KM带权二分图最佳匹配算法
前言:
KM算法一般用于边带权值的二分图的完备匹配,也就是二分图左边的每一个点都能匹配到右边的一个点的情况下的最大权值和。但是有一个小技巧,就是如果是想求最大权值匹配而不是完备匹配的话,把各个不相连的边权值设置为0就行了。
原理:

如上图,一开始,如果我们考虑贪心,我们很容易想到,如果左边的每个节点都能选择最大边与右边的点相连,那么这样最后的权值和一定是最大的。但是这样有一个问题,我们要求的完备匹配,但这样可能会使右边地多个点同时连接到左边的一个点,这就发生了冲突。我们接着往下想,既然发生了冲突,那么我们肯定是要舍弃一些最大边,让左边发生冲突的点连接到右边的其他点上面。由于舍弃了最大边,最终的权值和一定会减少,我们自然希望减少的越少越好,于是我们让那些边权值减少最少的的点去连接其他新的点,这样总的权值和减少的最小,这就是KM算法的核心思想和核心思想,即优先选择最满意的,因为要求太高找不到对象的那些人,降低标准扩大择偶范围,直到找到对象为止。
如何实现呢?通过一些巧妙地技巧。
一开始我么将每个女生设一个期望值,就是与她有好感度的男生中最大的好感度。男生呢,期望值为0。
我们匹配的原则是:只与权重相同的边匹配,若是找不到边匹配,对此条路径的所有左边顶点-d,右边顶点+d,再进行匹配,若还是匹配不到,重复+d和-d操作。其中d是改边需要的最小花费。
我们进行了上述操作后会发现,若是左边有n个顶点参与运算,则右边就有n-1个顶点参与运算,整体效率值下降了d*(n-(n-1))=d,而对于女1来说,女1-男3本来为可匹配的边,现在仍为可匹配边(3+1=4),对于女2来说,女2-男3本来为可匹配的边,现在仍为可匹配的边(2+1=3),我们通过上述操作,为女1增加了一条可匹配的边女1-男1,为女2增加了一条可匹配的边女2-男1。
于是问题就解决了,对于左边的每个点,我们用匈牙利算法进行匹配,若匹配不到,我们就通过+d、-d的操作,重新匹配,让发生冲突的点连接到新的点。
相关代码: HDU2255
(时间复杂度介于O(N^3)到O(N^4)之间,可以按照O(N^4)算)


#include <iostream> #include <cstring> #include <cstdio> using namespace std; const int MAXN = 305; const int INF = 0x3f3f3f3f; int love[MAXN][MAXN]; // 记录每个妹子和每个男生的好感度 int ex_girl[MAXN]; // 每个妹子的期望值 int ex_boy[MAXN]; // 每个男生的期望值 bool vis_girl[MAXN]; // 记录每一轮匹配匹配过的女生 bool vis_boy[MAXN]; // 记录每一轮匹配匹配过的男生 int match[MAXN]; // 记录每个男生匹配到的妹子 如果没有则为-1 int slack[MAXN]; // 记录每个汉子如果能被妹子倾心最少还需要多少期望值 int N; bool dfs(int girl) { vis_girl[girl] = true; for (int boy = 0; boy < N; ++boy) { if (vis_boy[boy]) continue; // 每一轮匹配 每个男生只尝试一次 int gap = ex_girl[girl] + ex_boy[boy] - love[girl][boy]; if (gap == 0) { // 如果符合要求 vis_boy[boy] = true; if (match[boy] == -1 || dfs( match[boy] )) { // 找到一个没有匹配的男生 或者该男生的妹子可以找到其他人 match[boy] = girl; return true; } } else { slack[boy] = min(slack[boy], gap); // slack 可以理解为该男生要得到女生的倾心 还需多少期望值 取最小值 备胎的样子【捂脸 } } return false; } int KM() { memset(match, -1, sizeof match); // 初始每个男生都没有匹配的女生 memset(ex_boy, 0, sizeof ex_boy); // 初始每个男生的期望值为0 // 每个女生的初始期望值是与她相连的男生最大的好感度 for (int i = 0; i < N; ++i) { ex_girl[i] = love[i][0]; for (int j = 1; j < N; ++j) { ex_girl[i] = max(ex_girl[i], love[i][j]); } } // 尝试为每一个女生解决归宿问题 for (int i = 0; i < N; ++i) { fill(slack, slack + N, INF); // 因为要取最小值 初始化为无穷大 while (1) { // 为每个女生解决归宿问题的方法是 :如果找不到就降低期望值,直到找到为止 // 记录每轮匹配中男生女生是否被尝试匹配过 memset(vis_girl, false, sizeof vis_girl); memset(vis_boy, false, sizeof vis_boy); if (dfs(i)) break; // 找到归宿 退出 // 如果不能找到 就降低期望值 // 最小可降低的期望值 int d = INF; for (int j = 0; j < N; ++j) if (!vis_boy[j]) d = min(d, slack[j]); for (int j = 0; j < N; ++j) { // 所有访问过的女生降低期望值 if (vis_girl[j]) ex_girl[j] -= d; // 所有访问过的男生增加期望值 if (vis_boy[j]) ex_boy[j] += d; // 没有访问过的boy 因为girl们的期望值降低,距离得到女生倾心又进了一步! else slack[j] -= d; } } } // 匹配完成 求出所有配对的好感度的和 int res = 0; for (int i = 0; i < N; ++i) res += love[ match[i] ][i]; return res; } int main() { while (~scanf("%d", &N)) { for (int i = 0; i < N; ++i) for (int j = 0; j < N; ++j) scanf("%d", &love[i][j]); printf("%d\n", KM()); } return 0; }
我们来分析一下它的时间复杂度。
①首先对左边的N个点进行匹配
②每次匹配至多标记N个左边的点
③每个标记的点要遍历N个右边的点
④因为匹配不成功时我们会进行+d、-d的操作,即得到一个新的点st连接到已经标记的图中,但这个新的点st可能已经匹配过了,且与他匹配的点无法转移到其他点,致使下次匹配还不能成功。在极端情况下可能会发生N次。每次发生后我们要重新进行②,③。
综上,时间复杂度可看做O(N^4)。网上一些博客说是O(N^3),其实是不对的。
改进:
通过上面的分析,我们知道问题主要出在④,每次找到新的点st后我们又要重新开始从头开始匹配,已经用匈牙利搜出来的部分就被浪费掉了。
有没有一种办法,能够接着上次进行匹配呢?答案是肯定的。
我们先通过这篇 博客 来了解交替路和增广路。
交替路:就是依次经过非匹配边(蓝线)、匹配边(红线)的路。
增广路:起点和终点都是非匹配点的交替路。
如下图(蓝色线表示非匹配边,红色线表示匹配边)
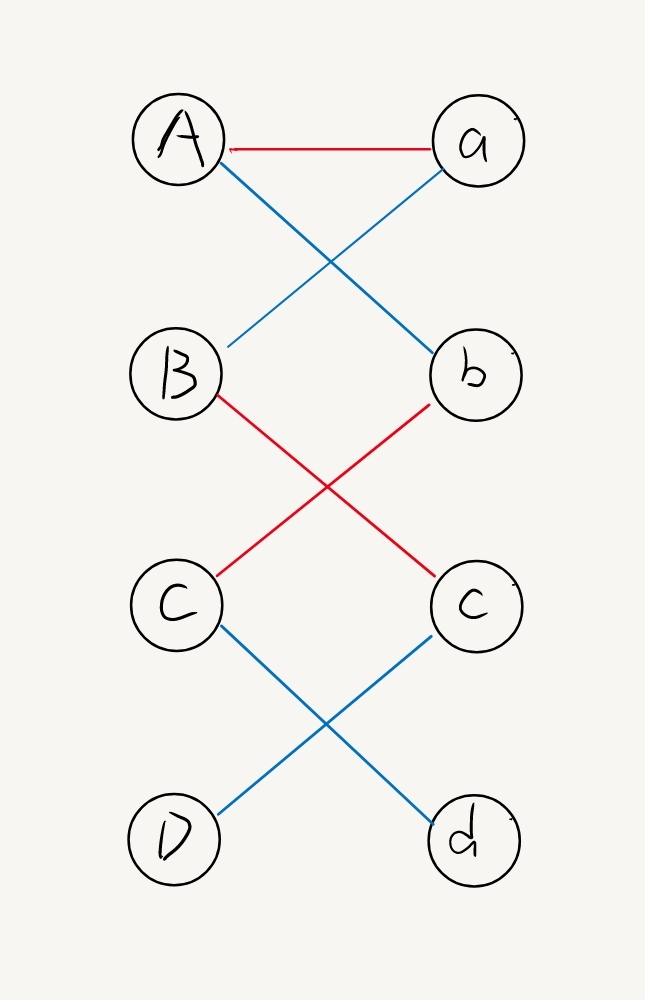
D-c-B-a-A-b-C-d 就是一个增广路。
通过性质我们知道,对其边进行取反操作,增广路上的点就会“乖乖的腾位置”,使得所有的点都变成匹配点。
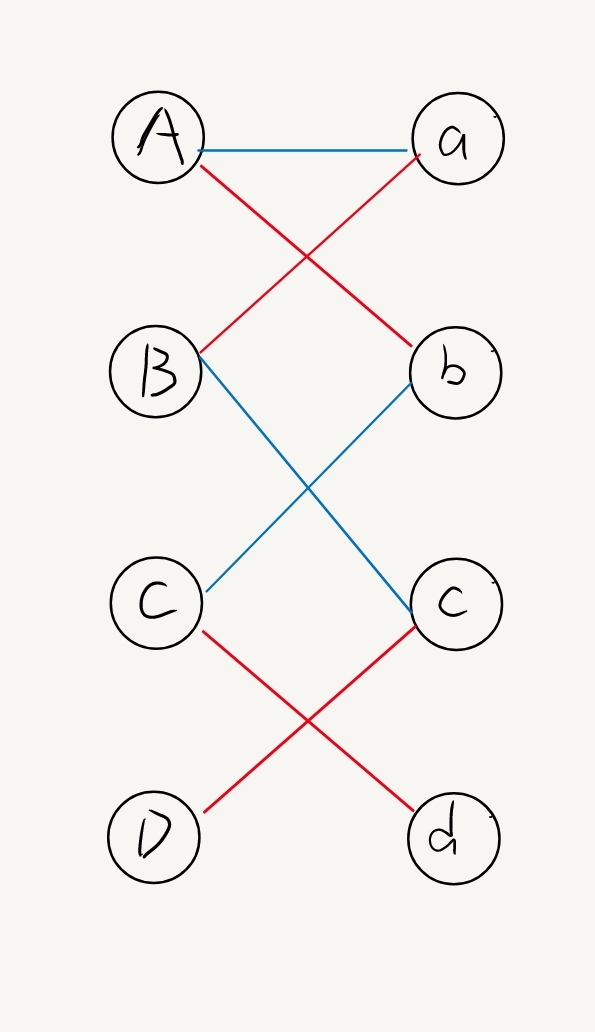
我们利用匈牙利算法进行匹配,其实就是找到了一个增广路。
利用这个性质,我们每次找到的新的点st,如果他是非匹配点,那么就找了一个完整的增广路,匹配结束,如果他是匹配点,那么我们大可以从他开始继续寻找非匹配点,二不用从头开始。
最后我们仅会找到一条完整的增广路,所以总体的时间复杂度为O(N^3)。
改进代码:牛客Jewels
#include <bits/stdc++.h> using namespace std; #define int long long const int N = 300 + 10, INF = 0x3f3f3f3f3f3f3f3f; int n; int w[N][N]; // 边权 左部点到右部点 int la[N], lb[N], upd[N]; // 左、右部点的顶标 bool va[N], vb[N]; // 访问标记:是否在交错树中 int match[N]; // 右部点匹配了哪一个左部点 int last[N]; // 右部点在交错树中的上一个右部点,用于倒推得到交错路 bool dfs(int u, int fa) { va[u] = 1; for (int v = 1; v <= n; v++) if (!vb[v]) if (fabs(la[u] + lb[v] == w[u][v])) { // 相等子图 vb[v] = 1; last[v] = fa; if (!match[v] || dfs(match[v], v)) { match[v] = u; return true; } } else if (upd[v] > la[u] + lb[v] - w[u][v]) { upd[v] = la[u] + lb[v] - w[u][v]; last[v] = fa; } return false; } void KM() { for (int i = 1; i <= n; i++) { la[i] = -INF; last[i] = match[i] = lb[i] = 0; for (int j = 1; j <= n; j++) la[i] = max(la[i], w[i][j]); } for (int i = 1; i <= n; i++) { for (int j = 1; j <= n; j++) upd[j] = INF, va[j] = vb[j] = 0; // 从右部点st匹配的左部点match[st]开始dfs,一开始假设有一条0-i的匹配 int st = 0; match[0] = i; while (match[st]) { // 当到达一个非匹配点st时停止 int delta = INF; if (dfs(match[st], st)) break; for (int j = 1; j <= n; j++) if (!vb[j] && delta > upd[j]) { delta = upd[j]; st = j; // 下一次直接从最小边开始DFS } for (int j = 1; j <= n; j++) { // 修改顶标 if (va[j]) la[j] -= delta; if (vb[j]) lb[j] += delta; else upd[j] -= delta; } vb[st] = true; //将其加入到增广路中 } while (st) { // 倒推更新增广路,对增广路取反 match[st] = match[last[st]]; st = last[st]; } } } signed main() { ios::sync_with_stdio(false); cin.tie(0); cin >> n; for (int i = 1, x, y, z, v; i <= n; i++) { cin >> x >> y >> z >> v; for (int j = 1; j <= n; j++) { w[i][j] = -x * x - y * y - z * z; z += v; } } KM(); int ans = 0; for (int i = 1; i <= n; i++) ans -= w[match[i]][i]; cout << ans; return 0; }

