第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
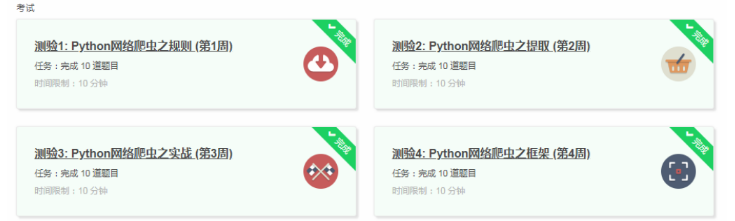
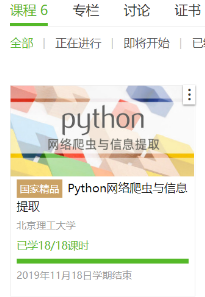
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
通过对《python网络爬虫与信息的提取》的学习,让我了解到网络爬虫是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。它被广泛地运用于互联网的搜索引擎或其他类似的网站,可以自动采集所有其他能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。
第一周,这门课程是使用Python第三方库Requests来爬取网页的信息。requests库的安装命令是:pip install requests,当 r.status_code命令后,显示200状态码,则为访问成功。同时我还了解到Requests库的七个主要方法:(1)equests.request():构造一个请求(2)requests.get():获取网页的主要方法(3)requests.head():获取网页头信息方法;(4)requests.post():向网页提交post请求的方法(5)requests.put():向网页提交put请求的方法(6)requests.patch():向网页提交局部修改请求(7)requests.delete():向网页提交删除请求。
在第二周的学习中,认识了第三方库Beautiful Soup库,懂得了信息的一般提取步骤。Beautiful Soup库是解析、遍历、维护“标签树”的功能库。Beautiful Soup库解析器有html.parser、lxml、xml、html5lib以及此库有五个基本元素,分别是(1)Tag:标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾标签;(2)Name:标签的名称,<>...</p>的名字是“p”,格式:<tag>.name;(3)Attributes:标签的属性,字典形式组织,格式:<tag>.attrs;(4)NavigableString:标签内非属性字符串,<..</>中字符,格式:<tag>.string;(5)Comment:标签内字符串的注释部分,一种特殊的Comment类型。
在第三周中,学习到了Re正则表达式提取页面关键信息以及常用操作符,Re的主要功能函数:(1)re.search():在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象;(2)re.match():在一个字符串的开始位置起匹配正则表达式,返回match对象;(3)re.findall():搜索字符串;(4)re.split():将一个字符串按照正则表达式匹配结果进行分割,返回列表类型;(5)re.finditer():搜索字符串,返回匹配结果的迭代类型;(6)re.sub():在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串。
在第四周,了解到了scrapy爬虫框架。明白了它的一些常见的命令:(1)startproject是创建一个新工程;(2)genspider是创建一个爬虫;(3)settings是获得爬虫配置信息;(4)crawl是运行一个爬虫。
这四周的学习,让我认识到网络爬虫爬取信息的高效性,但是并不能随便爬取,要根据每个网站的robots.txt协议,否则可能会触犯到法律。这次的学习,也让我感受python语言的强大性,虽然课程讲解得很详细,但是自身依然存在一些一知半解的问题,希望自己多利用课余时间在网上搜索资料,解决疑惑同时勤加操作,更好地理解与掌握所学内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号