二次开发:Zabbix 对数据存储
数据存储简介
通过前面的学习,我们知道了Zabbix-Server 将采集到的数据存储在数据库中,我们也了解到数据存储的大小与每秒处理的数据量有关,所以数据存储取决于以下两个因素。
Number of processed values per second(每秒处理的数据值):更新数据。
Housekeeper 的设置:删除数据。
Zabbix-Server 将采集到的数据主要存储在History 和Trends 表中,其表结构中的数据类型如表3-7 所示。
表3-7
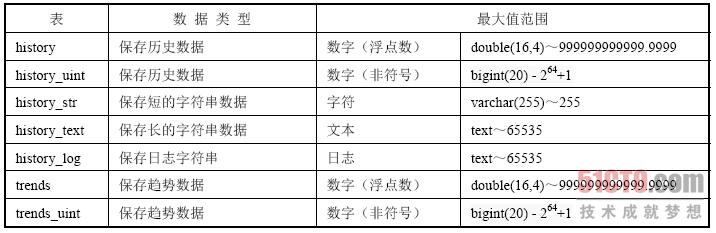
另外,acknowledges、alerts、auditlog、events 和service_alarms 表的数据也较大,故后文所提到的分表也会对这几个表进行区间划分。
在History 表中,主要存储收集到的历史数据,而Trends 主要存储经过计算的历史数据,如每小时数据的最小值、最大值和平均值。
History 的图像数据如图3-35 所示,读取的是History 表中的数据,图中的数据是每分钟(取决于数据采集的周期)的历史记录数据。
关于监控数据在前台页面的展示,读者可以通过分析PHP 源码看到其实现过程(源码文件名是include/graphs.inc. php)。

Trends 的图像数据如图3-36 所示,读取的是Trends 表中的数据,图中的数据是每三个小时的平均数据图。

Trends 数据的存储有以下两个数据表。
Trends(存储浮点数据类型)。
trends_unit(存储非符号的整数)。
这两个表中都包含:最小值(value_min)、最大值(value_max)和平均值(value_avg)。
下面看看Trends 表,其创建表的语句如下。
mysql> show create table trends\G; *************************** 1. row *************************** Table: trends Create Table: CREATE TABLE `trends` ( `itemid` bigint(20) unsigned NOT NULL, `clock` int(11) NOT NULL DEFAULT '0', `num` int(11) NOT NULL DEFAULT '0', `value_min` double(16,4) NOT NULL DEFAULT '0.0000', `value_avg` double(16,4) NOT NULL DEFAULT '0.0000', `value_max` double(16,4) NOT NULL DEFAULT '0.0000', PRIMARY KEY (`itemid`,`clock`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
同时,还有一个表trends_uint,其创建表的语句如下。
同样,History 也有以下几个表。
history:浮点数据。
history_log:日志。
history_str:字符串,255 个字符限制。
history_text:文本,不限制长度。
history_uint:无符号整数。
History 表结构
History 表结构如图3-37 至图3-39 所示。

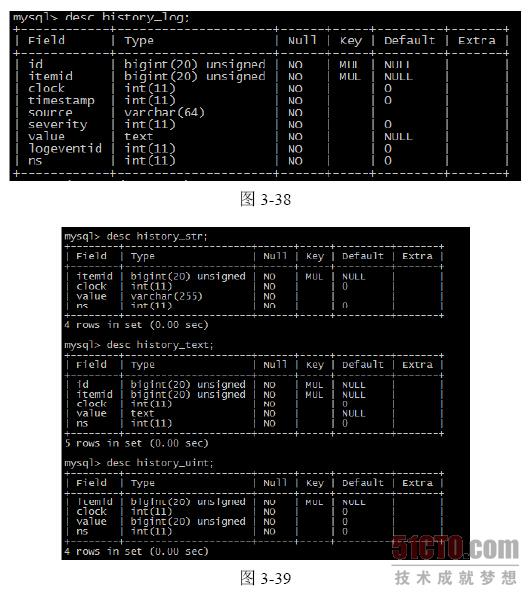
在表3-8 中,对History 的常用字段进行了说明。
表3-8

在本章的前面,我们已经学习了如何计算数据库的大小,基本上可以估算出Zabbix-Server 的数据库会占用多大,但随着Zabbix 数据库的增大,问题随之而来。
对于超过存储期限的数据,Zabbix-Server 用Housekeeper 进程进行数据清理,读者可以分析源代码了解其实现过程(如图3-40 所示),代码位置如下:
src/zabbix_server/housekeeper/housekeeper.c

通过分析源代码,我们知道了Zabbix-Server 对数据的清理主要是通过DELETE 的SQL 语句来执行删除动作。随着数据存储的越来越多,其执行效率会显著下降,有经验的读者都知道,在一个千万级、亿万级的表中执行一条DELETE的SQL 语句,少则几十秒,多则几十分钟才能够完成,所以Housekeeper 程序执行的SQL 语句会严重影响DB 的性能,从而导致数据库会成为整个监控系统的性能瓶颈。
对于很大的表,SQL 优化的方案中最常见的方式有横向扩展和纵向扩展,这两种方式中,一是用足够好的硬件,二是将数据进行分布式,而分表可以看作是分布式的一种,即按一定的规则将数据划分区间,从而避免全表扫描所带来的性能损失,最大程度地提高了性能。在这里采取的就是对表区间进行划分。
下面来看一个在线的Zabbix 数据库中History 表数据量的大小(见图3-41)。
mysql> select table_name, (data_length+index_length)/1024/1024 as total_mb, table_rows from information_schema.tables where table_ schema='zabbix';
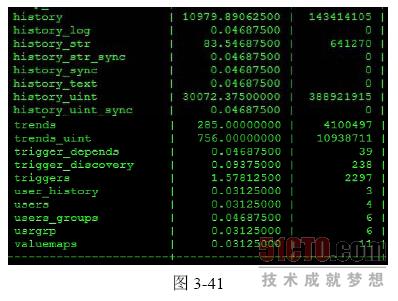
在history_uint 表中,数据达到3.8 亿条,如果在这个表中执行DELETE 的SQL 语句,其速度是可想而知的。
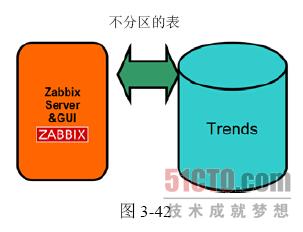
Trends分表
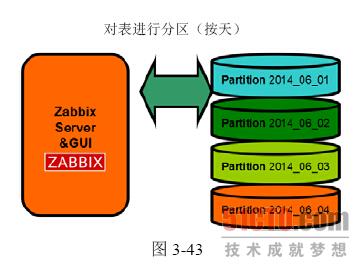
在了解对Zabbix 的数据库进行分表的必要性之后,下面介绍如何划分表的区间。首先,对Trends 表(见图3-42)进行区间划分,这里分区的标准是按天进行划分的(见图3-43)。
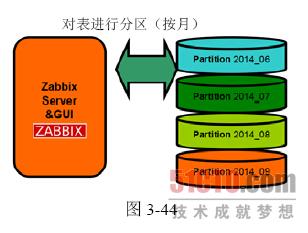
如果数据量不是特别大,也可以按月进行划分(见图3-44)。
采用表分区后,需要关闭Housekeeper 的功能,此时如果需要清理历史数据,只需要对表区间对应的历史期限数据进行删除即可。
注意,对于Housekeeper 进程的关闭,可以在Zabbix 2.0 的zabbix_server.conf中设置,设置完成后,重启zabbix_server 服务,即可使修改后的配置生效。
### Option: DisableHousekeeping # If set to 1, disables housekeeping. # # Mandatory: no # Range: 0-1 DisableHousekeeping=1(值设置为1,关闭)
在Zabbix 2.2 中,zabbix_server.conf 没有这个可配置的参数,Zabbix 2.2 的housekeeper 是在Web 界面中进行的配置(见图3-45)。
在Web 页面中,依次找到Administration→General→Housekeeper,去掉勾选状态,即可关闭History 和Trends 的housekeeper 功能。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号