


安装Hadoop
Ubuntu 18.04.1 LTS (on VirtualBox)
Apache hadoop-3.3.1.tar.gz(2021 Jun 15)
JAVA 8 (openjdk version "1.8.0_162")
--
注,2020年7月写过一篇,今天,重新启程。
Hadoop下载地址:
https://hadoop.apache.org/releases.html
选择其中的 Binary download,点击即开始下载(近600MB)。
本文记录 单机安装Hadoop的步骤,参考官文:
Hadoop: Setting up a Single Node Cluster.
目录
5、配置伪分布式模式(pseudo-distributed mode)
7.1 etc/hadoop/mapred-site.xml
1、建立hadoop用户
# 新建用户 hadoop
sudo useradd -m hadoop -s /bin/bash
# 添加到sudo组(管理员权限)
sudo adduser hadoop sudo
# 设置hadoop密码
passwd hadoop试验时设置密码为 111。
新建用户后,多了一个 hadoop组( cat /etc/group),sudo组 下多了一个 hadoop:
$ cat /etc/group | grep sudo
sudo:x:27:user,hadoop/home下多了 hadoop目录:
$ ls -l /home | grep hadoop
drwxr-xr-x 6 hadoop hadoop 4096 12月 4 12:08 hadoop
疑问:
hadoop 用户在 使用Hadoop的作用是什么?
2、配置免密登录
安装了 ssh。
修改 /etc/profile ,添加:
export PDSH_RCMD_TYPE=ssh
切换到 hadoop 用户,进入其 home 目录,执行ssh-keygen:
# 输入后,一直点回车
ssh-keygen
# 官文的
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa在 /home/hadoop 下生成了 .ssh 及其中的三个文件:
id_rsa、id_rsa.pub、known_hosts
执行命令,拷贝 id_rsa.pub 的内容到 authorized_keys 文件(不存在也没关系,会自动建立):
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys此时,执行 ssh localhost 就可以免密登录了。
疑问:
免密登录 的作用是什么?
下面配置 单机伪分布式模式 时需要。
3、下载&解压
下载得到 hadoop-3.3.1.tar.gz,放到 /home/hadoop/ws 中;
进入/home/hadoop/ws,原地解压:
tar zxvf hadoop-3.3.1.tar.gz解压得到:
$ ll hadoop-3.3.1/
total 124
drwxr-xr-x 11 hadoop hadoop 4096 12月 4 11:34 ./
drwxrwxr-x 3 hadoop hadoop 4096 12月 4 11:34 ../
drwxr-xr-x 2 hadoop hadoop 4096 12月 4 11:34 bin/
drwxr-xr-x 3 hadoop hadoop 4096 12月 4 11:34 etc/
drwxr-xr-x 2 hadoop hadoop 4096 12月 4 11:34 include/
drwxr-xr-x 3 hadoop hadoop 4096 12月 4 11:34 lib/
drwxr-xr-x 4 hadoop hadoop 4096 12月 4 11:34 libexec/
-rw-rw-r-- 1 hadoop hadoop 23450 12月 4 11:34 LICENSE-binary
drwxr-xr-x 2 hadoop hadoop 4096 12月 4 11:34 licenses-binary/
-rw-rw-r-- 1 hadoop hadoop 15217 12月 4 11:34 LICENSE.txt
drwxrwxr-x 2 hadoop hadoop 4096 12月 4 12:08 logs/
-rw-rw-r-- 1 hadoop hadoop 29473 12月 4 11:34 NOTICE-binary
-rw-rw-r-- 1 hadoop hadoop 1541 12月 4 11:34 NOTICE.txt
-rw-rw-r-- 1 hadoop hadoop 175 12月 4 11:34 README.txt
drwxr-xr-x 3 hadoop hadoop 4096 12月 4 11:34 sbin/
drwxr-xr-x 4 hadoop hadoop 4096 12月 4 11:34 share/本试验用到过 etc、bin、sbin、logs 三个目录下的文件。
4、修改配置
4.1 etc/hadoop/hadoop-env.sh
末尾添加:
export JAVA_HOME=/usr
说明:
为什么是 /usr?使用 whereis java 得到的结果如下:
$ whereis java
java: /usr/bin/java /usr/share/java /usr/share/man/man1/java.1.gz其实,可以进一步追踪 java命令在哪里:/usr/bin/java 只是一个 符号链接。
$ ls -l /usr/bin | grep java
lrwxrwxrwx 1 root root 22 5月 26 2021 java -> /etc/alternatives/java
lrwxrwxrwx 1 root root 23 5月 26 2021 javac -> /etc/alternatives/javac
lrwxrwxrwx 1 root root 25 5月 26 2021 javadoc -> /etc/alternatives/javadoc
lrwxrwxrwx 1 root root 23 5月 26 2021 javah -> /etc/alternatives/javah
lrwxrwxrwx 1 root root 23 5月 26 2021 javap -> /etc/alternatives/javap
# 更进一步:/etc/alternatives/java 也是一个 符号链接
/etc/alternatives$ ls -l | grep java
lrwxrwxrwx 1 root root 46 5月 26 2021 java -> /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
...
进一步跟踪,这里的 JAVA_HOME 应该配置为:
/usr/lib/jvm/java-8-openjdk-amd64更改后,bin/hadoop命令仍然可用,说明是对的。
配置完毕,此时,可以使用 bin/hadoop 命令了。
🚩Standalone模式:配置完毕。
疑问:
此时可以做什么?
5、配置伪分布式模式(pseudo-distributed mode)
5.1 etc/hadoop/core-site.xml
说明,官文中,端口配置为 9000,但本机的 9000端口被 另外的程序占用了,故改为 19870。开始改为 9870,结果失败了,9870是默认的Web访问端口。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:19870</value>
</property>
</configuration>
5.2 etc/hadoop/hdfs-site.xml
一个 namenode,一个 datanode,副本数量 设置为 1。
两个nodes 的 value都在 /data/hadoop/ 目录下,目的是为了 数据持久——否则会在 /tmp 目录下建立。
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
5.3 创建/data/hadoop
创建目录,并把权限分配给 hadoop(chown)。来自博客园
$ ls -l /data/
drwxrwxr-x 3 hadoop hadoop 4096 12月 3 21:51 hadoop
6、启动HDFS
namenode格式化:
bin/hdfs namenode -format执行后,/data/hadoop/ 下的变化:多了一些文件(格式化后本没有这么多,下图有些 是 后面启动hdfs后产生的)
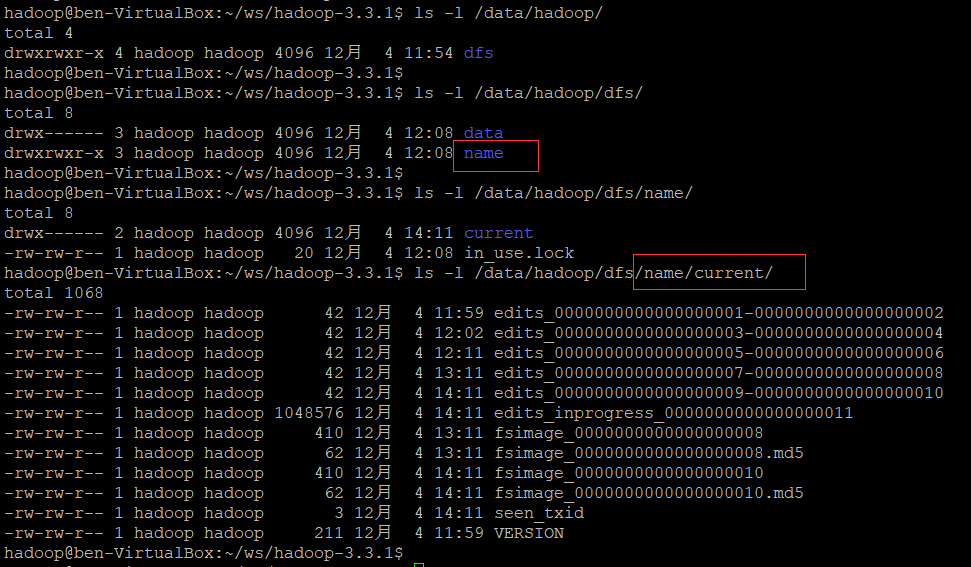
启动HDFS:
namenode、datanode、secondary namenode 都启动了
$ sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [ben-VirtualBox]执行jps命令,可以看到多了几个进程:每个node对应一个 JAVA进程
$ jps
12273 Jps
11882 DataNode
12126 SecondaryNameNode
11711 NameNode如果三个没有启动,可以去 Hadoop下的 logs目录 中查看 具体启动失败的原因。来自博客园
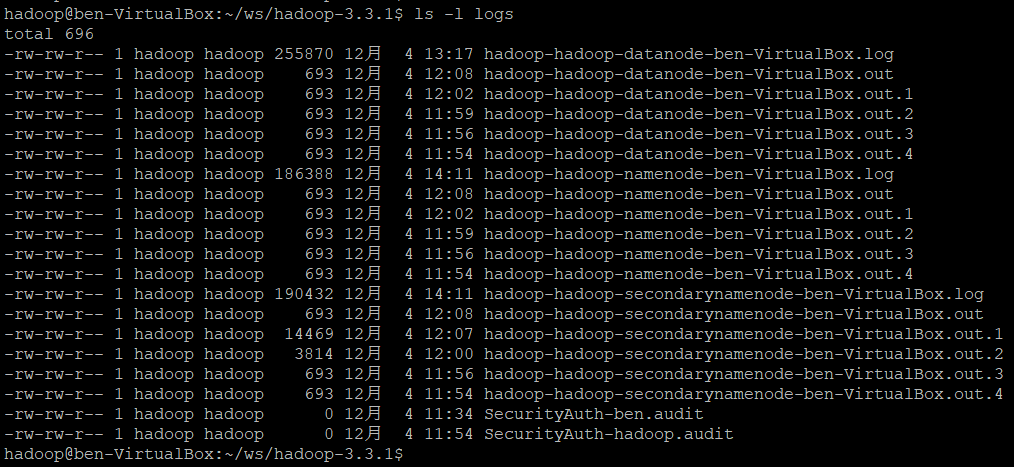
进程信息:
浏览器 访问三个nodes 的Web页面:
1)namenode
访问 http://localhost:9870

从页面可以看到,namenode用了 9870、19870 两个端口,后者是前面配置的。来自博客园
2)datanode
在 namenode 的web页面 打开 Datanodes 标签页,其中可以看到一个 datanode,其占用了两个端口:9866、9864
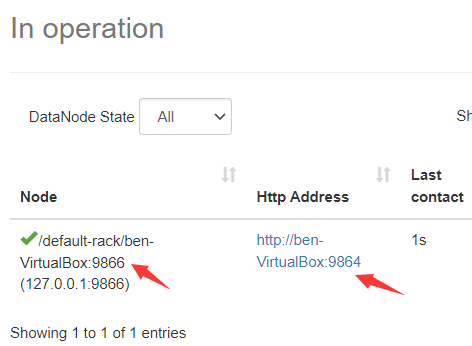
访问 http://localhost:9864 :
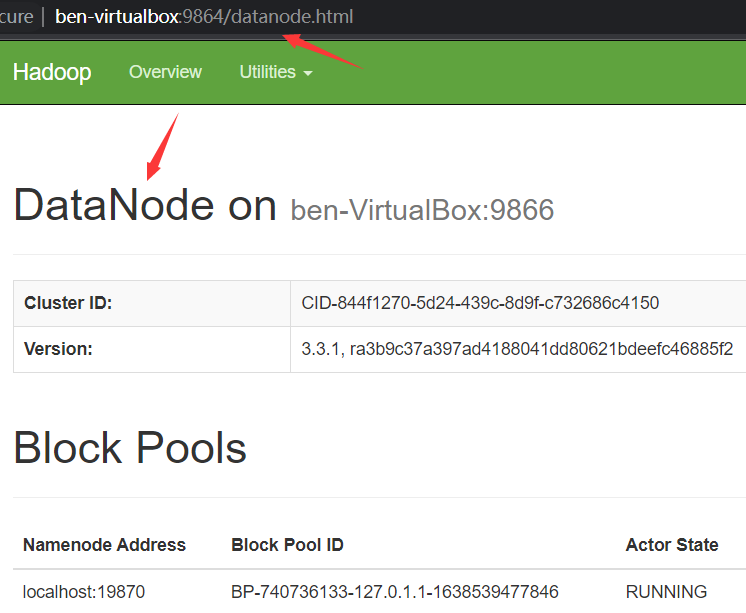
3)secondary namenode
前面两个noded都可以浏览器访问了,那么,secondary namenode 可以吗?来自博客园
在namenode中没有找到相关信息,但可以用 netstat 找到其端口。9867 还是 9868?
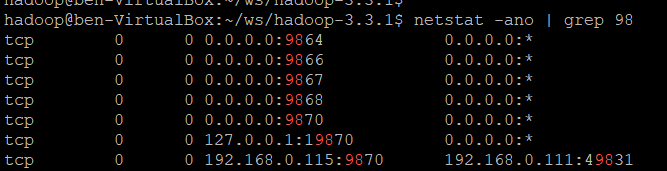
访问端口 9867 返回:
It looks like you are making an HTTP request to a Hadoop IPC port.
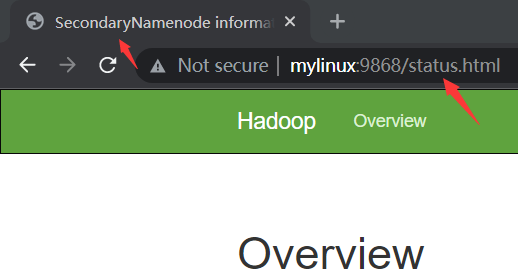
This is not the correct port for the web interface on this daemon.访问 http://localhost:9868,返回其 /status.html 页面(图中的 mylinux 指 Ubuntu虚拟机):来自博客园
🚩至此,bin/hdfs 命令就可以使用了。
示例:
help命令:
bin/hdfs --help
bin/hdfs dfs --help
使用 dfs子命令:
建立目录 /user
404* bin/hdfs dfs -mkdir /user/
建立目录 /user/hadoop
405 bin/hdfs dfs -mkdir /user/hadoop
查看 根目录下文件
406 bin/hdfs dfs -ls /
查看 /user下文件
407 bin/hdfs dfs -ls /user
将本地文件按上传 并更名为 input:此时的 hdfs当前目录为 /user/hadoop
409 bin/hdfs dfs -put NOTICE.txt input
410 bin/hdfs dfs -ls /
411 bin/hdfs dfs -ls /user
找到上传的文件
412 bin/hdfs dfs -ls /user/hadoop
找到上传的文件
413 bin/hdfs dfs -ls
显示上传的文件的内容
414 bin/hdfs dfs -cat input更多使用,可以本文开头提到的参考官文。来自博客园
停止hdfs:
$ sbin/stop-dfs.sh
疑问:
hdfs是什么?fs文件系统,文件系统能干啥呢?管理文件啊!
hdfs管理文件 和 主机上管理文件有什么不同?分布式文件系统?可以存 更多、更大 的文件?上限是怎样的?读写效率如何?
hdfs的实际案例有哪些?来自博客园
小坑说明
启动过程中,遇到一些免密登录权限的问题——没有将 id_rsa.pub拷贝到 authorized_keys 中 导致的。
错误如下:
$ sbin/start-dfs.sh
Starting namenodes on [ben-VirtualBox]
ben-VirtualBox: hadoop@ben-virtualbox: Permission denied (publickey,password).
Starting datanodes
localhost: hadoop@localhost: Permission denied (publickey,password).
Starting secondary namenodes [ben-VirtualBox]
ben-VirtualBox: hadoop@ben-virtualbox: Permission denied (publickey,password).
官文中的 HDFS架构图:

7、配置YARN资源调度器
7.1 etc/hadoop/mapred-site.xml
同官文。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
7.2 etc/hadoop/yarn-site.xml
多了 yarn.nodemanager.vmem-check-enabled=false
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 避免 任务需要的内存超过虚拟内存大小 时,任务自动失败 的问题 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>7.3 启动YARN
sbin/start-yarn.sh 命令
hadoop@ben-VirtualBox:~/ws/hadoop-3.3.1$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
hadoop@ben-VirtualBox:~/ws/hadoop-3.3.1$ jps
7986 Jps
4882 DataNode
4708 NameNode
5126 SecondaryNameNode
7853 NodeManager
7693 ResourceManager
hadoop@ben-VirtualBox:~/ws/hadoop-3.3.1$🚩启动成功,多了 NodeManager、ResourceManager 两个JAVA进程。来自博客园
7.4 访问资源管理器
端口:8088


好了,单机伪分布式模式安装完毕,且正常运行。
停止YARN:
$ sbin/stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager此时,使用jps命令 找不到YARN相应的进程了,Web页面自然也访问不了了。
疑问:
hadoop安装好了,可以用来做什么呢?
hadoop有哪些配置?
hdfs有哪些配置?不同类型节点
yarn是什么?资源调度?怎么调度?原理是什么?怎么使用?来自博客园
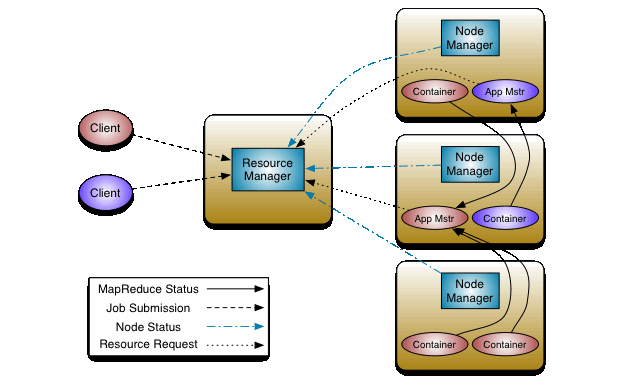
官文中的 YARN架构图:
》》》全文完《《《
确定关键问题,才能走好下一步。
再次出发,这次会前进到哪一步?
自己的 前文
5、

