链表入门1(C语言的方式讲解)
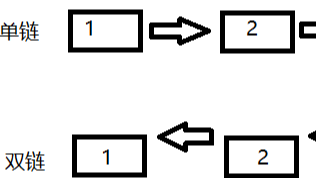 如果你想了解一下链表,不妨来看看吧
如果你想了解一下链表,不妨来看看吧
什么是链表?
如果想知道什么是链表,你得先知道什么是顺序表。
1. 顺序表就是物理结构上连续。同时,在逻辑结构上也是连续线性的。经典中的经典就是数组!

物理结构就是他们的地址是连续的。逻辑结构是连续线性的,只要你按照他们的小标走总是可以找到他们的位置。
那么链表是什么?为什么会有链表的存在?
链表就是一环扣一环的结构,在逻辑上与顺序表一样是线性的,但是在物理结构上与顺序表不同;
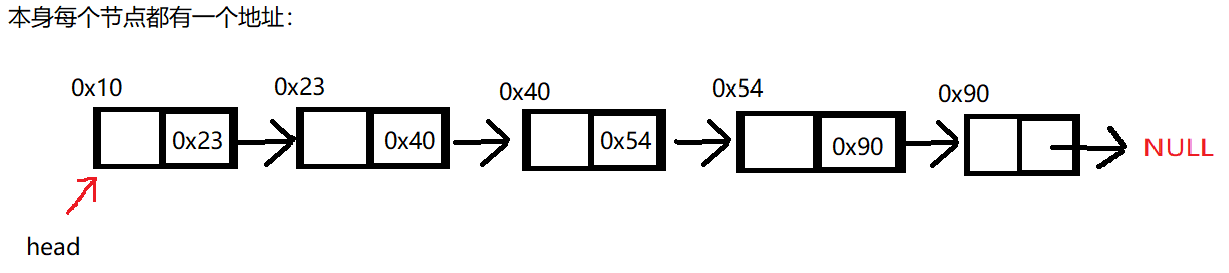
大家一开始看这个肯定有点懵,为什么是这样?先看这张图有个基本印象,下面我还将用这种图给大家一一讲解
我们用大金链子来形容链表真是在好不过了,但是链表仅仅只是逻辑上是线性的,不像大金链子物理上也是连在一起。实际上,链表的存储一般是在堆区,这块地方是动态开辟的,所以我们对于数据的存储和释放也更加灵活,对比于顺序表存储的头插法,顺序表要先将所有元素往后移,才能存到第一个位置,链表直接把新节点指向之前的第一个节点,再把之前第一个节点指向新的节点就可以了,方便很多。删也是如此。讲到这可能真要疯了,你之前讲的是什么,这不是链表入门吗?放心我一般讲完就会放个图给大伙理解理解。

这样看应该是能理解的,不需要深入,如果你要研究一下这方面的东西,我建议你去看看《程序员的自我修养》
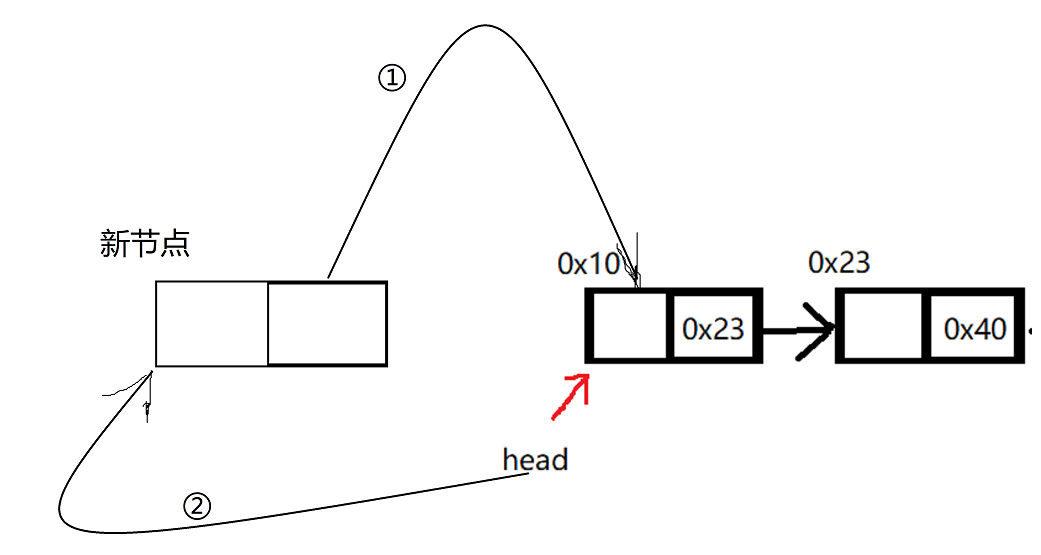
红色是代表之前的状态,黑色是之后的状态;如果第一步跟第二步颠倒了,那我们就失去了head红色指向的空间,所以链表很讲究顺序问题
2. 链表的存在就是为了弥补上顺序表的缺点,顺序表不能很好的利用空间,有可能会造成空间浪费;链表一般的增删都比顺序表要高效;
链表有什么用
之前说了,链表是按顺序表的缺点来设计的,那其实它的用途就是为了弥补上顺序表的不足。
- 顺序表无法做到任意插入删除的时间复杂度为O(n),而链表的插入删除,就直接找到你要查找的值,然后简单的换一下指向就可以了。
- 链表的空间使用十分灵活,你要用就开一个,不用就销毁一个,而顺序表一旦开辟了空间,删除数据其实是没有把数据内存释放的,顺序表对于空间的使用很难把握。
定义一个链表
链表链表,那自然少不了开头的第一个吧?所以我们先定义一个头。那链表的身体怎么表示?对了,我们就模仿大金链子一样,给一个一个环当成一个点,我们就暂时称为节点吧。开头第一个好像也可以是个节点,那我们是不是可以抽象出一个东西,在C语言中,好像没法直接定义这样的东西......对了,结构体,就是结构体,我们可以用结构体。那我们就先开始尝试用结构题来定义节点吧!
typedef struct SListNode
{
int data;//存放一个数据
struct SListNode next;//存放下一个节点的位置
}SLTNode;
大致写成了这样,我觉得很完美,跟上面想的结构一模一样。问问自己,这样写对吗?......好像有点不对,位置应该是个地址,不应该是个结构体变量,额,我们要改进
typedef struct SListNode
{
int data;//存放一个数据
struct SListNode* next;//下一个节点的地址
}SLTNode;
这样总可以了吧,很完美了,我想说的是,对,挺完美,但是链表难道只能存int型数据吗? ...答案显而易见,不止。那让我们最后来创建一次
typedef int SListElemType;
typedef struct SListNode
{
SListElemType data;//存放一个数据
struct SListNode* next;//下一个节点的地址
}SLTNode;
这样写,到时我们想写什么就去改SListElemType 的自定义类型就够了
上面定义好了链表的节点,现在我们开始,试着往里面加点数据试试,先画个图
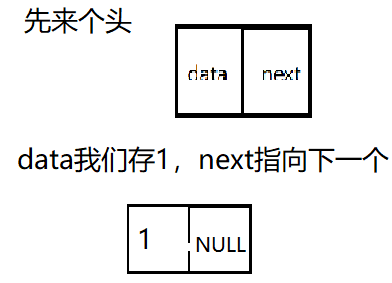
有点不行这样,第一个节点如果进去就存数据,那我们要是只要一个不存数据的链表怎么表示?再画个图
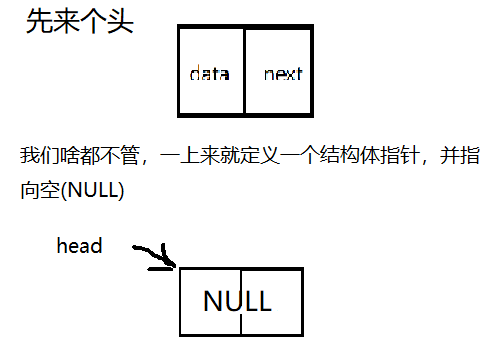
这样可以了,我们大功告成了一个不存数据的链表
接下来,我们放数据
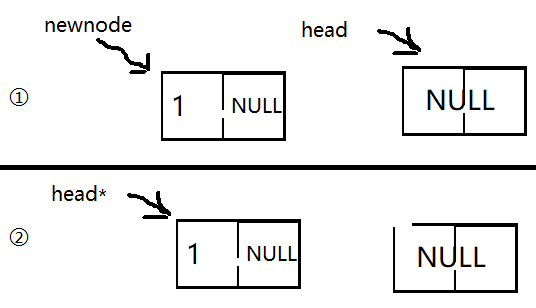
这种情况是存入一个空的链表,如果是之前就有数据了呢?图中的星号表示是最新的意思
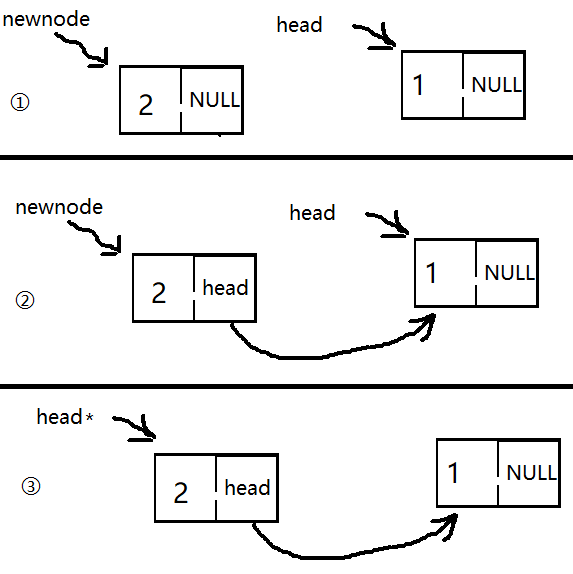
如果有一个以上的数据呢?图中的星号表示是最新的意思
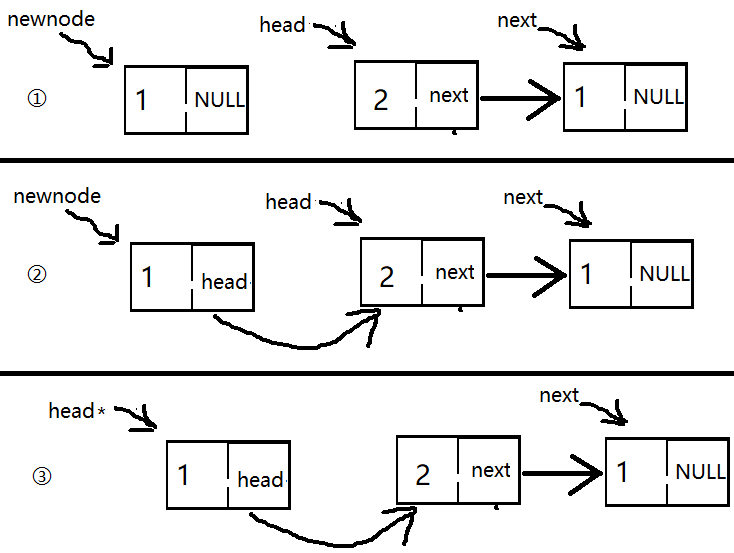
图中的星号表示的是最新的意思
稍微抽象出来,除了空,一个数据的存入跟一个数据以上的存入是一样的逻辑;
1.空就是直接把头指向新节点就可以了;
2.但是,一个数据的存入跟一个数据以上的存入不同,我们先把新节点指向了旧的头结点,再把旧的头结点指向新节点就可以了;旧的头结点就是每个图中的head,带星号的head是存入数据后最新头结点
我们来尝试写写代码吧!,这里为了减少大家的负担我就把创建节点写成了BuySListNode(x),大家不用在意这个函数的细节,只需知道这个函数功能就是创建一个节点即可,跟图上newnode的是吻合
void SListPushFront(SLTNode* phead, SListElemType x)//传参传的是头结点,跟你要加进来的数据
{
SLTNode* NewNode = BuySListNode(x);//新建一个节点
if (phead == NULL)//空的情况
phead = NewNode;
else//第二种情况
{
NewNode->next = phead;//NewNode指针访问next成员,把next赋值给了phead,意思就是把新节点指向了旧头结点
phead = NewNode;//phead头结点再次指向新节点
}
}
这里写的代码完全按照上图的内容写出来的,->是结构体指针访问结构体成员的操作符;
细心的同学可能就发现了空的情况好像跟第二种也没什么区别,因为当NewNode->next = phead;如果phead = NULL,其实就是在给新节点的next指向了NULL,而本身新节点里的next就是指向NULL,所以可以合并。
void SListPushFront(SLTNode* phead, SListElemType x)//传参传的是头结点,跟你要加进来的数据
{
SLTNode* NewNode = BuySListNode(x);//新建一个节点
//第二种情况
NewNode->next = phead;//NewNode指针访问next成员,把next赋值给了phead,意思就是把新节点指向了旧头结点
phead = NewNode;//phead头结点再次指向新节点
}
如果你认为写成这样就可以了,那还是差了一点火候,不过如果你可以理解这个函数为什么这样写,其实就差不多了;ok,为什么还不行,是因为你用了phead = NewNode这个赋值语句,一般传参其实不是把实参给函数,而是赋值一备份给函数,所以如果你想改phead的值,那得传二级指针。更新一下代码
void SListPushFront(SLTNode** pphead, SListElemType x)//传参传的是头结点的地址,跟你要加进来的数据
{
SLTNode* NewNode = BuySListNode(x);//新建一个节点
NewNode->next = *pphead;//NewNode指针访问next成员,把next赋值给了phead,意思就是把新节点指向了旧头结点
*pphead = NewNode;//phead头结点再次指向新节点
}
总结
- 如果你不理解的话,可以试着自己像这样画个图,我相信你一定可以整的明白。
- 这个存储方法就是最经典的单链表头插法,你如果继续深入学习,你还会学尾插法,双链表等等,这里我们只是入门,只是带你大概清楚链表是怎么来的,及一些简单的使用
链表的逻辑结构
现在我们重新看一下这张图
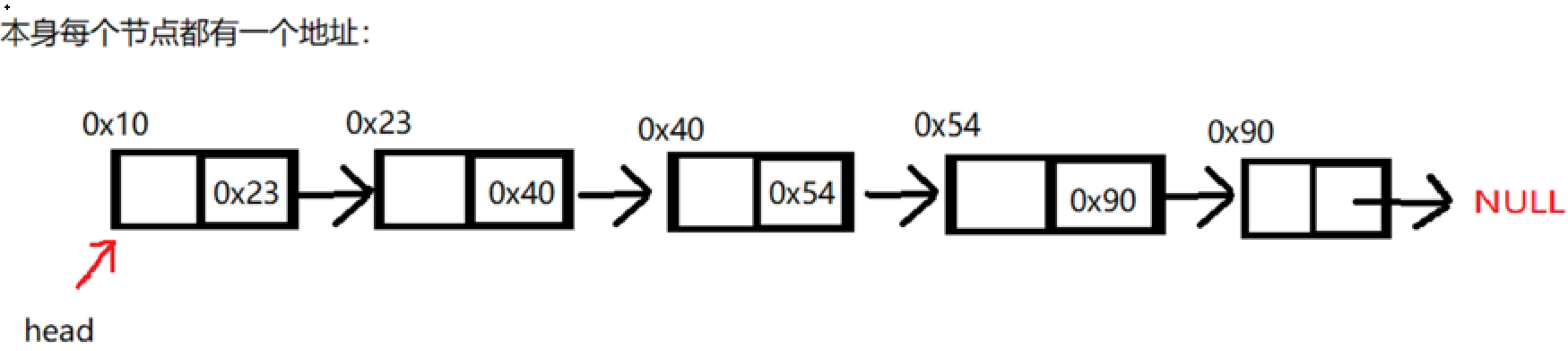
这就是链表的逻辑结构,节点就是结构体变量,它不是指针,每个节点都有自己的地址,但是第一个头结点,我们一般是定义成一个指针,如果你不想定义成指针也可以,就是操作链表没那么方便,通过访问节点里存放的地址,我们就可以访问下一个节点,依次操作,就可以找到所有存储的数据,这也就是我们说它很像大金链子,但不完全是。
之后我可以会继续讲解,看情况吧,这期就这样了,虽然做的不咋地,如果你看完这篇觉得你对链表还挺感兴趣的,也算达到我的目的了
