使用PyMongo访问需要认证的MongoDB
Windows 10家庭中文版,Python 3.6.4,PyMongo 3.7.0,MongoDB 3.6.3,Scrapy 1.5.0,
前言
在Python中,使用PyMongo访问MongodB,作者Mike Dirolf,维护人员Bernie Hackett <bernie@mongodb.com>,相关链接如下:
说明,关于文档,可以从GitHub下载PyMongo(需要安装sphinx先),然后自行编译文档。
说明,PyMongo还有一些附属包,以提供与MongoDB服务器匹配的功能,比如TLS / SSL、GSSAPI、srv、wire protocol compression with snappy等,大家可以根据需要安装。
本文介绍使用PyMongo访问需要认证的MongoDB,包括从IDLE、Scrapy爬虫程序来访问。
参考官文:PyMongo Authentication Examples(可以直接阅读官文,忽略本文剩余部分,)
本地MongoDB服务器介绍
打开MongoDB服务器:
mongod --dbpath d:\p\mdb2dir --logpath d:\p\mdb2dir\log --logappend --auth --directoryperdb
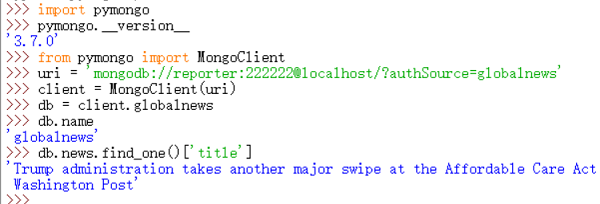
目前存在数据库globalnews,里面有集合news,news里面的每条文档包含title、url两个属性,目前集合news中有33条文档,存在用户reporter,密码为222222。
使用IDLE访问
使用Scrapy爬虫程序
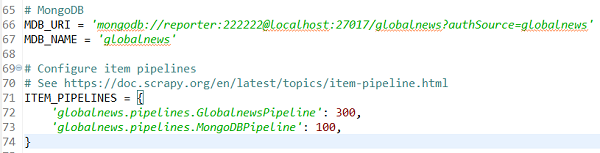
在Scrapy项目的settings.py中配置MongoDB配置项,并启用相关Item Pipelines:
MongoDBPipeline源码如下:
1 import pymongo 2 3 class MongoDBPipeline(object): 4 ''' 5 将项目抓取到的数据(title、url、response.body)保存到MongoDB中。 6 目标数据库:配置文件中又MDB_URI、MDB_NAME定义 7 目标数据集:news,由本类定义 8 ''' 9 10 # 目标数据集 11 coll_name = 'news' 12 13 def __init__(self, mongo_uri, mongo_db): 14 self.mongo_uri = mongo_uri 15 self.mongo_db = mongo_db 16 17 # debug 18 print('mongo_uri = ', self.mongo_uri) 19 print('mongo_db = ', self.mongo_db) 20 21 # 获取配置文件中的MDB_URI、MDB_NAME两个属性 22 @classmethod 23 def from_crawler(cls, crawler): 24 return cls( 25 mongo_uri = crawler.settings.get('MDB_URI'), 26 mongo_db = crawler.settings.get('MDB_NAME', 'news') # 没有就返回news 27 ) 28 29 # 启动spider时,建立数据库连接 30 def open_spider(self, spider): # 没有指定监控哪个spider? 31 self.client = pymongo.MongoClient(self.mongo_uri) 32 self.db = self.client[self.mongo_db] 33 34 # 关闭spider时,关闭数据库连接 35 def close_spider(self, spider): 36 self.client.close() 37 38 # 将抓取到的Item存储到MongoDB中 39 def process_item(self, item, spider): 40 41 self.db[self.coll_name].insert_one(dict(item)) # 42 return item
在终端执行爬虫程序:
scrapy crawl -a user_agent="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36" wdcpost
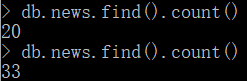
执行结果:集合news中成功增加了多条文档,达到了33条。
后记
从网站到爬虫,从爬虫【安全地】到MongoDB数据库,数据通路已经安全打开,请继续!嘿
还需要补足使用PyMongo操作MongoDB的更多操作,需要全部了解、常用熟悉、部分精通,知道哪里找,找到知道怎么用!
Scrapy爬虫程序是在virtualenv中执行的,居然也可以写到主机的MongoDB数据库中,有意思!
好好想想接下来怎么做,上云(OH, MYSELF! MONEY!)要怎么弄~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号