MyCat介绍与配置
MyCat介绍与配置

Mycat 前生今世
如果我有一个32核心的服务器,我就可以实现1个亿的数据分片,我有32核心的服务器么?没有,所以我至今无法实现1个亿的数据库分片。---Mycat 's Plan
Mycat 简介
Mycat是什么?
对于DBA来说,可以这么理解Mycat:
对于软件工程师来说,可以这么理解Mycat:
对于架构师来说,可以这么理解Mycat:
Mycat原理
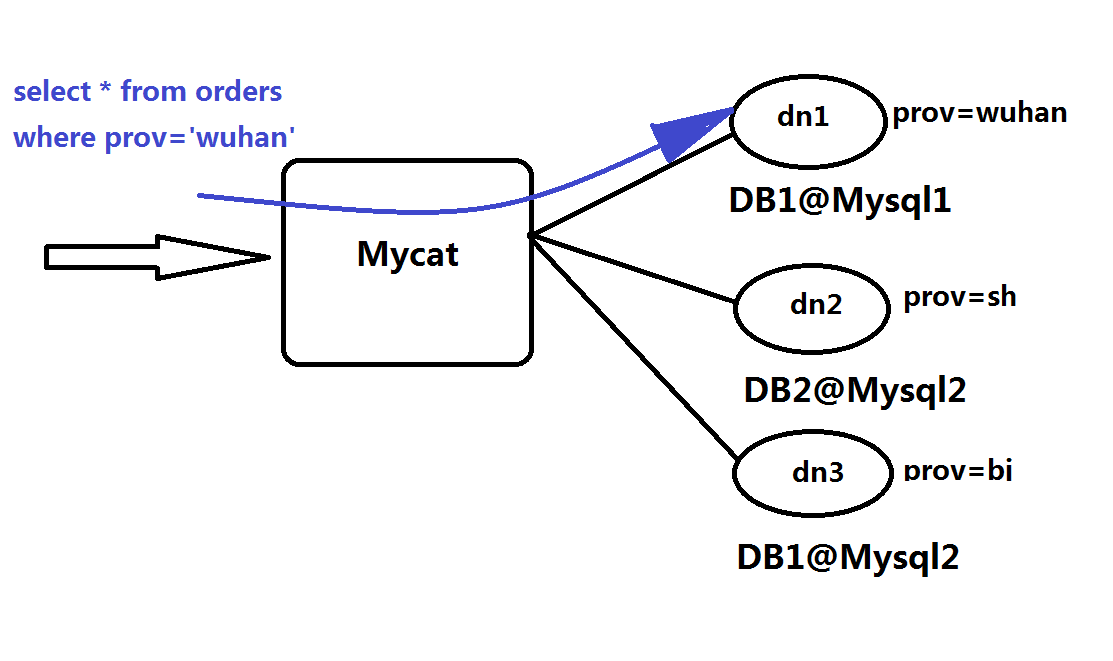
应用场景
Mycat长期路线图
Mycat中的概念
数据库中间件
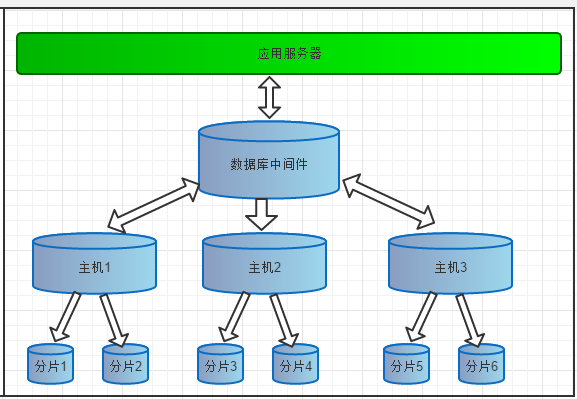
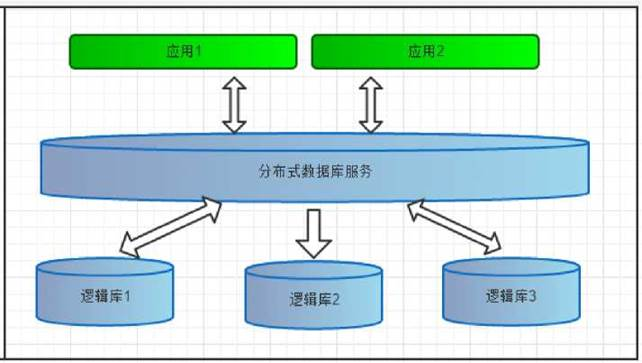
逻辑库(schema)
逻辑表(table)
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可 以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表
<table name=nt_noden primaryKey=nvidn autoincrement=ntruen dataNode=ndn1,dn2n rule=nrule1n />
非分片表
<table name=nt_noden primaryKey=nvidn autoincrement=ntruen dataNode=ndn1" />
ER 表
全局表
分片节点(dataNode)
分片规则(rule)
多租户
1.1 独立数据库
1.2共享数据库,隔离数据架构
共享数据库,共享数据架构
何为数据切分?
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主 机)上面,以达到分散单台设备负载的效果。
数据的切分(Sharding )根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者 Schema )来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
垂直切分
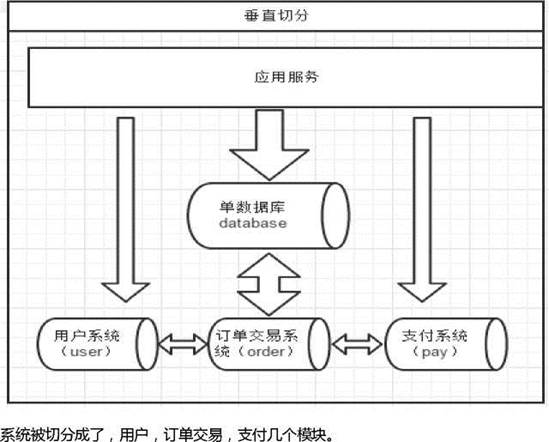
下面来分析下垂直切分的优缺点:
- 拆分后业务清晰,拆分规则明确。
- 系统之间整合或扩展容易。
- 数据维护简单。
- 部分业务表无法join ,只能通过接口方式解决,提高了系统复杂度。
- 受每种业务不同的限制存在单库性能瓶颈,不易扩展跟性能提高。
- 事务处理复杂。由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,所以就需要水平拆分来做解决。
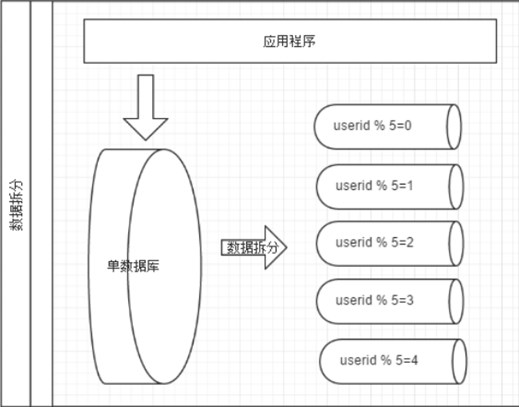
水平切分
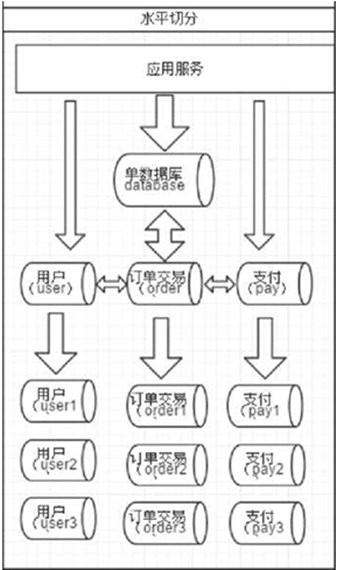
几种典型的分片规则包括:
前面讲了垂直切分跟水平切分的不同跟优缺点,会发现每种切分都有缺点,但共同的特点缺点有:
针对数据源管理,目前主要有两种思路:
可能 90%以上的人在面对上面这两种解决思路的时候都会倾向于选择第二种,尤其是系统不断变得庞大复杂的时候。确实,这是一个非常正确的选择,虽然短期内需要付出的成本可能会相对更大一些,但是对整个系统的扩展性来讲,是非常有帮助的数据切分的原则:
数据切分的原则:
安装Mycat
安装Mycat
wget http://dl.mycat.io/1.6.5/Mycat-server-1.6.5-release-20180122220033-linux.tar.gz tar zxf Mycat-server-1.6.5-release-20180122220033-linux.tar.gz mkdir /application/ mv mycat /application/ echo "export PATH=/application/mycat/bin:$PATH" >> /etc/profile source /etc/profile echo $PATH
下载安装JDK
因为jdk和Tomcat的版本对运维来说没什么区别,提供本文使用的软件下载地址:
链接:https://pan.baidu.com/s/1OToeWr-1jD-hmKYc8UivUA 密码:ze3h
[root@tomcat ~]# cd /application/tools/ [root@tomcat tools]# rz rz waiting to receive. Starting zmodem transfer. Press Ctrl+C to cancel. Transferring apache-tomcat-8.0.27.tar.gz... 100% 8914 KB 8914 KB/sec 00:00:01 0 Errors Transferring jdk-8u60-linux-x64.tar.gz... 100% 176990 KB 14749 KB/sec 00:00:12 0 Errors tar xf jdk-8u60-linux-x64.tar.gz -C /application/ ln -s /application/jdk1.8.0_60 /application/jdk sed -i.ori '$a export JAVA_HOME=/application/jdk\nexport PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH\nexport CLASSPATH=.$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar' /etc/profile source /etc/profile #→出现下面结果证明部署成功 [root@tomcat ~]# java -version java version "1.8.0_60" Java(TM) SE Runtime Environment (build 1.8.0_60-b27) Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mode)
创建管理用户
主库上对rep和rep_r用户授权如下: 用户:rep 密码:oldboy 端口:3306 权限:all 命令: grant replication slave on test.* to 'rep'@'10.0.0.%' identified by 'oldboy'; grant replication slave on test.* to 'rep_r'@'10.0.0.%' identified by 'oldboy'; flush privileges; 注:为了方便下面的主从切换,两个用户都授予了所有的权限,生产环境尽量不要这样子授权!
[root@Linuxdemo3 mycat]# pwd /application/mycat [root@Linuxdemo3 mycat]# ll total 24 drwxr-xr-x 2 root root 4096 Jul 4 03:13 bin drwxrwxrwx 2 root root 4096 Dec 13 2015 catlet drwxrwxrwx 2 root root 4096 Jul 4 03:13 conf drwxr-xr-x 2 root root 4096 Jul 4 03:13 lib drwxrwxrwx 2 root root 4096 Dec 13 2015 logs -rwxrwxrwx 1 root root 219 Jun 22 15:33 version.txt
修改server.xml文件
[root@Linuxdemo3 conf]# vim server.xml
</system>
<user name="rep">
<property name="password">oldboy</property>
<property name="schemas">test</property>
</user>
<user name="rep_r">
<property name="password">oldboy</property>
<property name="schemas"> test</property>
<property name="readOnly">true</property>
</user>
修改schema.xml文件
[root@Linuxdemo3 conf]# vim schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/" >
<schema name="test" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="localhost1" database="test" />
<dataNode name="dn2" dataHost="localhost1" database=" test " />
<dataNode name="dn3" dataHost="localhost1" database=" test " />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="10.0.0.202:3306" user="rep"
password="oldboy">
</writeHost>
<readHost host="hostS1" url="10.0.0.202:3307" user="rep_r"
password="oldboy" />
</readHost>
</dataHost>
</mycat:schema>
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
需要配置的位置:
balance="1" writeType="0" switchType="1"
balance
writeType
switchType
<writeHost host="hostM1" url="10.0.0.202:3306" user="rep"
password="oldboy">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="10.0.0.202:3306" user="rep_r"
password="oldboy"/>
启动Mycat
[root@Linuxdemo3 conf]# /application/mycat/bin/mycat start Starting Mycat-server... [root@Linuxdemo3 logs]#
mysql -urep -poldboy -h10.0.0.202 -P8066 mysql> explain create table company(id int not null primary key,name varchar(100)); +-----------+---------------------------------------------------------------------+ | DATA_NODE | SQL | +-----------+---------------------------------------------------------------------+ | dn1 | create table company(id int not null primary key,name varchar(100)) | | dn2 | create table company(id int not null primary key,name varchar(100)) | | dn3 | create table company(id int not null primary key,name varchar(100)) | +-----------+---------------------------------------------------------------------+ 3 rows in set (0.06 sec) mysql> create table company(id int not null primary key,name varchar(100)); Query OK, 0 rows affected (1.82 sec) mysql> explain insert into company(id, name) values (100, 'abc'); +-----------+---------------------------------------------------+ | DATA_NODE | SQL | +-----------+---------------------------------------------------+ | dn1 | insert into company(id, name) values (100, 'abc') | | dn2 | insert into company(id, name) values (100, 'abc') | | dn3 | insert into company(id, name) values (100, 'abc') | +-----------+---------------------------------------------------+ 3 rows in set (0.00 sec) mysql> insert into company(id, name) values (100, 'abc'); Query OK, 1 row affected (0.24 sec)
查看日志
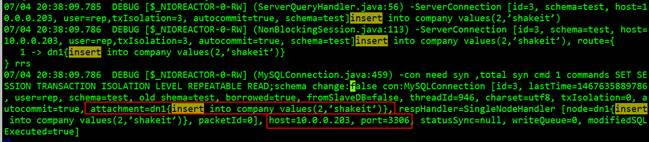
分别在主从库中执行以下命令:
mysql> select * from company where id = 100; +-----+------+ | id | name | +-----+------+ | 100 | abc | +-----+------+ 1 row in set (0.00 sec)
日志中有如下
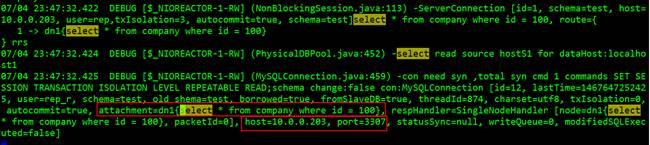
mysql> insert into company(id, name) values (4, 'abcwq'); ERROR 1495 (HY000): User readonly #从库只读
主从切换测试
将schema.xml文件做如下修改:
[root@Linuxdemo3 conf]# vim schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/" >
<schema name="test" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="localhost1" database="test" />
<dataNode name="dn2" dataHost="localhost1" database=" test " />
<dataNode name="dn3" dataHost="localhost1" database=" test " />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<writeHost host="hostM1" url="10.0.0.202:3306" user="rep"
password="oldboy">
</writeHost>
<readHost host="hostS1" url="10.0.0.202:3307" user="rep_r"
password="oldboy" />
</readHost>
<writeHost host="hostM2" url="10.0.0.202:3307" user="rep"
password="oldboy">
</writeHost>
</dataHost>
</mycat:schema>
重启mycat服务
[root@Linuxdemo2 conf]# /application/mycat/bin/mycat restart Stopping Mycat-server... Stopped Mycat-server. Starting Mycat-server...
[root@Linuxdemo2 conf]# /data/3306/mysql stop
Mycat-Web
安装zookpeer
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz tar -xzvf zookeeper-3.4.6.tar.gz cd zookeeper-3.4.6/conf cp zoo_sample.cfg zoo.cfg cd zookeeper-3.4.6/bin ./zkServer.sh start 出现一下信息 说明启动成功 JMX enabled by default Using config: /usr1/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
安装mycat-web
wget https://github.com/MyCATApache/Mycat-download/raw/master/mycat-web-1.0/Mycat-web-1.0-SNAPSHOT-20160617163048-linux.tar.gz tar zxf Mycat-web-1.0-SNAPSHOT-20160617163048-linux.tar.gz cd mycat-web/mycat-web/WEB-INF/classes vim mycat.properties zookeeper=127.0.0.1:2181 sqlonline.server=10.0.0.202 cd mycat-web #将start.sh文件中的JVM调整到合适的大小 ./start.sh & #8082端口是web端口 访问10.0.0.202:8082/mycat即可进入web页面
cd /application/mycat/bin
/application/mycat/bin/xml_to_yaml.sh 根据mycat配置生成 zookeeper yaml 配置工具 /application/mycat/bin/init_zk_data.sh 将生成的yaml配置文件导入远程zookeeper /application/mycat/conf/myid.properties zookeeper 路径配置参数信息 /application/mycat/conf/zk-create.yaml 自动生成的zk配置
1)确认安装好zookeeper 环境
2)启动mycat服务,确认本地服务一切正常。
3)执行xml_to_yaml.sh脚本(确认本地配置过 JAVA_HOME 和 MYCAT_HOME环境变量,)
[root@Linuxdemo3 bin]# ./xml_to_yaml.sh
4) 执行 init_zk_data.sh 脚本 , 注意下默认情况下脚本会将zookeeper定位在同一台服务器上面,如有需要可以调整下 ZK 的 IP : PORT
[root@Linuxdemo3 bin]# ./init_zk_data.sh
管理命令与监控
mysql -urep -poldboy -h10.0.0.202 -P9066 -Dtest
1、查看所有的命令,如下:
mysql> show @@help; +--------------------------------------+-----------------------------------+ | STATEMENT | DESCRIPTION | +--------------------------------------+-----------------------------------+ | clear @@slow where datanode = ? | Clear slow sql by datanode | | clear @@slow where schema = ? | Clear slow sql by schema | | kill @@connection id1,id2,... | Kill the specified connections | | offline | Change MyCat status to OFF | | online | Change MyCat status to ON | | reload @@config | Reload basic config from file | | reload @@config_all | Reload all config from file | | reload @@route | Reload route config from file | | reload @@user | Reload user config from file | | rollback @@config | Rollback all config from memory | | rollback @@route | Rollback route config from memory | | rollback @@user | Rollback user config from memory | | show @@backend | Report backend connection status | | show @@cache | Report system cache usage | | show @@command | Report commands status | | show @@connection | Report connection status | | show @@connection.sql | Report connection sql | | show @@database | Report databases | | show @@datanode | Report dataNodes | | show @@datanode where schema = ? | Report dataNodes | | show @@datasource | Report dataSources | | show @@datasource where dataNode = ? | Report dataSources | | show @@heartbeat | Report heartbeat status | | show @@parser | Report parser status | | show @@processor | Report processor status | | show @@router | Report router status | | show @@server | Report server status | | show @@session | Report front session details | | show @@slow where datanode = ? | Report datanode slow sql | | show @@slow where schema = ? | Report schema slow sql | | show @@sql where id = ? | Report specify SQL | | show @@sql.detail where id = ? | Report execute detail status | | show @@sql.execute | Report execute status | | show @@sql.slow | Report slow SQL | | show @@threadpool | Report threadPool status | | show @@time.current | Report current timestamp | | show @@time.startup | Report startup timestamp | | show @@version | Report Mycat Server version | | stop @@heartbeat name:time | Pause dataNode heartbeat | | switch @@datasource name:index | Switch dataSource
2、更新配置文件
mysql> reload @@config; Query OK, 1 row affected (0.13 sec) Reload config success
3、显示mycat数据库的列表,对应的在scehma.xml配置的逻辑库
mysql> show @@database; +----------+ | DATABASE | +----------+ | oldboy | +----------+ 1 row in set (0.00 sec)
4、显示mycat数据节点的列表,对应的是scehma.xml配置文件的dataNode节点
mysql> show @@datanode; +------+-------------------+-------+-------+--------+------+------+---------+------------+----------+---------+---------------+ | NAME | DATHOST | INDEX | TYPE | ACTIVE | IDLE | SIZE | EXECUTE | TOTAL_TIME | MAX_TIME | MAX_SQL | RECOVERY_TIME | +------+-------------------+-------+-------+--------+------+------+---------+------------+----------+---------+---------------+ | dn1 | localhost1/oldboy | 0 | mysql | 0 | 10 | 1000 | 457 | 0 | 0 | 0 | -1 | | dn2 | localhost1/oldboy | 0 | mysql | 0 | 10 | 1000 | 457 | 0 | 0 | 0 | -1 | | dn3 | localhost1/oldboy | 0 | mysql | 0 | 10 | 1000 | 457 | 0 | 0 | 0 | -1 | +------+-------------------+-------+-------+--------+------+------+---------+------------+----------+---------+---------------+ 3 rows in set (0.00 sec)
5、报告心跳状态
mysql> show @@heartbeat; +--------+-------+-------------+------+---------+-------+--------+---------+--------------+---------------------+-------+ | NAME | TYPE | HOST | PORT | RS_CODE | RETRY | STATUS | TIMEOUT | EXECUTE_TIME | LAST_ACTIVE_TIME | STOP | +--------+-------+-------------+------+---------+-------+--------+---------+--------------+---------------------+-------+ | hostM1 | mysql | 10.0.0.202 | 3306 | 1 | 0 | idle | 0 | 1,1,1 | 2015-12-29 21:39:40 | false | | hostS1 | mysql | 10.0.0.202 | 3307 | 1 | 0 | idle | 0 | 3,3,3 | 2015-12-29 21:39:40 | false | +--------+-------+-------------+------+---------+-------+--------+---------+--------------+---------------------+-------+ 2 rows in set (0.01 sec)
6、获取当前mycat的版本
mysql> show @@version; +--------------------------------------+ | VERSION | +--------------------------------------+ | 5.5.8-mycat-1.4-alpha-20150520235658 | +--------------------------------------+ 1 row in set (0.00 sec)
7、显示mycat前端连接状态
mysql> show @@connection; +------------+------+-----------+------+------------+--------+---------+--------+---------+---------------+-------------+------------+---------+------------+ | PROCESSOR | ID | HOST | PORT | LOCAL_PORT | SCHEMA | CHARSET | NET_IN | NET_OUT | ALIVE_TIME(S) | RECV_BUFFER | SEND_QUEUE | txlevel | autocommit | +------------+------+-----------+------+------------+--------+---------+--------+---------+---------------+-------------+------------+---------+------------+ | Processor0 | 6 | 127.0.0.1 | 9066 | 46490 | oldboy | utf8:33 | 281 | 6164 | 1008 | 4096 | 0 | | | +------------+------+-----------+------+------------+--------+---------+--------+---------+---------------+-------------+------------+---------+------------+ 1 row in set (0.00 sec)
8、显示mycat后端连接状态
mysql> show @@backend; +------------+------+---------+-------------+------+--------+--------+---------+------+--------+----------+------------+--------+---------+---------+------------+ | processor | id | mysqlId | host | port | l_port | net_in | net_out | life | closed | borrowed | SEND_QUEUE | schema | charset | txlevel | autocommit | +------------+------+---------+-------------+------+--------+--------+---------+------+--------+----------+------------+--------+---------+---------+------------+ | Processor0 | 1 | 30 | 10.0.0.202 | 3306 | 14881 | 3554 | 1068 | 5041 | false | false | 0 | oldboy | utf8:33 | 3 | true | | Processor0 | 2 | 32 | 10.0.0.202 | 3306 | 14883 | 3554 | 1068 | 5041 | false | false | 0 | oldboy | utf8:33 | 3 | true | | Processor0 | 3 | 24 | 10.0.0.202 | 3306 | 14875 | 3515 | 1068 | 5041 | false | false | 0 | oldboy | utf8:33 | 3 | true | | Processor0 | 4 | 28 | 10.0.0.202 | 3306 | 14879 | 3561 | 986 | 5041 | false | false | 0 | oldboy | utf8:33 | 0 | true |
9、显示数据源
mysql> show @@datasource; +----------+--------+-------+-------------+------+------+--------+------+------+---------+ | DATANODE | NAME | TYPE | HOST | PORT | W/R | ACTIVE | IDLE | SIZE | EXECUTE | +----------+--------+-------+-------------+------+------+--------+------+------+---------+ | dn1 | hostM1 | mysql | 10.0.0.202 | 3306 | W | 0 | 10 | 1000 | 525 | | dn1 | hostS1 | mysql | 10.0.0.202 | 3306 | R | 0 | 8 | 1000 | 522 | | dn3 | hostM1 | mysql | 10.0.0.202 | 3306 | W | 0 | 10 | 1000 | 525 | | dn3 | hostS1 | mysql | 10.0.0.202 | 3306 | R | 0 | 8 | 1000 | 522 | | dn2 | hostM1 | mysql | 10.0.0.202 | 3306 | W | 0 | 10 | 1000 | 525 | | dn2 | hostS1 | mysql | 10.0.0.202 | 3306 | R | 0 | 8 | 1000 | 522 | +----------+--------+-------+-------------+------+------+--------+------+------+---------+ 6 rows in set (0.01 sec)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号