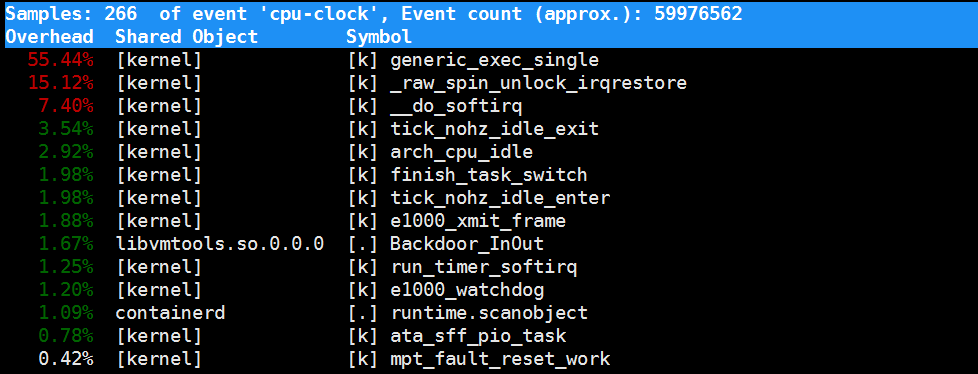
采样数需要我们特别注意,如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了
3、perf命令详解
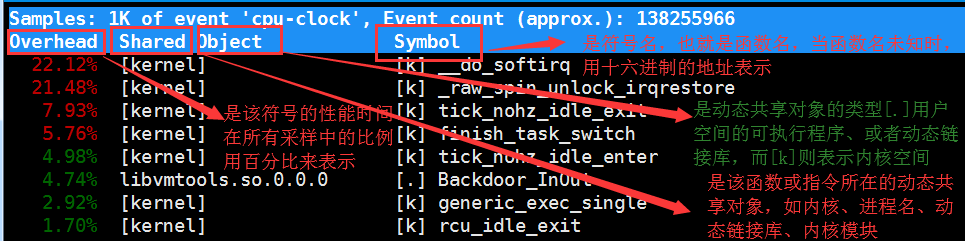
虽然实时展示了系统的性能信息,但它的缺点并不能保存数据,也就无法离线或者后续的分析,而perf record
则提供了保存数据的功能,保存后的数据,需要你用perf report解析展示
4、离线和后续分析占用CPU时钟最多的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | perf record # 按 Ctrl+C 终止采样[root@luoahong ~]# perf reportSamples: 5K of event 'cpu-clock', Event count (approx.): 1332500000Overhead Command Shared Object Symbol97.15% swapper [kernel.kallsyms] [k] native_safe_halt0.49% swapper [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore0.36% vmtoolsd libvmtools.so.0.0.0 [.] Backdoor_InOut0.34% swapper [kernel.kallsyms] [k] __do_softirq0.17% swapper [kernel.kallsyms] [k] tick_nohz_idle_exit0.13% swapper [kernel.kallsyms] [k] tick_nohz_idle_enter0.13% vmtoolsd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore0.11% kworker/0:1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore0.11% vmtoolsd libvmtools.so.0.0.0 [.] BackdoorHbOut0.08% dockerd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore0.08% vmtoolsd [kernel.kallsyms] [k] __do_softirq0.06% kworker/1:2 [kernel.kallsyms] [k] queue_delayed_work_on0.06% vmtoolsd [kernel.kallsyms] [k] format_decode0.04% irqbalance [kernel.kallsyms] [k] cap_mmap_file0.04% kworker/0:0 [kernel.kallsyms] [k] ata_sff_pio_task0.04% kworker/1:2 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore0.04% mysqld mysqld [.] fts_optimize_words0.04% swapper [kernel.kallsyms] [k] rcu_idle_exit0.04% vmtoolsd libvmtools.so.0.0.0 [.] BackdoorHbIn0.02% dockerd [kernel.kallsyms] [k] __do_softirq0.02% in:imjournal rsyslogd [.] 0x0000000000016f900.02% irqbalance [kernel.kallsyms] [k] __fsnotify_parent0.02% irqbalance [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore0.02% irqbalance [kernel.kallsyms] [k] copy_user_generic_unrolled0.02% irqbalance [kernel.kallsyms] [k] native_flush_tlb_single0.02% irqbalance [kernel.kallsyms] [k] unmap_page_rangeTip: For tracepoint events, try: perf report -s trace_fields |
在实际使用中,我们还经常为perf top和perf record加上-g参数,开启调用关系的采样,方便我们根据调用链分析西能问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构