ELKStack 实战之 Elasticsearch [一]
没有日志分析系统
1.1运维痛点
1.运维要不停的查看各种日志。
2.故障已经发生了才看日志(时间问题。)
3.节点多,日志分散,收集日志成了问题。
4.运行日志,错误等日志等,没有规范目录,收集困难。
1.2环境痛点
1.开发人员不能登陆线上服务器查看详细日志。
2.各个系统都有日志,日志数据分散难以查找。
3.日志数据量大,查询速度慢,数据不够实时。
1.3解决痛点
1.收集(Logstash)
2.存储(Elasticsearch、Redis、Kafka)
3.搜索+统计+展示(Kibana)
4.报警,数据分析(Zabbix)
ELKStack简介
ELK Stack 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用,而且又都先后归于 Elastic.co 公司名下,故有此简称。
ELK Stack 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,ELK Stack 具有如下几个优点:
• 处理方式灵活。Elasticsearch 是实时全文索引,不需要像 storm 那样预先编程才能使用;
• 配置简易上手。Elasticsearch 全部采用 JSON 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
• 检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
• 集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
• 前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
ELK地址:https://www.elastic.co/
Logstash 最佳实践:http://udn.yyuap.com/doc/logstash-best-practice-cn/index.html
Elasticsearch 权威指南:http://www.learnes.net/index.html
ELKStack中文社区:https://kibana.logstash.es/content/
对于日志来说,最常见的需求就是收集、存储、查询、展示,开源社区正好有相对应的开源项目:logstash(收集)、elasticsearch(存储+搜索)、kibana(展示),我们将这三个组合起来的技术称之为ELKStack,所以说ELKStack指的是Elasticsearch(java)、Logstash(jruby)、Kibana技术栈的结合,一个通 用的架构如下图所示: 
图片解释:elk 前面主要靠logstash来进行收集日志,logstash将日志上传到broker上,后面还有一个logstash用来读取broker中的日志,在将日志存储到es里面,最后用kibana练到es上进行展示
提示:我们可以将Elasticsearch简称为es
Elasticsearch介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Elasticsearch部署
Elasticsearch首先需要Java环境,所以需要提前安装好JDK,可以直接使用yum安装。也可以从Oracle官网下载JDK进行安装。开始之前要确保JDK正常安装并且环境变量也配置正确:
环境介绍
[root@abcdocker ~]# [root@abcdocker ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda1 20G 2.4G 18G 12% / devtmpfs 903M 0 903M 0% /dev tmpfs 912M 0 912M 0% /dev/shm tmpfs 912M 8.6M 904M 1% /run tmpfs 912M 0 912M 0% /sys/fs/cgroup tmpfs 183M 0 183M 0% /run/user/0 [root@abcdocker ~]# free -m total used free shared buff/cache available Mem: 1823 328 1113 8 381 1322 Swap: 0 0 0 [root@abcdocker ~]# cat /etc/redhat-release CentOS Linux release 7.3.1611 (Core) 本次使用2台服务器来进行模拟集群,所以请准备2台服务器
安装JDK
[root@linux-node1 ~]# yum install -y java [root@linux-node1 ~]# java -version openjdk version "1.8.0_65" OpenJDK Runtime Environment (build 1.8.0_65-b17) OpenJDK 64-Bit Server VM (build 25.65-b01, mixed mode)
源码安装JDK
下载安装http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 配置Java环境 # tar zxf jdk-8u91-linux-x64.tar.gz -C /usr/local/ # ln –s /usr/local/jdk1.8.0_91 /usr/local/jdk # vim /etc/profile export JAVA_HOME=/usr/local/jdk export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin # source /etc/profile 看到如下信息,java环境配置成功 # java -version java version "1.8.0_91" Java(TM) SE Runtime Environment (build 1.8.0_91-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
配置安装ElasticSearch
可以使用源码,或者yum
一、yum安装
1.下载并安装GPG key [root@linux-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch 2.添加yum仓库 [root@linux-node1 ~]# cat /etc/yum.repos.d/elasticsearch.repo [elasticsearch-2.x] name=Elasticsearch repository for 2.x packages baseurl=http://packages.elastic.co/elasticsearch/2.x/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1 3.安装elasticsearch [root@hadoop-node1 ~]# yum install -y elasticsearch
二、源码安装
[root@CentOS6 home]# wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.2.tar.gz #下载elasticsearch [root@CentOS6 home]# tar xf elasticsearch-1.7.2.tar.gz -C /usr/local/ #解压elasticsearch [root@CentOS6 home]# ln -s /usr/local/elasticsearch-1.7.2 /usr/local/elasticsearch #创建软连接
三、配置elasticsearch
修改配置文件 [root@abcdocker ~]# vim /etc/elasticsearch/elasticsearch.yml cluster.name: myes #ES集群名称 node.name: abcdocker-node-1 #节点名称 path.data: /data/es-date #数据存储的目录(多个目录使用逗号分隔) path.logs: /var/log/elasticsearch #日志格式 bootstrap.memory_lock: true #锁住es内存,保证内存不分配至交换分区 network.host: 192.168.56.11 #设置本机IP地址 http.port: 9200 #端口默认9200
四、设置数据目录权限
[root@abcdocker ~]# chown -R elasticsearch:elasticsearch /data/es-date/ #这个是我们存放数据的目录,手动创建
es默认发现有组播和单播,组播就是都加入到一个组里面,单播就是一对一通信
提示: yum安装时会少了许多配置,如果编译安装就会产生很多。
五、启动
启动es [root@abcdocker ~]# systemctl start elasticsearch.service [root@abcdocker ~]# netstat -lntup Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 532/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 724/master tcp6 0 0 192.168.56.11:9200 :::* LISTEN 2125/java tcp6 0 0 192.168.56.11:9300 :::* LISTEN 2125/java tcp6 0 0 :::22 :::* LISTEN 532/sshd tcp6 0 0 ::1:25 :::* LISTEN 724/master 端口默认:9200
本次环境我们使用2台服务器,这2台服务器的服务搭建可以跟上面的步骤相同即可
访问测试:http://IP:9200 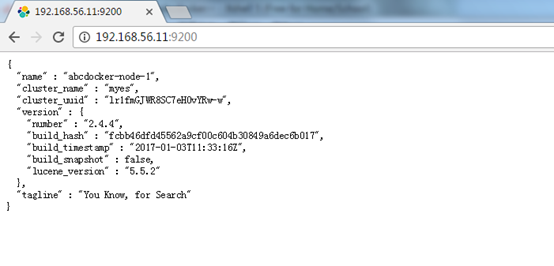
Elasticsearch提供了非常多的插件,还可以使用curl进行通讯
我们可以使用curl来查看es里面有什么内容
[root@abcdocker ~]# curl -i -XGET 'http://192.168.56.11:9200/_count?'
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 59
{"count":0,"_shards":{"total":0,"successful":0,"failed":0}}[
解释:
返回头部200,执行成功0个,返回0个
Elasticsearch有很多插件,但是有的插件好用但是收费
Elasticsearch插件介绍
一、Haed插件
插件作用:主要是做es集群管理的插件
Github下载地址:https://github.com/mobz/elasticsearch-head
下载方式: [root@abcdocker ~]# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head -> Installing mobz/elasticsearch-head... Trying https://github.com/mobz/elasticsearch-head/archive/master.zip ... Downloading ...................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE Verifying https://github.com/mobz/elasticsearch-head/archive/master.zip checksums if available ... NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify) Installed head into /usr/share/elasticsearch/plugins/head 下载完会在/usr/share/elasticsearch/plugins/目录下产生插件目录
访问:http://ip地址:9200/_plugin/head/ 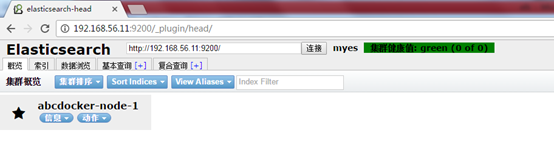
二、Bigdesk插件
插件作用:性能监控
Github下载:https://github.com/lukas-vlcek/bigdesk
提示:因为我们使用yum安装的最新版本,bigdesk暂时不支持最新版本
[root@abcdocker ~]# /usr/share/elasticsearch/bin/elasticsearch -V OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N Version: 2.4.4, Build: fcbb46d/2017-01-03T11:33:16Z, JVM: 1.8.0_121
正常访问地址:http://localhost:9200/_plugin/bigdesk/
Bigdesk 1.x 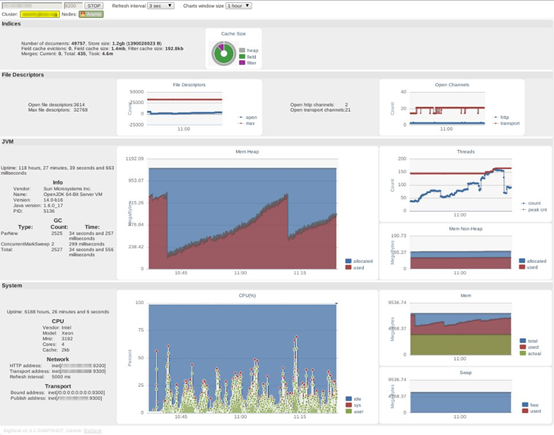
Bigdesk 2.X 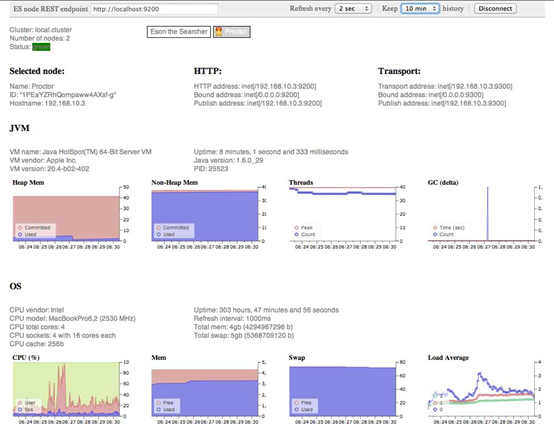
三、Kopf插件
插件作用:kopf是一个简单的网络管理工具
Kopf不再维护。已经开发了替代品(cerebro),目前维护在https://github.com/lmenezes/cerebro。在这一点上,cerebro应该有相当于kopf的功能,顶部有一些新的功能。
Github地址:https://github.com/lmenezes/elasticsearch-kopf
安装 [root@abcdocker ~]# /usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf -> Installing lmenezes/elasticsearch-kopf... Trying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip ... Downloading ................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE Verifying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip checksums if available ... NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify) Installed kopf into /usr/share/elasticsearch/plugins/kopf
访问地址:http://192.168.56.11:9200/_plugin/kopf/ 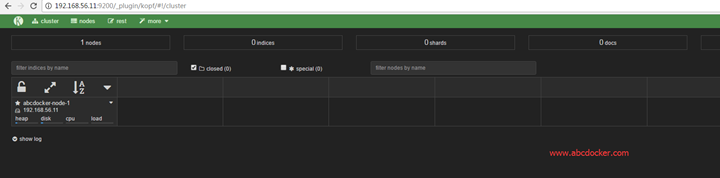
插件使用
1、Head插件使用介绍
现在我们已经将插件安装完成,这时候里面还没有数据。我们现在往里面写一些数据 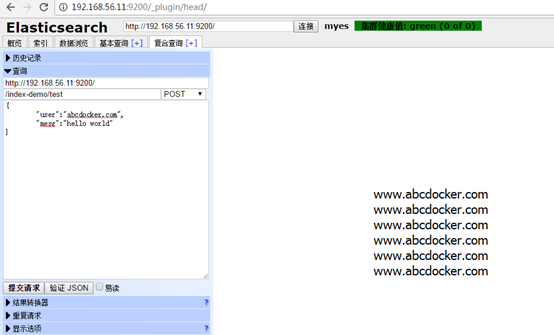
点击提交
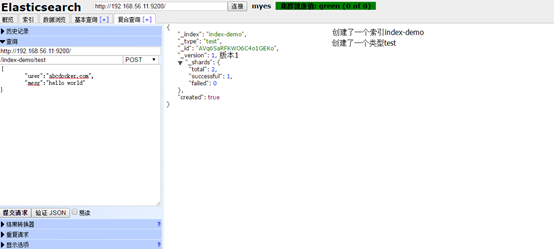
_index:创建了一个索引index-demo
_type:创建了一个类型test
total:分片2个
Successful:成功1个
Failed:失败0个
Created:状态成功
我们点击概览,点击连接 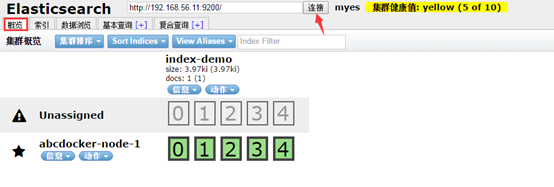
我们写一篇文档会帮我们分成5片(0-4,可以修改成多个),粗线代表主分片细线代表副本分片(可以理解为一主一备)正常情况下会将主分片和副本分片放在2台机器上
集群健康值介绍:
黄色代表没有主分片数据丢失,但是现在不是健康的状态(警告)应该有10个分片,现在只有5个。
红色代表有数据丢失
绿色代表正常
提示:es支持一个类似于快照的功能,方便我们用于数据备份
Es索引信息 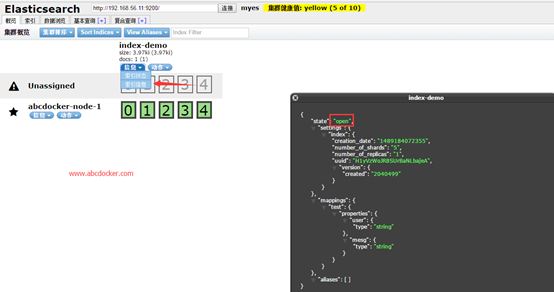
这里索引信息是open代表我们可以将它给关闭掉,这样就不会继续使用这个索引进行搜索 
关闭索引 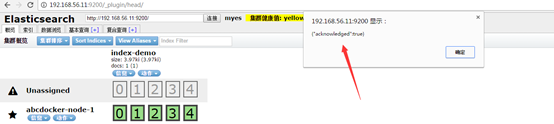
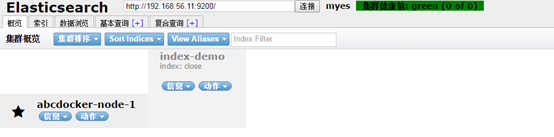
除了支持关闭和开启索引,同样也支持删除 
提示:删除之后索引数据是无法恢复的
Head插件小缺点: 当我们索引特别多的时候,打开head至少需要五分钟。因为它要把所有的索引都扫描一遍进行展示,这时候打开使用的带宽也会特别大(不会出现超时,一直等待就可以)
2、kopf插件使用介绍
访问地址:http://192.168.56.11:9200/_plugin/kopf/ 
我们可以看到索引、分片、文档数量、大小以及jvm使用情况、disk、cpu、load等 
我们点击节点,就可以看到更详细的硬件信息(实时变化) 
同样kopf也支持head的插件,支持请求
(生产场景这个信息主要给开发使用) 
提示:es是有自己的查询语言,可以写的很复杂。
其他功能 
▲ Create index: 创建索引:
▲ Cluster settings: 集群设置:
▲ Aliases: 别名:
▲ Analysis: 分析:
▲ Percolator: 过滤器:
▲ Snapshot: 快照
▲ Index templates: 索引模板:
▲ Cat apis: api
▲ Hot threads: 热线程:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号