re模块逐步进阶
Windows 10家庭中文版,Python 3.6.4,
正则表达式,自己一直的水平是 知道,但不熟悉,简单的也能写,复杂的就需要看资料了,距离灵活运用还是差那么一些的。
于是,今天(180831)来好好研究下正则表达式模块的使用。
教程:
2.Python 3官方文档之re — Regular expression operations (最新的3.7)
说明,两者都有丰富的示例可以练习。
上面的教程2自然要比教程1更丰富,从英文的角度来说,也介绍的更清楚。
但是,教程1是中文的,对于咱们来说,更容易上手,遇到难点了,再去看教程2——需要足够好的英文水平。
不过, 教程2也是不完整的,执行dir(re),发现其中存在template(pattern, flags=0)函数,可教程2中没有提及,只是在Match Objects的expand()函数中有用到(之前看过书——Python的基础教程,好像,这个template功能好像挺有用的,需要dig)。

因此,在完成教程1、2的学习后,更进一步进阶就需要仔细研究模块了。
当然,完成教程1、2的学习且熟悉后,大部分需要使用正则表达式的情景都不会存在问题了。
----
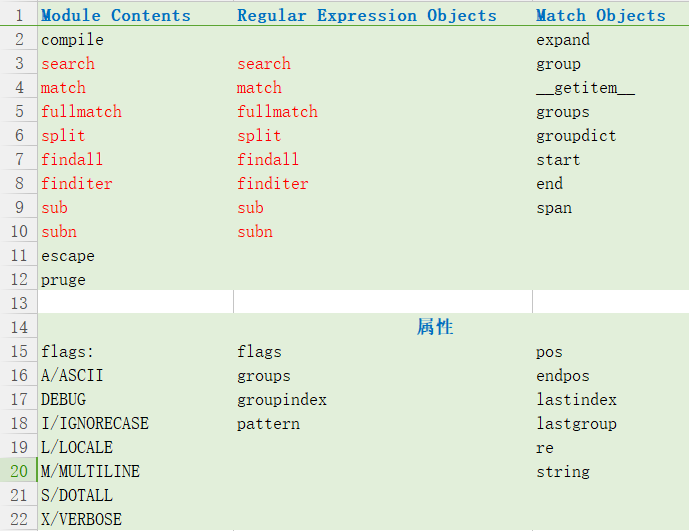
re模块中有两个主要的对象:Regular Expression Objects、Match Objects,开发者通过使用 模块本身提供的函数,以及 这两个对象各自的方法 来解决问题。
针对三者的函数、方法,下表做了一个简单的整理:
其中,模块本身提供的函数 和 Regular Expression Objects 下的方法存在重叠之处,,猜测:两者的功能应该是相同的,具体使用哪种,取决于自己的使用场景。
还有模块级别常量,主要是flags了,自己目前可能就知道I、M是什么意思吧,其它的还需要dig。
180901续
教程1要点复习:
1.re.compile用于基于 正则表达式 字符串 来编译生产 正则表达式对象,如上面的表格所示,可以使用 正则表达式对象完成 相关操作;
2.正则表达式对象 也可以作为re.search()、re.match()的参数,和直接使用 正则表达式字符串 具有相同的效果;
3.re.match(pattern, string, flags=0)
尝试从字符串的【起始位置】匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
4.re.search(pattern, string, flags=0)
扫描整个字符串并返回第一个成功的匹配。
若找到,返回一个_sre.SRE_Match对象,没有找到返回为空。
>>> m = re.search('\d', '一二三2342', re.U)
>>> type(m)
<class '_sre.SRE_Match'>
_sre.SRE_Match对象有下面的可用函数(标记为红色为常用):
'endpos', 'expand', 'group', 'groupdict', 'groups',
'lastgroup', 'lastindex', 'pos', 're', 'regs', 'span', 'start', 'string'
5.Quote:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
6.re.sub(pattern, repl, string, count=0)
替换字符串中的匹配项。repl可以是函数,具体用法需要dig。
教程2还有re.subn(pattern, repl, string, count=0, flags=0)。
7.re.search是查找 第一个匹配,那么,re.findall、re.finditer则是返回 所有匹配子串 的列表,是列表!
感觉这两个find*函数更有用吧?是否会将(...)的匹配子串也放到列表中呢?
下面是三组测试:
>>> restr = '(\d+)' # 测试1:末尾无空格 >>> m = re.search(restr, 'this is 123 and this is 456') >>> m.group() '123' >>> m.groups() ('123',) >>> re.findall(restr, 'this is 123 and this is 456') ['123', '456'] >>> m.group(1) '123' >>> >>> restr = '(\d+) ' # 测试2:末尾有空格 >>> m = re.search(restr, 'this is 123 and this is 456') >>> m.group() '123 ' >>> m.groups() ('123',) >>> re.findall(restr, 'this is 123 and this is 456') ['123'] >>> >>> restr = '\d+ ' # 测试3:末尾有空格,去掉了括号 >>> m = re.search(restr, 'this is 123 and this is 456') >>> m.group() '123 ' >>> m.groups() () >>> re.findall(restr, 'this is 123 and this is 456') ['123 ']
8.re.split(pattern, string[, maxsplit=0, flags=0])
按照能够匹配的子串将字符串分割后返回列表。
教程2学习笔记
前面认真看了教程2,其中不少知识点刷新了自己对正则表达式及其使用的认知。
1.re模块中的正则表达式操作 和 Perl中的很类似;
2.字符串的正则表达式操作涉及两个元素:正则表达式、被搜索的字符串。两者都可能是 Unicode strings (str) 或者 8-bit strings (bytes) 模式中的一种,但是 正则表达式 和 被搜索的字符串的 模式必须相同!
3.正则表达式中使用 反斜杠(\)、Python也使用反斜杠表达一些特殊字符,因此,两者可能存在冲突。比如,要表示一个 在 正则表达式中用的 反斜杠字符,就需要写为 "\\\\"——四个反斜杠。怎么解决呢?使用Python的原始字符串(raw string),即在字符串前面添加r,比如前面的 "\\\\" 可以简写为 r"\\"。
>>> '\\'
'\\'
>>> '\\\\'
'\\\\'
>>> r'\\'
'\\\\'
>>> len('\\')
1
>>> len(r'\\')
2
>>> len('\n')
1
>>> len(r'\n')
2
4.在上文,孤猜测 模块级别的re.functions()函数 和 Regular Expression Objects的函数功能差不多,可 教程2 中提到,这些模块级别的函数只是一些快捷方法,省去了编译正则表达式对象的步骤,可同时还缺失了一些微调参数(fine-tuning parameters)。
5.教程2还提到,re是Python官方的标准模块,还有一个第三方的regex模块,完全兼容re模块,更强大,有更多功能,对Unicode 字符串提供了更彻底的支持,其PYPI地址。预计又要花费大量精时了,短期不会考虑它,毕竟,re模块足够自己用了。
----0901 1121----lunch time----
0901 1241继续
教程2分为5部分,其中,第一节Regular Expression Syntax是其中的重难点;
Module Contents、Regular Expression Objects、Match Objects三小节的内容在教程1中有所介绍,只是教程1比较简明,没有讲完全,也有些地方没有讲透;
最后一节Regular Expression Examples讲使用re模块的使用实例了,需要好好看看。
下面介绍第一节Regular Expression Syntax的学习笔记,其它四部分,读者请阅读教程2——更详细的官文。
6.正则表达式可以简单地 连接起来(be concatenated),re A、re B,可以连接为re AB,但这是有条件的:A、B必须是 简单的re。什么情况下是不简单呢?
1)不包含低优先级操作(孤不太理解这个);2)在A、B之间不包含边界条件;3)不包含 \numbered 组应用(numbered group references);
抱歉翻译的不很准确,原文如下:
This holds unless A or B contain low precedence operations; boundary conditions between A and B; or have numbered group references.
7.正则表达式 包含 普通字符、特殊字符。特殊字符有两大作用:
1)表示一类普通字符(class);2)影响正则表达式如何被解释(interpreted);
8.重复限定符 (*, +, ?, {m,n}等) 不能被直接嵌套使用,,在重复限定符 的 末尾 添加问号(?)可以防止贪婪模式(greedy),,还可以在其它实现中添加其它调试语,,在内部重复限定符添加圆括号包含后,可以再次使用重复限定符,比如,(?:a{6})*;
9.简单的特殊字符在很多地方都有介绍,若是有正则表达式基础的话,应该会了解,下面对其中一些做特别介绍
1)点号(.)
也是英文句号,表示 除换行符外的任意字符,进阶:和标记re.DOTALL组合时表示 包括换行符在内的所有字符,简言之,代表 所有字符。
2)脱字符(^)
表示字符串的开始,进阶:和标记re.MULTILINE组合时,表示每一个换行符后的开始位置。
3)美元符号($)
表示字符串的结尾,进阶:和标记re.MULTILINE组合时,表示每一个换行符前的位置。更多特性请参考官文的介绍——教程2、3,在写复杂re时很重要。
4)重复限定符:星号(*)匹配0个或更多,加号(+)匹配1个或更多,问号(?)比匹配0个或1个,,注意,默认都是贪婪模式,在限定符后添加一个问号,可以变更为非贪婪模式,即,*?、+?、??;
5)重复限定符:{m}匹配m个,{m,n}匹配不少于m个,不多于n个,同样,后面添加问号(?)就变为了非贪婪模式,,应该还有一个{m,}的用法,表示匹配至少m个,教程2中没有讲这个。
6)反斜杠(\)
两个作用:转义特殊字符,比如前面介绍的特殊字符;指明特殊序列(原文:signal a special sequence,比如,\1表示第一个匹配的子串,后面会有介绍)。
另外,前面提到过,反斜杠在Python和正则表达式中的冲突,官文再次强烈建议使用 原始字符串 写正则表达式。不要纠结了,正则表达式前面一律添加 r 字符吧。
7)一对中括号([])
表示一个字符集合(a set of characters),大家应该都很熟悉。
进阶:
-特殊字符在中括号中是没有特殊意义的——Special characters lose their special meaning inside sets.,这样所!
-字符类(Character classes)还是可以在中括号中使用,比如\w、\S。
-脱字符(^)求反,脱字符^是前中括号后第一个字符。
-匹配后中括号,两种方式:放在前中括号后面第一个位置,或者,使用反斜杠,,孤推荐使用反斜杠。
-暂不支持嵌套集合,
8)竖号(|,Vertical sign)
表示匹配其前后的 正则表达式 中任意一个都是 匹配的,用法:A|B,正则表达式可以多个(arbitrary number of REs)。
进阶:
-从左往右 查找,找到匹配后就不再查找了;
-匹配竖号的方式:下划线(\|),添加到中括号中([|]);
9)圆括号在正则表达式中的使用——重难点啊!自己从来没搞清楚过!趁现在吧!
教程2中的各种用法:
(...)
括号中是一个正则表达式,指明了一个 组(group)的开始和结尾。
一个 组 的内容可以在 匹配执行后 重用,并在其后的字符串中 使用 \number 特殊序列(\number special sequence) 进行匹配。
圆括号本身可以使用反斜杠、中括号进行匹配。
什么是 组?圆括号里面是 组 的正则表达式,出去下面介绍的情况外,一个圆括号就代表一个组,,执行search()函数后,可以使用返回对象的groups()函数查看组匹配的信息。groups()函数中的匹配字符串的顺序,和圆括号在整个正则表达式中出现的顺序相关,先出现的会出现在groups()函数结果的前面。~~不好意思,好像没有解释的很清楚,还需dig,也欢迎大家补充~
(?...)
这是一个 扩展标记(extension notation),?号后第一个字符决定了其进一步的语法。
扩展标记 通常不会创建新的组,即合上面的(...)不一样。
唯一的例外:(?P<name>...)。
(?aiLmsux)
匹配空字符串,用于 为整个正则表达式设置标记。必须出现在正则表达式的第一位置(Flags should be used first in the expression string),有了它,就不需要单独设置flags了,感觉很有用。
(?:...) 注意,问号有有 冒号(:)
A non-capturing version of regular parentheses.
但是,被这个组匹配的子串不能在稍后被 重用。
(?aiLmsux-imsx:...)
短横线前面是 设置set标记,后面是取消remove标记。有些复杂,请看教程2。
(?P<name>...)
这个见到的比较多,也是很有用的。
和圆括号的组 不同的是 匹配整个用法的组的字符串 可以使用 符号化组名(the symbolic group name name) 来访问。
符号化组名 要求:是Python标识符,在一个正则表达式中唯一。
这个也叫做 符号化组、命名组,它同时也是一个数字化组。
这个组可以在三种上下文中引用(下为官文截图):

(?P=name)
A backreference to a named group。上面的例子中大家有见到了。
(?#...)
注释。哦。有什么意义?
(?=...) a lookahead assertion
(?!...) a negative lookahead assertion
上面两个是一对,具备相反的功能。
孤有些说不清楚,看示例:
For example, 'Isaac (?=Asimov)' will match 'Isaac ' only if it’s followed by 'Asimov'.
若字符串仅为'Isaac ',则不匹配,除非其后有'Asimov',但是,和?=后re匹配的'Asimov'不会出现在匹配结果中。
For example, 'Isaac (?!Asimov)' will match 'Isaac ' only if it’s not followed by 'Asimov'.
字符串'Isaac '如果没有跟着'Asimov'则匹配成功,否则,匹配失败。
(?<=...) a positive lookbehind assertion
(?<!...) a negative lookbehind assertion
上面两个是一对,具备相反的功能,这一对上上面一对可以算是组合对:前面一对 检查字符串末尾的是否匹配,这一对检查字符串开头是否匹配。
以上四个的英文名都有assertion,就是所谓的断言了,断言是否存在什么,然后决定是否匹配。
官文示例如下:
>>> import re
>>> m = re.search('(?<=abc)def', 'abcdef')
>>> m.group(0)
'def'
>>> m = re.search(r'(?<=-)\w+', 'spam-egg')
>>> m.group(0)
'egg'
(?(id/name)yes-pattern|no-pattern)
给定id或名称的组匹配成功,那么,就和yes-pattern进行匹配,否则,和no-pattern进行匹配。no-pattern是可选的,可以忽略掉。
官文示例:
For example, '(<)?(\w+@\w+(?:\.\w+)+)(?(1)>|$)' is a poor email matching pattern,
which will match with '<user@host.com>' as well as 'user@host.com',
but not with '<user@host.com' nor 'user@host.com>'.
解释,如果(<)?匹配成功,那么,就使用>来匹配,否则为字符串结束符。就是实现 前后尖括号 要么同时有、要么都没有 的检测。
10)专用序列(The special sequences)
最后一个 重点 了!
由一个反斜杠(\)和一个字符组成(找个说法不准确,在 \number 时,会有最多两个数字)。
若第二个字符不是普通的ASCII数字或字母,那么,正则表达式将匹配第二个字符。下面的示例匹配了 鲜 字 花 字。
>>> import re
>>> re.findall('\鲜\花', '今天来到花市,发现了好多鲜花,最后还买了一束鲜花——各种混搭')
['鲜花', '鲜花']
下面选择一些进行介绍——其实不少大家都是知道的,或许有些进阶内容要补充:
\number
匹配 组1号 和number相同的匹配了的组的内容。组号 从1开始,这个序列仅用于匹配前面99个组的内容。
进阶:
-反斜杠后第一个数字为0,或number是三个八进制数字,将不会被解释为 组匹配,而是匹配八进制数所代表的字符;
-在正则中括号中,所有的数字转义被视为字符,比如 [\97] 不是匹配第97个组的内容,而是匹配字母a。
原文:Inside the '[' and ']' of a character class, all numeric escapes are treated as characters.
上面这条解释有误,测试发生异常,还需要dig:


>>> re.findall('[\97]', 'an apple on the tree')
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
re.findall('[\97]', 'an apple on the tree')
File "C:\Python36\lib\re.py", line 222, in findall
return _compile(pattern, flags).findall(string)
File "C:\Python36\lib\re.py", line 301, in _compile
p = sre_compile.compile(pattern, flags)
File "C:\Python36\lib\sre_compile.py", line 562, in compile
p = sre_parse.parse(p, flags)
File "C:\Python36\lib\sre_parse.py", line 855, in parse
p = _parse_sub(source, pattern, flags & SRE_FLAG_VERBOSE, 0)
File "C:\Python36\lib\sre_parse.py", line 416, in _parse_sub
not nested and not items))
File "C:\Python36\lib\sre_parse.py", line 527, in _parse
code1 = _class_escape(source, this)
File "C:\Python36\lib\sre_parse.py", line 340, in _class_escape
raise source.error("bad escape %s" % escape, len(escape))
sre_constants.error: bad escape \9 at position 1
>>> re.findall(r'[\97]', 'an apple on the tree')
Traceback (most recent call last):
File "<pyshell#6>", line 1, in <module>
re.findall(r'[\97]', 'an apple on the tree')
File "C:\Python36\lib\re.py", line 222, in findall
return _compile(pattern, flags).findall(string)
File "C:\Python36\lib\re.py", line 301, in _compile
p = sre_compile.compile(pattern, flags)
File "C:\Python36\lib\sre_compile.py", line 562, in compile
p = sre_parse.parse(p, flags)
File "C:\Python36\lib\sre_parse.py", line 855, in parse
p = _parse_sub(source, pattern, flags & SRE_FLAG_VERBOSE, 0)
File "C:\Python36\lib\sre_parse.py", line 416, in _parse_sub
not nested and not items))
File "C:\Python36\lib\sre_parse.py", line 527, in _parse
code1 = _class_escape(source, this)
File "C:\Python36\lib\sre_parse.py", line 340, in _class_escape
raise source.error("bad escape %s" % escape, len(escape))
sre_constants.error: bad escape \9 at position 1
\A
\Z
上面两个是一对,分别表示匹配字符串的开始、结尾。
和^、$有什么区别呢?
\b
\B
匹配空字符串,两者作用相反。涉及到ASCII、LOCALE两个标记的使用。详见教程2。
\d
\D
匹配数字,但又分为Unicode模式、ASCII模式,前者包含更多,多了哪些,还需dig。
Unicode模式下,如果标记ASCII设置了,则只有 [0-9] 匹配。
\s
\S
匹配空白字符,[ \t\n\r\f\v],也分为Unicode、ASCII模式,同上一对。
\w
\W
匹配alphanumeric字符和下划线,即[a-zA-Z0-9_],也分为Unicode、ASCII模式,同上一对。
另外,Python字符串量支持的一些标准转义字符 同样可以被 正则表达式解析,比如:
\a \b \f \n
\r \t \u \U
\v \x \\
注意,正则表达式中 \b 表示 单词边界,除非它出现在字符类(character classes)才表示 退格。
注意,\u、\U可以在Unicode模式下被识别,但在bytes模式下报错。
注意,八进制转义(不能准确翻译下面的原文,就暂时不翻译中文了)
Octal escapes are included in a limited form. If the first digit is a 0, or if there are three octal digits, it is considered an octal escape. Otherwise, it is a group reference. As for string literals, octal escapes are always at most three digits in length.
好了,专有序列也讲完了,仔细算的话,Python的正则表达式中的re模块自己是学了一遍了,可是不熟悉啊!
对于教程2,自己只剩下第五节示例没有研读了,文章先发表了,孤先去看第五节啦!若有所得,再来补充!
感觉自己很棒嘛!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号