三剑客:awk实战
1 awk实战基础入门精讲
1.1 awk命令格式:
awk指令由模式、动作、或者模式和动作的组合组成
模式既pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的政策表达式。比如NR==,这就是模式,可以把他理解位一个条件。
动作即action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开。如awk使用格式

1.1.1 常见的模式类型:
1、Regexp: 正则表达式,格式为/regular expression/
2、expresssion: 表达式,其值非0或为非空字符时满足条件,如:$1 ~ /foo/ 或 $1 == "magedu",用运算符~(匹配)和!~(不匹配)。
3、Ranges: 指定的匹配范围,格式为pat1,pat2
4、BEGIN/END:特殊模式,仅在awk命令执行前运行一次或结束前运行一次
5、Empty(空模式):匹配任意输入行;
1.1.2 常见的Action
1、Expressions:
2、Control statements
3、Compound statements
4、Input statements
5、Output statements
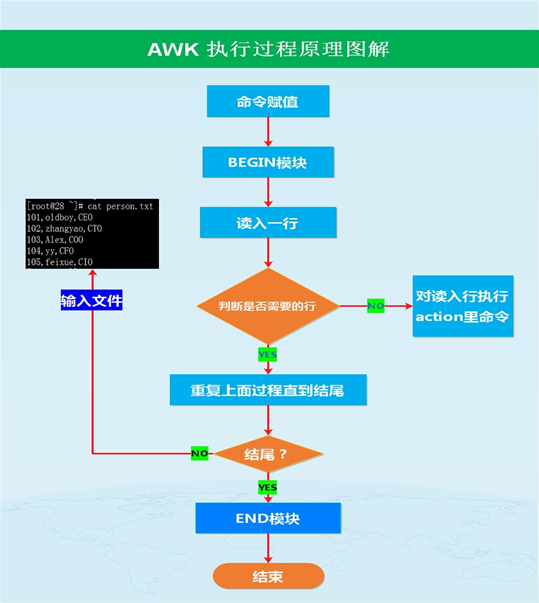
1.2 awk的执行过程
系统环境
[root@cobbler6 ~]# cat /etc/redhat-release CentOS release 6.7 (Final) [root@cobbler6 ~]# uname -r 2.6.32-573.el6.x86_64 [root@cobbler6 ~]# ll "which awk" ls: cannot access which awk: No such file or directory [root@cobbler6 ~]# ll `which awk` lrwxrwxrwx. 1 root root 4 Oct 7 01:03 /bin/awk -> gawk [root@cobbler6 ~]# awk --version GNU Awk 3.1.7
示例文件:
[root@cobbler6 ~]# mkdir /server/files/ -p [root@cobbler6 ~]# head /etc/passwd >/server/ files/ scripts/ [root@cobbler6 ~]# head /etc/passwd >/server/files/awkfile.txt [root@cobbler6 ~]# cat awkfile.txt cat: awkfile.txt: No such file or directory [root@cobbler6 ~]# cat /server//files/awkfile.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
1.3 记录和域的概念
[root@cobbler6 files]# awk 'BEGIN{RS=":"}{print NR,$0}' awkfile.txt
1 root
2 x
3 0
4 0
5 root
6 /root
7 /bin/bash
bin
8 x
awk眼中的文件,从头到尾一段连续的字符串,恰巧中间有些\n(回车换行符),为了方便人查看,就把RS的值设置为\n
[root@cobbler6 files]# awk 'BEGIN{RS=""}{print NR,$0}' awkfile.txt
1 root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
[root@cobbler6 files]# awk 'BEGIN{RS=""}{print NR,$1,$3,#5}' awkfile.txt
awk: cmd. line:1: BEGIN{RS=""}{print NR,$1,$3,#5}
awk: cmd. line:1: ^ syntax error
[root@cobbler6 files]# awk 'BEGIN{RS=""}{print NR,$1,$3,$5}' awkfile.txt
1 root:x:0:0:root:/root:/bin/bash daemon:x:2:2:daemon:/sbin:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
企业案例1:计算文件中每个单词重复数量
1、单词弄成一列(排队)
sed -ri.bak 's#[:/0-9]+# #g' awkfile.txt
RS 替换\n
[root@cobbler6 files]# egrep -o "[a-zA-Z]+" awkfile.txt |sort|uniq -c
3 adm
1 bash
5 bin
2 daemon
3 halt
2 lp
1 lpd
3 mail
6 nologin
3 root
12 sbin
3 shutdown
3 spool
3 sync
3 uucp
4 var
10 x
RS 空值
[root@cobbler6 files]# sed -ri.bak 's#[:/0-9]+# #g' awkfile.txt
去掉[:/0-9]
[root@cobbler6 files]# cat awkfile.txt
root x root root bin bash
bin x bin bin sbin nologin
daemon x daemon sbin sbin nologin
adm x adm var adm sbin nologin
lp x lp var spool lpd sbin nologin
sync x sync sbin bin sync
shutdown x shutdown sbin sbin shutdown
halt x halt sbin sbin halt
mail x mail var spool mail sbin nologin
uucp x uucp var spool uucp sbin nologin
2、统计
egrep -o "[a-zA-Z]+" awkfile.txt |sort|uniq –c
awk 'BEGIN{RS="()|\n"}{print NR,$0}' awkfile.txt |sort|uniq -c|sort –rn
企业按案例2:计算文件中重复的数量
1.3.1 记录小结:
- 大象放冰箱分几步?打开冰箱,把大象放进去,关闭冰箱门。
- 多使用,NR,NF,$数字,配合你调试你的awk命令
- NR number of record存放着每个记录的号(行号)读取新行时候会自动+1
- RS record separate是输入数据的记录的分隔符,简单理解就是可以指定每个记录的记录结尾标记
- (用RS替换\n)
- RS 作用就是表示一个记录的结束
- FS 表示着每个区域的结束
1.3.2 小结:
- $ 表示取区域,$1,$2 NF,$NF
- NF number of fileds 表示记录中的区域数量,$NF取最后一个区域
- FS(-F) filed separate区域分隔符,
- RS
- NR
- 选好合适的刀FS(***),RS,OFS,ORS
- $1,$3,$数字 选中你要处理的区域
- 分隔符==》结束表示
- 记录与区域,你就对我们所谓的行与列,有了新的认识。
用于第二行或第五行
[root@cobbler6 files]# awk 'NR==2||NR==5{print $1,$3}' awkfile.txt
bin bin
lp lp
FNR: 与NR不同的是,FNR用于记录正处理的行是当前这一文件中被总共处理的行数;
ARGV: 数组,保存命令行本身这个字符串,如awk '{print $0}' a.txt b.txt这个命令中,ARGV[0]保存awk,ARGV[1]保存a.txt;
ARGC: awk命令的参数的个数;
FILENAME: awk命令所处理的文件的名称;
ENVIRON:当前shell环境变量及其值的关联数组;
1.4 正则表达式
[root@cobbler6 files]# awk -F "/" '$(NF-1)~/^bin/{print NF,$0,$3}' /etc/passwd
4 root:x:0:0:root:/root:/bin/bash bin
4 sync:x:5:0:sync:/sbin:/bin/sync bin
5 asdfghg:x:503:503::/home/asdfghg:/bin/bash asdfghg:
5 chujiyw001:x:809:809::/home/chujiyw001:/bin/bash chujiyw001:
5 chujiyw002:x:810:810::/home/chujiyw002:/bin/bash chujiyw002:
5 chujiyw003:x:811:811::/home/chujiyw003:/bin/bash chujiyw003:
5 ywsenior001:x:812:812::/home/ywsenior001:/bin/bash ywsenior001:
5 ywmanager001:x:813:813::/home/ywmanager001:/bin/bash ywmanager001:
5 chujikf001:x:814:814::/home/chujikf001:/bin/bash chujikf001:
5 chujikf002:x:815:815::/home/chujikf002:/bin/bash chujikf002:
5 kfsenior001:x:816:816::/home/kfsenior001:/bin/bash kfsenior001:
5 kfmanager001:x:817:817::/home/kfmanager001:/bin/bash kfmanager001:
5 jiak001:x:818:818::/home/jiak001:/bin/bash jiak001:
5 jiak002:x:819:819::/home/jiak002:/bin/bash jiak002:
5 chjidba001:x:820:820::/home/chjidba001:/bin/bash chjidba001:
5 chjidba002:x:821:821::/home/chjidba002:/bin/bash chjidba002:
5 chjidba003:x:822:822::/home/chjidba003:/bin/bash chjidba003:
5 dbasenior001:x:823:823::/home/dbasenior001:/bin/bash dbasenior001:
5 chjidwg001:x:824:824::/home/chjidwg001:/bin/bash chjidwg001:
5 chjidwg002:x:825:825::/home/chjidwg002:/bin/bash chjidwg002:
5 wgsenior001:x:826:826::/home/wgsenior001:/bin/bash wgsenior001:
[root@cobbler6 files]# awk -F "/" '$(NF-1)~/^bin/{print NF,$3}' /etc/passwd
4 bin
4 bin
5 asdfghg:
5 chujiyw001:
5 chujiyw002:
5 chujiyw003:
5 ywsenior001:
5 ywmanager001:
5 chujikf001:
5 chujikf002:
5 kfsenior001:
5 kfmanager001:
5 jiak001:
5 jiak002:
5 chjidba001:
5 chjidba002:
5 chjidba003:
5 dbasenior001:
5 chjidwg001:
5 chjidwg002:
5 wgsenior001:
[root@cobbler6 files]# awk -F "/" '$(NF-1)~/^bin/{print NF,$0,$3}' /etc/passwd
4 root:x:0:0:root:/root:/bin/bash bin
4 sync:x:5:0:sync:/sbin:/bin/sync bin
5 asdfghg:x:503:503::/home/asdfghg:/bin/bash asdfghg:
5 chujiyw001:x:809:809::/home/chujiyw001:/bin/bash chujiyw001:
5 chujiyw002:x:810:810::/home/chujiyw002:/bin/bash chujiyw002:
5 chujiyw003:x:811:811::/home/chujiyw003:/bin/bash chujiyw003:
5 ywsenior001:x:812:812::/home/ywsenior001:/bin/bash ywsenior001:
5 ywmanager001:x:813:813::/home/ywmanager001:/bin/bash ywmanager001:
5 chujikf001:x:814:814::/home/chujikf001:/bin/bash chujikf001:
5 chujikf002:x:815:815::/home/chujikf002:/bin/bash chujikf002:
5 kfsenior001:x:816:816::/home/kfsenior001:/bin/bash kfsenior001:
5 kfmanager001:x:817:817::/home/kfmanager001:/bin/bash kfmanager001:
5 jiak001:x:818:818::/home/jiak001:/bin/bash jiak001:
5 jiak002:x:819:819::/home/jiak002:/bin/bash jiak002:
5 chjidba001:x:820:820::/home/chjidba001:/bin/bash chjidba001:
5 chjidba002:x:821:821::/home/chjidba002:/bin/bash chjidba002:
5 chjidba003:x:822:822::/home/chjidba003:/bin/bash chjidba003:
5 dbasenior001:x:823:823::/home/dbasenior001:/bin/bash dbasenior001:
5 chjidwg001:x:824:824::/home/chjidwg001:/bin/bash chjidwg001:
5 chjidwg002:x:825:825::/home/chjidwg002:/bin/bash chjidwg002:
5 wgsenior001:x:826:826::/home/wgsenior001:/bin/bash wgsenior001:
[root@cobbler6 files]# awk -F ":" '$NF~/bash$/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
asdfghg:x:503:503::/home/asdfghg:/bin/bash
chujiyw001:x:809:809::/home/chujiyw001:/bin/bash
chujiyw002:x:810:810::/home/chujiyw002:/bin/bash
chujiyw003:x:811:811::/home/chujiyw003:/bin/bash
ywsenior001:x:812:812::/home/ywsenior001:/bin/bash
ywmanager001:x:813:813::/home/ywmanager001:/bin/bash
chujikf001:x:814:814::/home/chujikf001:/bin/bash
chujikf002:x:815:815::/home/chujikf002:/bin/bash
kfsenior001:x:816:816::/home/kfsenior001:/bin/bash
kfmanager001:x:817:817::/home/kfmanager001:/bin/bash
jiak001:x:818:818::/home/jiak001:/bin/bash
jiak002:x:819:819::/home/jiak002:/bin/bash
chjidba001:x:820:820::/home/chjidba001:/bin/bash
chjidba002:x:821:821::/home/chjidba002:/bin/bash
chjidba003:x:822:822::/home/chjidba003:/bin/bash
dbasenior001:x:823:823::/home/dbasenior001:/bin/bash
chjidwg001:x:824:824::/home/chjidwg001:/bin/bash
chjidwg002:x:825:825::/home/chjidwg002:/bin/bash
wgsenior001:x:826:826::/home/wgsenior001:/bin/bas
[root@cobbler6 files]# awk -F "/" '$NF~/^bash$/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
asdfghg:x:503:503::/home/asdfghg:/bin/bash
chujiyw001:x:809:809::/home/chujiyw001:/bin/bash
chujiyw002:x:810:810::/home/chujiyw002:/bin/bash
chujiyw003:x:811:811::/home/chujiyw003:/bin/bash
ywsenior001:x:812:812::/home/ywsenior001:/bin/bash
ywmanager001:x:813:813::/home/ywmanager001:/bin/bash
chujikf001:x:814:814::/home/chujikf001:/bin/bash
chujikf002:x:815:815::/home/chujikf002:/bin/bash
kfsenior001:x:816:816::/home/kfsenior001:/bin/bash
kfmanager001:x:817:817::/home/kfmanager001:/bin/bash
jiak001:x:818:818::/home/jiak001:/bin/bash
jiak002:x:819:819::/home/jiak002:/bin/bash
chjidba001:x:820:820::/home/chjidba001:/bin/bash
chjidba002:x:821:821::/home/chjidba002:/bin/bash
chjidba003:x:822:822::/home/chjidba003:/bin/bash
dbasenior001:x:823:823::/home/dbasenior001:/bin/bash
chjidwg001:x:824:824::/home/chjidwg001:/bin/bash
chjidwg002:x:825:825::/home/chjidwg002:/bin/bash
wgsenior001:x:826:826::/home/wgsenior001:/bin/bash
[root@cobbler6 files]# awk 'NR==2,NR==5{print $1,$3}' awkfile.txt
bin bin
daemon daemon
adm adm
lp lp
1.4.1 正则表达式小结:
1) 模式 ==》条件
2) 正则表达式
3) 条件表达式(NR>=2 NR==2),
4) 范围表达式 NR==2,NR==5)
5) /正则表达式-开始/,/正则结束/
6) $1~/正则表达式-开始/,$3~/正则结束/ 行,记录。
7) 区域:FS刀分隔的,FS区域分隔符
8) 记录:RS刀分隔符,RS记录分隔符
9) FS===>NF区域的数量
10) RS===>NR记录号,随着记录的增加 NR自动+1
7.1 常见的模式类型:
1、Regexp: 正则表达式,格式为/regular expression/
2、expresssion: 表达式,其值非0或为非空字符时满足条件,如:$1 ~ /foo/ 或 $1 == "magedu",用运算符~(匹配)和!~(不匹配)。
3、Ranges: 指定的匹配范围,格式为pat1,pat2
4、BEGIN/END:特殊模式,仅在awk命令执行前运行一次或结束前运行一次
5、Empty(空模式):匹配任意输入行;
2 awk实战基础入门精讲
2.1 BENGIN模块和END模块
BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
END:让用户在最后一条输入记录被读取之后发生的动作。
[root@cobbler6 files]# awk 'BEGIN{print "Hello world!"}'
Hello world!
[root@cobbler6 files]# awk 'BEGIN{RS="/"}{print NF $0}' awkfile2.txt
1root:x:0:0:root:
1root:
1bin
2bash
bin:x:1:1:bin
[root@cobbler6 files]# grep -c "^$" /etc/services
16
[root@cobbler6 files]# awk '/^$/{a=a+1}END{print a}' /etc/services
16
企业案例3:统计文件里面的空行数量
[root@cobbler6 ~]# awk '/^$/{a=a+1;print a}' /etc/services
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@cobbler6 ~]# awk '/^$/{a=a+1}END{print a}' /etc/services
16
sed怎么调试,正则表达式调试
企业面试题4:awkfile2.txt里面 以:为分隔符,区域3大于15行,一共有多少行?
[root@cobbler6 files]# awk -F ":" '$3>15{a++}END{print a}' awkfile2.txt
6
[root@cobbler6 files]# awk -F ":" '$3>15{a++;print a}END{print a}' awkfile2.txt
1
2
3
4
5
6
6
[root@cobbler6 files]# awk -F ":" 'BEGIN{print FS}'
2.1.1 总结:


2.2 预定义变量简介

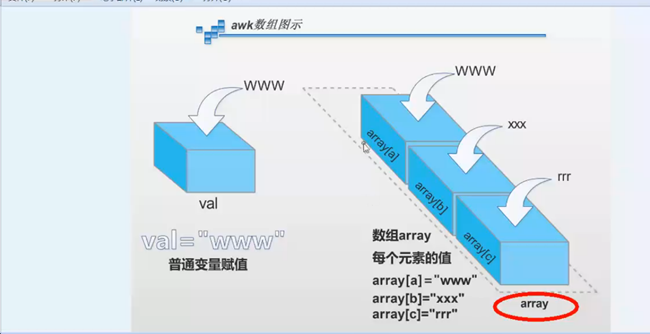
2.3 awk数组

[root@cobbler6 files]# awk 'BEGIN{oldboy["a"]="oldgirl";oldboy["b"]="xiaoyu";oldloy["c"]="oldboy"
print oldboy["a"]
print oldboy["b"]
print oldloy["c"]
}'
oldgirl
xiaoyu
oldboy
awk数组的元素名(苹果名字)可以是字符串
字符串要使用双引号引起来""
[root@cobbler6 files]# awk -F "/" '{array[$3];print $3}' awkfile3.txt
www.etiantian.org
www.etiantian.org
post.etiantian.org
mp3.etiantian.org
www.etiantian.org
post.etiantian.org
[root@cobbler6 files]# awk -F "/" '$3~/www.etiantian.org/' awkfile3.txt
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://www.etiantian.org/3.html
[root@cobbler6 files]# awk -F "/" '$3~/www.etiantian.org/{print $3}' awkfile3.txt
www.etiantian.org
www.etiantian.org
www.etiantian.org
[root@cobbler6 files]# awk -F "/" '$3~/www.etiantian.org/{array[e]}' awkfile3.txt
[root@cobbler6 files]# awk -F "/" '$3~/www.etiantian.org/{array["www.etiantian.org"]++;print array["www.etiantian.org"]}' awkfile3.txt
1
2
3
[root@cobbler6 files]# awk -F "/" '{array[$3]++;print $3,array[$3]}' awkfile3.txt
www.etiantian.org 1
www.etiantian.org 2
post.etiantian.org 1
mp3.etiantian.org 1
www.etiantian.org 3
post.etiantian.org 2
2.3.1 数组总结
- awk数组去重
- 选好分隔符 -F "/"
- 选好处理的区域,print $1,$3,$2
- array[$3]++
- 先处理,最后END模块输出
- 输出awk数组我们使用for(key in arry)
- =>for() 循环
- key in array手去筐里 抓苹果
- key就是苹果名字(框的的名字)
- array数组名(框的名字)
- 打印输出print key,array[key]
3、控制语句:
8.1 if-else
语法:if (condition) {then-body} else {[ else-body ]}
例子:
awk -F: '{if ($1=="root") print $1, "Admin"; else print $1, "Common User"}' /etc/passwd
awk -F: '{if ($1=="root") printf "%-15s: %s\n", $1,"Admin"; else printf "%-15s: %s\n", $1, "Common User"}' /etc/passwd
awk -F: -v sum=0 '{if ($3>=500) sum++}END{print sum}' /etc/passwd
3.2 while
语法: while (condition){statement1; statment2; ...}
awk -F: '{i=1;while (i<=3) {print $i;i++}}' /etc/passwd
awk -F: '{i=1;while (i<=NF) { if (length($i)>=4) {print $i}; i++ }}' /etc/passwd
3.3 do-while
语法: do {statement1, statement2, ...} while (condition)
awk -F: '{i=1;do {print $i;i++}while(i<=3)}' /etc/passwd
3.4 for
语法: for ( variable assignment; condition; iteration process) { statement1, statement2, ...}
awk -F: '{for(i=1;i<=3;i++) print $i}' /etc/passwd
awk -F: '{for(i=1;i<=NF;i++) { if (length($i)>=4) {print $i}}}' /etc/passwd
for循环还可以用来遍历数组元素:
语法: for (i in array) {statement1, statement2, ...}
awk -F: '$NF!~/^$/{BASH[$NF]++}END{for(A in BASH){printf "%15s:%i\n",A,BASH[A]}}' /etc/passwd
3.5 case
语法:switch (expression) { case VALUE or /REGEXP/: statement1, statement2,... default: statement1, ...}
3.6 break 和 continue
常用于循环或case语句中
3.7 next
提前结束对本行文本的处理,并接着处理下一行;例如,下面的命令将显示其ID号为奇数的用户:
# awk -F: '{if($3%2==0) next;print $1,$3}' /etc/passwd
4.4 awk英语

[root@cobbler6 files]# awk '{print NR,$0}' 20-30.txt 50-60.txt
1 20
2 21
3 22
4 23
5 24
6 25
7 26
8 27
9 28
10 29
11 30
12 50
13 51
14 52
15 53
16 54
17 55
18 56
19 57
20 58
21 59
22 60
[root@cobbler6 files]# awk '{print FNR,NR,$0}' 20-30.txt 50-60.txt
1 1 20
2 2 21
3 3 22
4 4 23
5 5 24
6 6 25
7 7 26
8 8 27
9 9 28
10 10 29
11 11 30
1 12 50
2 13 51
3 14 52
4 15 53
5 16 54
6 17 55
7 18 56
8 19 57
9 20 58
10 21 59
11 22 60
5、print
print的使用格式:
print item1, item2, ...
要点:
1、各项目之间使用逗号隔开,而输出时则以空白字符分隔;
2、输出的item可以为字符串或数值、当前记录的字段(如$1)、变量或awk的表达式;数值会先转换为字符串,而后再输出;
3、print命令后面的item可以省略,此时其功能相当于print $0, 因此,如果想输出空白行,则需要使用print "";
例子:
# awk 'BEGIN { print "line one\nline two\nline three" }'
awk -F: '{ print $1, $3 }' /etc/passwd
6、printf
printf命令的使用格式:
printf format, item1, item2, ...
要点:
1、其与print命令的最大不同是,printf需要指定format;
2、format用于指定后面的每个item的输出格式;
3、printf语句不会自动打印换行符;\n
format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码; %d, %i:十进制整数; %e, %E:科学计数法显示数值; %f: 显示浮点数; %g, %G: 以科学计数法的格式或浮点数的格式显示数值; %s: 显示字符串; %u: 无符号整数; %%: 显示%自身;
修饰符:
N: 显示宽度; -: 左对齐; +:显示数值符号;
例子:
# awk -F: '{printf "%-15s %i\n",$1,$3}' /etc/passwd
7、输出重定向
print items > output-file print items >> output-file print items | command
特殊文件描述符:
/dev/stdin:标准输入 /dev/sdtout: 标准输出 /dev/stderr: 错误输出 /dev/fd/N: 某特定文件描述符,如/dev/stdin就相当于/dev/fd/0;
例子:
# awk -F: '{printf "%-15s %i\n",$1,$3 > "/dev/stderr" }' /etc/passwd
7、awk的操作符:
7.1 算术操作符:
-x: 负值 +x: 转换为数值; x^y: x**y: 次方 x*y: 乘法 x/y:除法 x+y: x-y: x%y:
7.2 字符串操作符:
只有一个,而且不用写出来,用于实现字符串连接;
7.3 赋值操作符:
= += -= *= /= %= ^= **= ++ --
需要注意的是,如果某模式为=号,此时使用/=/可能会有语法错误,应以/[=]/替代;
7.4 布尔值
awk中,任何非0值或非空字符串都为真,反之就为假;
7.5 比较操作符:
x < y True if x is less than y. x <= y True if x is less than or equal to y. x > y True if x is greater than y. x >= y True if x is greater than or equal to y. x == y True if x is equal to y. x != y True if x is not equal to y. x ~ y True if the string x matches the regexp denoted by y. x !~ y True if the string x does not match the regexp denoted by y. subscript in array True if the array array has an element with the subscript subscript.
7.7 表达式间的逻辑关系符:
&&
||
7.8 条件表达式:
selector?if-true-exp:if-false-exp if selector; then if-true-exp else if-false-exp fi a=3 b=4 a>b?a is max:b ia max
7.9 函数调用:
function_name (para1,para2)
生产常用功能总结
1、显示出某个范围内的内容
awk 'NR==20,NR==30' fliename
2、通过awk统计计算
awk '{sum+=$0}END{print sum}'
3、awk数组计算与去重
awk '{array[$1]++}END{for(key in array)print key,array[key]}' access.log
awk -F: '{if ($1=="root") print $1, "Admin"; else print $1, "Common User"}' /etc/passwd
root Admin
bin Common User
daemon Common User
awk -F: '{if ($1=="root") printf "%-15s: %s\n", $1,"Admin"; else printf "%-15s: %s\n", $1, "Common User"}' /etc/passwd
root : Admin
bin : Common User
daemon : Common User
awk -F: -v sum=0 '{if ($3>=500) sum++}END{print sum}' /etc/passwd
4、awk 实现给文件的每行内容之前加上行号
awk '{print NR,$0}'
5、显示第二到第六行
awk 'NR==2,NR==6 {print NR,$0}'
6、替换功能
awk '{gsub("/sbin/nologin","/bin/bash",$0);print $0}'
awk '{gsub("替换对象","替换成什么内容",那一列);print $0}'
注意:
- gsub与后面的括号之间不能有空格
- 替换对象、替换成什么内容以及那一列之间要用逗号隔开
- 替换队形的外面要有双引号或双斜线包裹起来,即"替换对象"或/替换对象/
- 替换成什么内容就只能用双引号括起来了,即"替换成什么内容"
- 最后一个是那一列,这个是可以省略的,省略的时候表示要替换整行的内容,相当于写上$0
八、常见awk用法
##提取两个文件第一列相同的行
awk -F',' 'NR==FNR{a[$1]=$0;next}NR>FNR{if($1 in a)print $0"\n"a[$1]}' 1.log 2.log
awk 'NR==FNR{a[$1]++}NR>FNR&&a[$1]>1' 111.txt 111.txt
awk 'a[$1]++==1'
cat 111.txt | awk -F '[:|]' '{print $2}' > 111.txt
##awk 按某个位置的字符分隔的方法
awk -F ":" '{ for(i=1;i<=3;i++) printf("%s:",$i)}'
awk -F':' '{print $1 ":" $2 ":" $3; print $4}'
awk -F':' '{print $1 ":" $2 ":" $3; for(i=1;i<=3;i++)$i=""; print}'
##awk打印用户和密码
cat test.log |awk -F '[ ]+' '{print $1 " " $2}'
##排序显示重复项目
cat test.log |awk -F '[ ]+' '{print $1}'| sort | uniq -c | sort -nr
#awk -F '\t'来表示分隔符,比如
awk -F '\t' '{print $1}' file1.txt
##多个空格分隔的方法
awk -F '[ ]+' '{print $9}'
ls -lh /etc/sysconfig/network-scripts/ifcfg-* | awk -F '[ ]+' '{print $9}'
##指定分隔符既可以为空格,又可以为冒号,那么处理将会变得简单。可以使用正则表达式来指定多个分隔符,格式为 -F'[空格:]+' 如下
awk -F'[ :]+' '{print $NF"\t"$(NF-2)}' file1.txt
1、awk '/101/' file 显示文件file中包含101的匹配行。
awk '/101/,/105/' file
awk '$1 == 5' file
awk '$1 == "CT"' file 注意必须带双引号
awk '$1 * $2 >100 ' file
awk '$2 >5 && $2<=15' file
2、awk '{print NR,NF,$1,$NF,}' file 显示文件file的当前记录号、域数和每一行的第一个和最后一个域。
awk '/101/ {print $1,$2 + 10}' file 显示文件file的匹配行的第一、二个域加10。
awk '/101/ {print $1$2}' file
awk '/101/ {print $1 $2}' file 显示文件file的匹配行的第一、二个域,但显示时域中间没有分隔符。
3、df | awk '$4>1000000 ' 通过管道符获得输入,如:显示第4个域满足条件的行。
4、awk -F "|" '{print $1}' file 按照新的分隔符“|”进行操作。
awk 'BEGIN { FS="[: \t|]" }
{print $1,$2,$3}' file 通过设置输入分隔符(FS="[: \t|]")修改输入分隔符。
Sep="|"
awk -F $Sep '{print $1}' file 按照环境变量Sep的值做为分隔符。
awk -F '[ :\t|]' '{print $1}' file 按照正则表达式的值做为分隔符,这里代表空格、:、TAB、|同时做为分隔符。
awk -F '[][]' '{print $1}' file 按照正则表达式的值做为分隔符,这里代表[、]
5、awk -f awkfile file 通过文件awkfile的内容依次进行控制。
cat awkfile
/101/{print "\047 Hello! \047"} --遇到匹配行以后打印 ' Hello! '. \047代表单引号。
{print $1,$2} --因为没有模式控制,打印每一行的前两个域。
6、awk '$1 ~ /101/ {print $1}' file 显示文件中第一个域匹配101的行(记录)。
7、awk 'BEGIN { OFS="%"}
{print $1,$2}' file 通过设置输出分隔符(OFS="%")修改输出格式。
8、awk 'BEGIN { max=100 ;print "max=" max} BEGIN 表示在处理任意行之前进行的操作。
{max=($1 >max ?$1:max); print $1,"Now max is "max}' file 取得文件第一个域的最大值。
(表达式1?表达式2:表达式3 相当于:
if (表达式1)
表达式2
else
表达式3
awk '{print ($1>4 ? "high "$1: "low "$1)}' file
9、awk '$1 * $2 >100 {print $1}' file 显示文件中第一个域匹配101的行(记录)。
10、awk '{$1 == 'Chi' {$3 = 'China'; print}' file 找到匹配行后先将第3个域替换后再显示该行(记录)。
awk '{$7 %= 3; print $7}' file 将第7域被3除,并将余数赋给第7域再打印。
11、awk '/tom/ {wage=$2+$3; printf wage}' file 找到匹配行后为变量wage赋值并打印该变量。
12、awk '/tom/ {count++;}
END {print "tom was found "count" times"}' file END表示在所有输入行处理完后进行处理。
13、awk 'gsub(/\$/,"");gsub(/,/,""); cost+=$4;
END {print "The total is $" cost>"filename"}' file gsub函数用空串替换$和,再将结果输出到filename中。
1 2 3 $1,200.00
1 2 3 $2,300.00
1 2 3 $4,000.00
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>1000&&$4<2000) c1+=$4;
else if ($4>2000&&$4<3000) c2+=$4;
else if ($4>3000&&$4<4000) c3+=$4;
else c4+=$4; }
END {printf "c1=[%d];c2=[%d];c3=[%d];c4=[%d]\n",c1,c2,c3,c4}"' file
通过if和else if完成条件语句
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>3000&&$4<4000) exit;
else c4+=$4; }
END {printf "c1=[%d];c2=[%d];c3=[%d];c4=[%d]\n",c1,c2,c3,c4}"' file
通过exit在某条件时退出,但是仍执行END操作。
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>3000) next;
else c4+=$4; }
END {printf "c4=[%d]\n",c4}"' file
通过next在某条件时跳过该行,对下一行执行操作。
14、awk '{ print FILENAME,$0 }' file1 file2 file3>fileall 把file1、file2、file3的文件内容全部写到fileall中,格式为
打印文件并前置文件名。
15、awk ' $1!=previous { close(previous); previous=$1 }
{print substr($0,index($0," ") +1)>$1}' fileall 把合并后的文件重新分拆为3个文件。并与原文件一致。
16、awk 'BEGIN {"date"|getline d; print d}' 通过管道把date的执行结果送给getline,并赋给变量d,然后打印。
17、awk 'BEGIN {system("echo \"Input your name:\\c\""); getline d;print "\nYour name is",d,"\b!\n"}'
通过getline命令交互输入name,并显示出来。
awk 'BEGIN {FS=":"; while(getline< "/etc/passwd" >0) { if($1~"050[0-9]_") print $1}}'
打印/etc/passwd文件中用户名包含050x_的用户名。
18、awk '{ i=1;while(i<NF) {print NF,$i;i++}}' file 通过while语句实现循环。
awk '{ for(i=1;i<NF;i++) {print NF,$i}}' file 通过for语句实现循环。
type file|awk -F "/" '
{ for(i=1;i<NF;i++)
{ if(i==NF-1) { printf "%s",$i }
else { printf "%s/",$i } }}' 显示一个文件的全路径。
用for和if显示日期
awk 'BEGIN {
for(j=1;j<=12;j++)
{ flag=0;
printf "\n%d月份\n",j;
for(i=1;i<=31;i++)
{
if (j==2&&i>28) flag=1;
if ((j==4||j==6||j==9||j==11)&&i>30) flag=1;
if (flag==0) {printf "%02d%02d ",j,i}
}
}
}'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号