Python高级应用程序设计任务
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
猎聘招聘信息爬取与分析
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取猎聘网的工作岗位名称、公司名称、工作地点、薪资待遇以及学历要求,并把这些数据存储在文件中,以及对薪资待遇进行数据分析。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
首先爬取目标信息,然后将目标信息进行存储,再提取薪资水平,最后对该行业的薪资进行数据可视化分析。
难点:对目标信息进行爬取,以及数据清洗。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征


2.Htmls页面解析

通过对页面源代码的分析可以知道,我们想要的目标信息在属性为class="sojob-item-main clearfix"的div标签中,接下来就是爬取目标信息。
3.节点(标签)查找方法与遍历方法(必要时画出节点树结构)
我们可以利用BeautifulSoup提供的find_all()方法查找所有属性为class="sojob-item-main clearfix"的div标签即可获取当前页面的全部目标信息。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
程序源代码
import requests from bs4 import BeautifulSoup import os import re import matplotlib.pyplot as plt from matplotlib.pyplot import plot,savefig #爬取猎聘目标的HTML页面 def getHTMLText(url,keyword): try: #假装成浏览器访问 kv = {'user-agent':'Mozilla/5.0'} #获取目标页面 r = requests.get(url,params=keyword,headers = kv) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #爬取数据 def getData(jlist,slist,clist,plist,elist,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #遍历所有属性为sojob-item-main clearfix的div标签 for div in soup.find_all("div",attrs = {"class":"sojob-item-main clearfix"}): #将爬取到的工作名称存放在jlist列表中 jlist.append(div.a.string.strip()) #将爬取到的薪资存放在slist列表中 slist.append(div.p.span.string) #在div标签中遍历所有属性为company-name的p标签 for p in div.find_all("p",attrs = {"class":"company-name"}): #将爬取到的公司名称存放在clist列表中 clist.append(p.a.string) #在div标签中遍历所有属性为condition clearfix的p标签 for p in div.find_all("p",attrs = {"class":"condition clearfix"}): #如果p标签里的a标签为空,则执行下面语句 if p.a == None: plist.append("无") continue #将爬取到的工作地点存放在plist列表中 plist.append(p.a.string) #在div标签中遍历所有属性为edu的span标签 for span in div.find("span",attrs={"class":"edu"}): #将爬取到的学历要求存放在elist列表中 elist.append(span) #打印工作信息函数 def printUnivList(jlist,slist,clist,plist,elist,num): for i in range(num): print("公司名称:{}".format(clist[i])) print("岗位名称:{}".format(jlist[i])) print("薪资待遇:{}".format(slist[i])) print("工作地点:{}".format(plist[i])) print("学历要求:{}".format(elist[i])) print() #数据存储 def dataSave(jlist,slist,clist,plist,elist,keyword,num): try: #创建文件夹 os.mkdir("C:\招聘信息") except: #如果文件夹存在则什么也不做 "" try: #创建文件用于存储爬取到的数据 with open("C:\\招聘信息\\"+keyword+".txt","w") as f: for i in range(num): f.write("公司名称:{}\n".format(clist[i])) f.write("岗位名称:{}\n".format(jlist[i])) f.write("薪资待遇:{}\n".format(slist[i])) f.write("工作地点:{}\n".format(plist[i])) f.write("学历要求:{}\n\n".format(elist[i])) except: "存储失败" #数据可视化 def dataVisualization(salary1,name): # 创建figure对象 plt.figure() # 生成Y坐标列表 y = [i for i in range(0,40000,100)] salary1.sort() #X坐标名 plt.xlabel('Actual salary') #Y坐标名 plt.ylabel('Salary grade') # 绘制salary,线条说明为'salary',线条宽度为2,颜色为红色,数据标记为圆圈 plt.plot(y, salary1, label='salary',linewidth = 2, linestyle='', marker='o', color='r') # 显示图例 plt.legend() #保存图片 savefig("C:\\招聘信息\\"+name+".jpg") # 显示图像 plt.show() def main(): #猎聘网网址 url = "https://www.liepin.com/zhaopin/" #要搜索的岗位名称 keyword = input("请输入想要查找的岗位:") #搜索页数 pageNum = 10 #打印信息条数 priNum = pageNum * 40 #用来存放工作岗位 jlist = [] #用来存放薪资 slist = [] #用来存放工作地点 plist = [] #用来存放学历 elist = [] #用来存放公司名称 clist = [] #循环加入页码,将每页的信息存在列表中 for num in range(pageNum): kv = {"key":keyword,"curPage":num} html = getHTMLText(url,kv) getData(jlist,slist,clist,plist,elist,html) #将结果打印出来 printUnivList(jlist,slist,clist,plist,elist,priNum) #将爬取到的数据存储在文件中 dataSave(jlist,slist,clist,plist,elist,keyword,priNum) #存储低段位薪资 salary1 = [] #中间量 flag = [] #存储高段位薪资 salary2 = [] #获取薪资 for i in slist: try: #筛选出薪资 fg = re.search(r'^(\d)+',i) #将薪资存储在列表中 salary1.append(int(fg.group())*1000) except: #如果没具体薪资则存储0 salary1.append(0) continue #数据可视化 dataVisualization(salary1,keyword) #程序执行时调用主程序main() if __name__ == "__main__": main()
运行结果如下:
图1

图2
数据存储文件夹:
图3
文件内容:
图4
数据的爬取与采集代码如下:
#爬取猎聘目标的HTML页面 def getHTMLText(url,keyword): try: #假装成浏览器访问 kv = {'user-agent':'Mozilla/5.0'} #获取目标页面 r = requests.get(url,params=keyword,headers = kv) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败"
数据进行清洗和处理代码如下:
1 #爬取数据 2 def getData(jlist,slist,clist,plist,elist,html): 3 #创建BeautifulSoup对象 4 soup = BeautifulSoup(html,"html.parser") 5 #遍历所有属性为sojob-item-main clearfix的div标签 6 for div in soup.find_all("div",attrs = {"class":"sojob-item-main clearfix"}): 7 #将爬取到的工作名称存放在jlist列表中 8 jlist.append(div.a.string.strip()) 9 #将爬取到的薪资存放在slist列表中 10 slist.append(div.p.span.string) 11 #在div标签中遍历所有属性为company-name的p标签 12 for p in div.find_all("p",attrs = {"class":"company-name"}): 13 #将爬取到的公司名称存放在clist列表中 14 clist.append(p.a.string) 15 #在div标签中遍历所有属性为condition clearfix的p标签 16 for p in div.find_all("p",attrs = {"class":"condition clearfix"}): 17 #如果p标签里的a标签为空,则执行下面语句 18 if p.a == None: 19 plist.append("无") 20 continue 21 #将爬取到的工作地点存放在plist列表中 22 plist.append(p.a.string) 23 #在div标签中遍历所有属性为edu的span标签 24 for span in div.find("span",attrs={"class":"edu"}): 25 #将爬取到的学历要求存放在elist列表中 26 elist.append(span)
将爬取到的数据存放在相应列表中。
3.文本分析(可选):jieba分词、wordcloud可视化
无
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
代码如下:
1 #数据可视化 2 def dataVisualization(salary1,name): 3 # 创建figure对象 4 plt.figure() 5 # 生成Y坐标列表 6 y = [i for i in range(0,40000,100)] 7 salary1.sort() 8 #X坐标名 9 plt.xlabel('Actual salary') 10 #Y坐标名 11 plt.ylabel('Salary grade') 12 # 绘制salary,线条说明为'salary',线条宽度为2,颜色为红色,数据标记为圆圈 13 plt.plot(y, salary1, label='salary',linewidth = 2, linestyle='', marker='o', color='r') 14 # 显示图例 15 plt.legend() 16 #保存图片 17 savefig("C:\\招聘信息\\"+name+".jpg") 18 # 显示图像 19 plt.show()
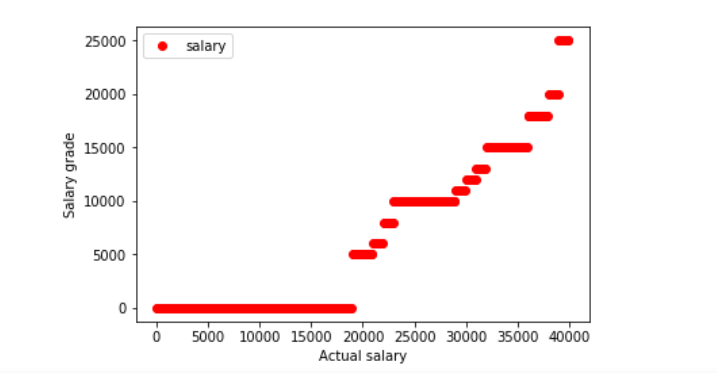
将获取到的薪资水平以散点图形式显示出来。
5.数据持久化 代码如下:
#数据存储 def dataSave(jlist,slist,clist,plist,elist,keyword,num): try: #创建文件夹 os.mkdir("C:\招聘信息") except: #如果文件夹存在则什么也不做 "" try: #创建文件用于存储爬取到的数据 with open("C:\\招聘信息\\"+keyword+".txt","w") as f: for i in range(num): f.write("公司名称:{}\n".format(clist[i])) f.write("岗位名称:{}\n".format(jlist[i])) f.write("薪资待遇:{}\n".format(slist[i])) f.write("工作地点:{}\n".format(plist[i])) f.write("学历要求:{}\n\n".format(elist[i])) except: "存储失败"
将爬取下来的信息以文件形式存储在C盘中。
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过此次对猎聘网web前端工程师的爬取分析后,再结合散点图得出了,全国web前端工程师大多数薪资在15000左右,10000以下的人数占大多数。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次的任务后,加深了我对爬虫、数据分析的掌握程度,也为对其他工作的全国薪资水平有一个基本的了解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号