孤的Scrapy官文阅读进程
上月底开始学习Scrapy爬虫框架,看了一些中文文档,讲应用、讲基础的,对其有一些了解了。终于在28日打开Scrapy的官网,并制作了其文档的思维导图,进而开启了其文档的阅读之旅。
本文展示了从6月28日到7月3日每天阅读过的Scrapy文档,记录其整个过程和读后感。
不过,这是第一次做这样的记录,目的是想完整地学习Scrapy,要是可行、高效,后续可以应用到其它方面。
阅读过程
颜色变化表示当天阅读。
-6月28日
-6月29日
-6月30日
-7月1日
-7月2日
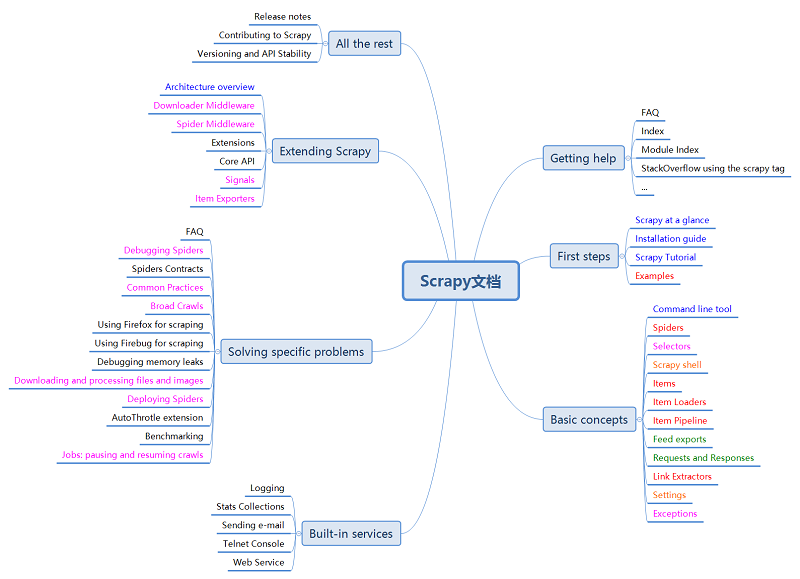
-7月3日
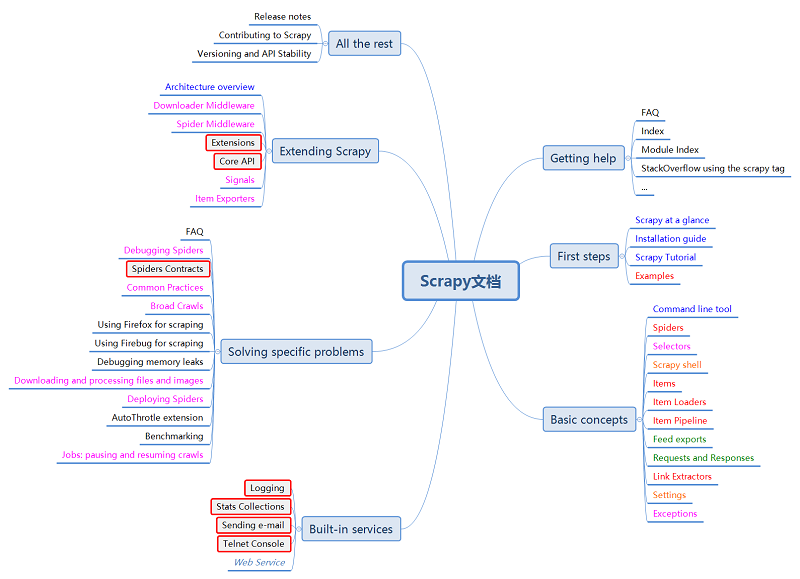
6天,可以说大部分文档都读过了吧,期间也有一些简单的练手。其中,前面阅读速度较慢——有很多东西都需要斟酌,后面的7月2日、3日读的就比较快了,一咬咬牙,文档就读完了。
读后感
1.学习新的东西,开始都会比较慢,也会比较难——因为有很多新【知识点】,而后面因为对相关新【知识点】了解的多了、透了,阅读效率也就提高了;
2.学习新的东西,并不是一下子、一小时、一天就可以学到的,它需要更多的时间 和 耐心,否则,开始的艰难期会容易产生负面情绪,比如,烦躁,这样就很难真正地学好新的东西了,淡定点,慢慢来会比较快(歌名吗)?
3.英文能力需要提高,阅读IT类文档的水平也需要提高,涉及到两个方面——英文阅读硬实力和对IT技术的理解,怎么提高呢?目前孤的想法是,多读英文技术文档,熟能生巧,经常接触的话,可以增加自己的熟悉感,负面情绪会少很多,甚至没有;多看看英文网站,没事时就背背单词、听听英文听力,当然,这都需要时间;另外,多这样学习几次就好勒,GitHub要常用;这是长期任务;
4.学习 还得和 练习、复习(包括总结)搭配才好;比如本次阅读Scrapy文档,虽然6天时间阅读完了,但练习的比较少,加上理解的一些问题,其实自己现在并不能说是完全掌握Scrapy,还差得远呢;复习,在阅读文档期间就相当于重复看文档,找到其中【不理解的】地方,再次投入精时去理解,这也是需要总结的,什么地方学透了,什么地方没有,自己心中要有数,知道继续攻坚克难的方向;
5.Scrapy的文档更多是技术性的,对于实际的应用,比如,孤想爬取微博、博客园、知乎的内容,帮助并不是很“直接”,这个或许要自己去dig,当然,多看看其它技术博文——取经、站在他人的肩膀上;
6.学习的最终目的是什么呢?灵活运用、学以致用(开发应用、系统、平台)、融会贯通,不外乎此三条吧!嗯,谋生(赚钱)、干事,嘿!
7.接下来,练习、使用、总结、提高,开发几个应用出来!
8.Scrapy文档或许缺少更实际的项目应用,需要dig!
9.坚持写技术博文,样式更美观大方的博文、对读者更有用的博文、对自己整理知识体系更有用的博文!赏心悦目!
一些疑问
疑问1,
Scrapy项目上线后,怎么检测到 源站点 的网页结构发生变化了呢,并及时开发相关人员 进行更新?
变化可能包括:
1.页面结构变化,改版了;
2.验证方式改变,新的验证码;
3.其它;
疑问2,
很多站点会禁止爬虫程序爬取数据,虽然可以突破robots.txt协议,但是,是否可以更道德一些呢?和站点签订协议,付费爬取数据(也可能是对方提供数据接口(API))?
疑问3,
哪些站点是可以爬取数据的?哪些站点是不可以的?仅仅根据robots.txt的规则怕是不够的吧?怎么做到合理、合法?对哦,爬取网站数据不会犯法吧?
疑问4,
Scrapy官文没有介绍怎么突破JavaScript脚本验证、跳转(微博遇到),应该是需要其它工具来做这件事情吧!看过其它的一些文档,提到过洋葱路由器(TOR)、Selenium、PhantomJS等,还需dig。
疑问5,
爬取那么多数据,哪些是有用的呢?或许,做爬虫的公司是知道的,或许,自己摸索久了也就知道了!
继续探索!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号