Mac基于Docker搭建Hadoop集群
写在前面,本博客大部分内容,参考了:https://zhuanlan.zhihu.com/p/59758201
一、Docker下载Ubuntu:
1.首先,需要安装Docker,如果没有安装的,可以参考博客:https://www.runoob.com/docker/macos-docker-install.html
2.现在的 Docker 网络能够提供 DNS 解析功能,我们可以使用如下命令为接下来的 Hadoop 集群单独构建一个虚拟的网络:
sudo docker network create --driver=bridge hadoop
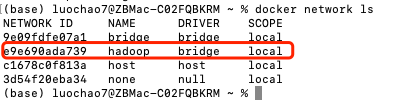
使用下面这个命令查看 Docker 中的网络,可以看到刚刚创建的名为 hadoop 的虚拟桥接网络:
sudo docker network ls
3.查找 ubuntu 容器:
dhu719@dhu719:~$ sudo docker search ubuntu NAME DESCRIPTION STARS OFFICIAL AUTOMATED ubuntu Ubuntu is a Debian-based Linux operating sys… 9326 [OK] dorowu/ubuntu-desktop-lxde-vnc Docker image to provide HTML5 VNC interface … 281 [OK] rastasheep/ubuntu-sshd Dockerized SSH service, built on top of offi… 209 [OK] consol/ubuntu-xfce-vnc Ubuntu container with "headless" VNC session… 161 [OK] ubuntu-upstart Upstart is an event-based replacement for th… 97 [OK] ansible/ubuntu14.04-ansible Ubuntu 14.04 LTS with ansible 96 [OK] neurodebian NeuroDebian provides neuroscience research s… 56 [OK] 1and1internet/ubuntu-16-nginx-php-phpmyadmin-mysql-5 ubuntu-16-nginx-php-phpmyadmin-mysql-5 49 [OK] ubuntu-debootstrap debootstrap --variant=minbase --components=m… 40 [OK] nuagebec/ubuntu Simple always updated Ubuntu docker images w… 23 [OK] tutum/ubuntu Simple Ubuntu docker images with SSH access 19
4.下载 ubuntu 16.04 版本的镜像文件:
dhu719@dhu719:~$ sudo docker pull ubuntu:16.04 16.04: Pulling from library/ubuntu 34667c7e4631: Pull complete d18d76a881a4: Pull complete 119c7358fbfc: Pull complete 2aaf13f3eff0: Pull complete Digest: sha256:58d0da8bc2f434983c6ca4713b08be00ff5586eb5cdff47bcde4b2e88fd40f88 Status: Downloaded newer image for ubuntu:16.04 dhu719@dhu719:~$
5.查看已经下载的镜像:
dhu719@dhu719:~$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> ccac37c7045c 4 days ago 1.85GB ubuntu 16.04 9361ce633ff1 7 days ago 118MB dhu719@dhu719:~$
6.根据镜像启动一个容器,可以看出 shell 已经是容器的 shell 了(第二行开头,已经是root用户了):
dhu719@dhu719:~$ sudo docker run -it ubuntu:16.04 /bin/bash root@fab4da838c2f:/#
7.推出虚拟机:输入 exit
root@fab4da838c2f:/# exit
exit
dhu719@dhu719:~$
二、Dokcer常见容器使用命令:
1.查看正在运行的容器: docker ps
2.查看所有容器:docker ps -a
3.启动一个状态为退出的容器,最后一个参数为容器 ID: docker start fab4da838c2f
4.进入一个容器:docker exec -it fab4da838c2f /bin/bash
5.关闭一个正在运行的容器:docker stop fab4da838c2f (注:最好是结合 docker ps 使用,先查看哪些在运行,然后把容器 id复制一下,就可以使用这个命令关闭了)
三、初始化虚拟机
主要是安装 JDK 1.8 的环境,因为 Spark 要 Scala,Scala 要 JDK 1.8,以及 Hadoop,以此来构建基础镜像。
1.进入之前的 Ubuntu 容器,修改 apt源:
cp /etc/apt/sources.list /etc/apt/sources_init.list
2.删除旧源文件:
rm /etc/apt/sources.list
3.使用 echo 命令将源写入新文件(将如下数据源,写到 /etc/apt/sources.list, 如果提示 : vim : command not found,参考:https://www.cnblogs.com/luo-c/p/15976329.html)
deb http://mirrors.aliyun.com/ubuntu/ xenial main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb http://mirrors.aliyun.com/ubuntu/ xenial universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
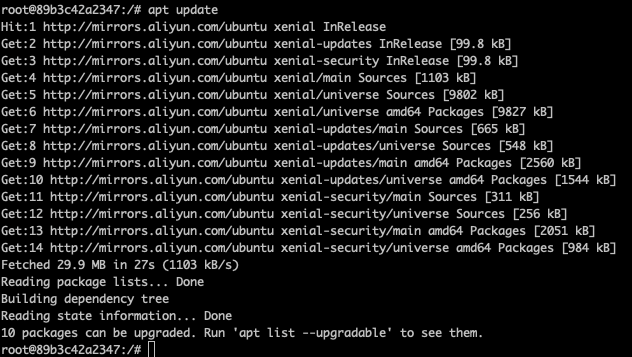
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe然后使用 : apt update 更新数据源:
4.安装Java,可以使用如下命令自动,也可以自己手动安装,手动安装需要先下载到本机,然后将jdk文件传入容器中
apt install openjdk-8-jdk
安装完成之后,使用:java -version 来查看是否安装成功,显示 java版本号就是成功了。
5.安装Scala(原文中Scala是为了安装Spark安装的,此处也可以一并安装了)
apt install scala
安装完成后,输入:scala,测试是否成功

要是 Ctrl + D不行的话,也可以试试 Ctrl + C 退出。
6.安装 Vim工具
apt install vim
7.安装 net-tools工具
apt install net-tools
8.配置免密登陆:
- 安装 SSH:
root@fab4da838c2f:/# apt-get install openssh-server
- 安装 SSH 的客户端:
root@fab4da838c2f:/# apt-get install openssh-client
- 进入当前用户的用户根目录
root@fab4da838c2f:/# cd ~
root@fab4da838c2f:~#
- 生成密钥,不用输入,一直回车就行,生成的密钥在当前用户根目录下的
.ssh文件夹中
root@fab4da838c2f:~# ssh-keygen -t rsa -P ""
- 将公钥追加到 authorized_keys 文件中
root@fab4da838c2f:~# cat .ssh/id_rsa.pub >> .ssh/authorized_keys root@fab4da838c2f:~#
- 启动 SSH 服务
root@fab4da838c2f:~# service ssh start * Starting OpenBSD Secure Shell server sshd [ OK ] root@fab4da838c2f:~#
- 免密登录自己
root@fab4da838c2f:~# ssh 127.0.0.1 Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.15.0-45-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Last login: Tue Mar 19 07:46:14 2019 from 127.0.0.1 root@fab4da838c2f:~#
- 修改
.bashrc文件,启动 shell 的时候,自动启动 SSH 服务,用 vim 打开.bashrc文件
root@fab4da838c2f:~# vim ~/.bashrc
将光标移动到最后面,添加一行:
service ssh start
添加完的结果为,只显示最后几行:
if [ -f ~/.bash_aliases ]; then . ~/.bash_aliases fi # enable programmable completion features (you don't need to enable # this, if it's already enabled in /etc/bash.bashrc and /etc/profile # sources /etc/bash.bashrc). #if [ -f /etc/bash_completion ] && ! shopt -oq posix; then # . /etc/bash_completion #fi service ssh start
退出编辑,保存修改。此时,SSH 免密登录已经完全配置好。
四、安装Hadoop集群
1.下载Hadoop的安装文件(由于参考的博客中链接已经失效,可以使用清华的镜像链接):
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
2.解压到 /usr/local 目录下面并重命名文件夹
root@fab4da838c2f:~# tar -zxvf hadoop-3.2.2.tar.gz -C /usr/local/ root@fab4da838c2f:~# cd /usr/local/ root@fab4da838c2f:/usr/local# mv hadoop-3.2.2 hadoop root@fab4da838c2f:/usr/local#
3.修改 /etc/profile 文件,添加一下环境变量到文件中,使用: vim /etc/profile 打开文本编辑器,在尾部增加如下:
注:JAVA_HOME 为 JDK 安装路径,使用 apt 安装就是这个,用 update-alternatives --config java 可查看(我这里是自己手动安装的 java环境)
#java export JAVA_HOME=/java/jdk1.8.0_191/ export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH #hadoop export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop export HDFS_DATANODE_USER=root export HDFS_DATANODE_SECURE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_NAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
4.使环境变量生效
root@fab4da838c2f:/usr/local# source /etc/profile
root@fab4da838c2f:/usr/local#
五、配置Hadoop环境(重点来了)
Hadoop配置中,有5个文件是重点配置的,分别是:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers,下面就一个个开始配置:
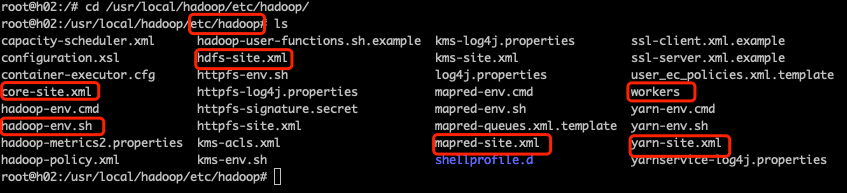
进入Hadoop安装路径(我这里是根目录下面的 /usr/local/hadoop),进入 ./etc/hadoop/,可以看到都是一些配置文件,如下图所示:
1.修改 hadoop-env.sh 文件,在文件末尾添加以下信息(JAVA_HOME根据自己的修改):
export JAVA_HOME=/java/jdk1.8.0_191 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
2.修改 core-site.xml,修改为:
<configuration>
<!--指定nameNode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://h01:8020</value> </property> <!--指定Hadoop数据的存储目录--> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/data</value> </property> <!--配置HDFS网页登陆使用的静态用户,配置这个之后才有权限可以在网页端删除文件、文件夹--> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>
3.修改hdfs-site.xml,修改为:
<configuration>
<!--文件的存储个数--> <property> <name>dfs.replication</name> <value>3</value> </property>
<!--nn web端访问地址,使用网页访问HDFS文件系统就是这个端口--> <property> <name>dfs.namenode.http-address</name> <value>h01:9870</value> </property>
<!--2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>h01:9868</value> </property>
<!--网页查看HDFS文件内容,出现Couldn‘t preview the file报错,需要配置的参数--> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
4.修改mapred-site.xml,修改为:
<configuration>
<!--指定MapReduce程序运行在Yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5.修改yarn-site.xml,修改为:
<configuration>
<!--指定MR走 shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h01</value>
</property>
<!--环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
6.修改workers,修改为:
h01
h02
h03
注意:h01这些后面不要有空格!h03后面,不要有空的行!自己准备起多少集群,就在这里写几个,要是准备起5个集群,就写到h05。
六、在Docker中启动集群
1.先将当前容器导出为镜像(使用自己的ubuntu容器id),并查看当前镜像
dhu719@dhu719:~$ sudo docker commit -m "hadoop" -a "hadoop" fab4da838c2f newuhadoop sha256:648d8e082a231919faeaa14e09f5ce369b20879544576c03ef94074daf978823 dhu719@dhu719:~$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE newuhadoop latest 648d8e082a23 7 seconds ago 1.82GB <none> <none> ccac37c7045c 4 days ago 1.85GB ubuntu 16.04 9361ce633ff1 7 days ago 118MB dhu719@dhu719:~$
2.启动3个终端(注意,是要开3个终端!!!)
- 第一条命令启动的是
h01是做 master 节点的,所以暴露了端口,以供访问 web 页面
sudo docker run -it --network hadoop -h h01 --name "h01" -p 9870:9870 -p 8088:8088 newuhadoop /bin/bash
- 后面几条命令就基本类似,第二条命令
sudo docker run -it --network hadoop -h h02 --name "h02" newuhadoop /bin/bash
- 第三条命令
sudo docker run -it --network hadoop -h h03 --name "h03" newuhadoop /bin/bash
3.接下来,在 h01 主机中,启动 Haddop 集群
先进行格式化操作,不格式化操作,hdfs起不来(只有第一次启动的时候需要初始化,以后启动就不需要了,先删除所有机器的 data和logs目录,然后再进行格式化):
root@h01:/usr/local/hadoop# ./bin/hdfs namenode -format
然后启动HDFS集群:
root@h01:/usr/local/hadoop# ./sbin/start-dfs.sh
最后,启动yarn集群管理节点:
root@h01:/usr/local/hadoop# ./sbin/start-yarn.sh
都启动完成后,使用 jps 命令查看:
root@h01:/usr/local/hadoop# jps 36435 Jps 36087 NodeManager 35959 ResourceManager 35306 SecondaryNameNode 34970 NameNode 35100 DataNode root@h01:/usr/local/hadoop#
可以看到,除了Jps,一共有5个进程,因为这里没有将 nameNode、ResourceManager、SecondaryNameNode分开部署,所以都在 h01这一台机器上,实际生产中,应该是需要分开部署的。
至此,Hadoop 集群已经构建好了。
七、网页访问、Hadoop命令
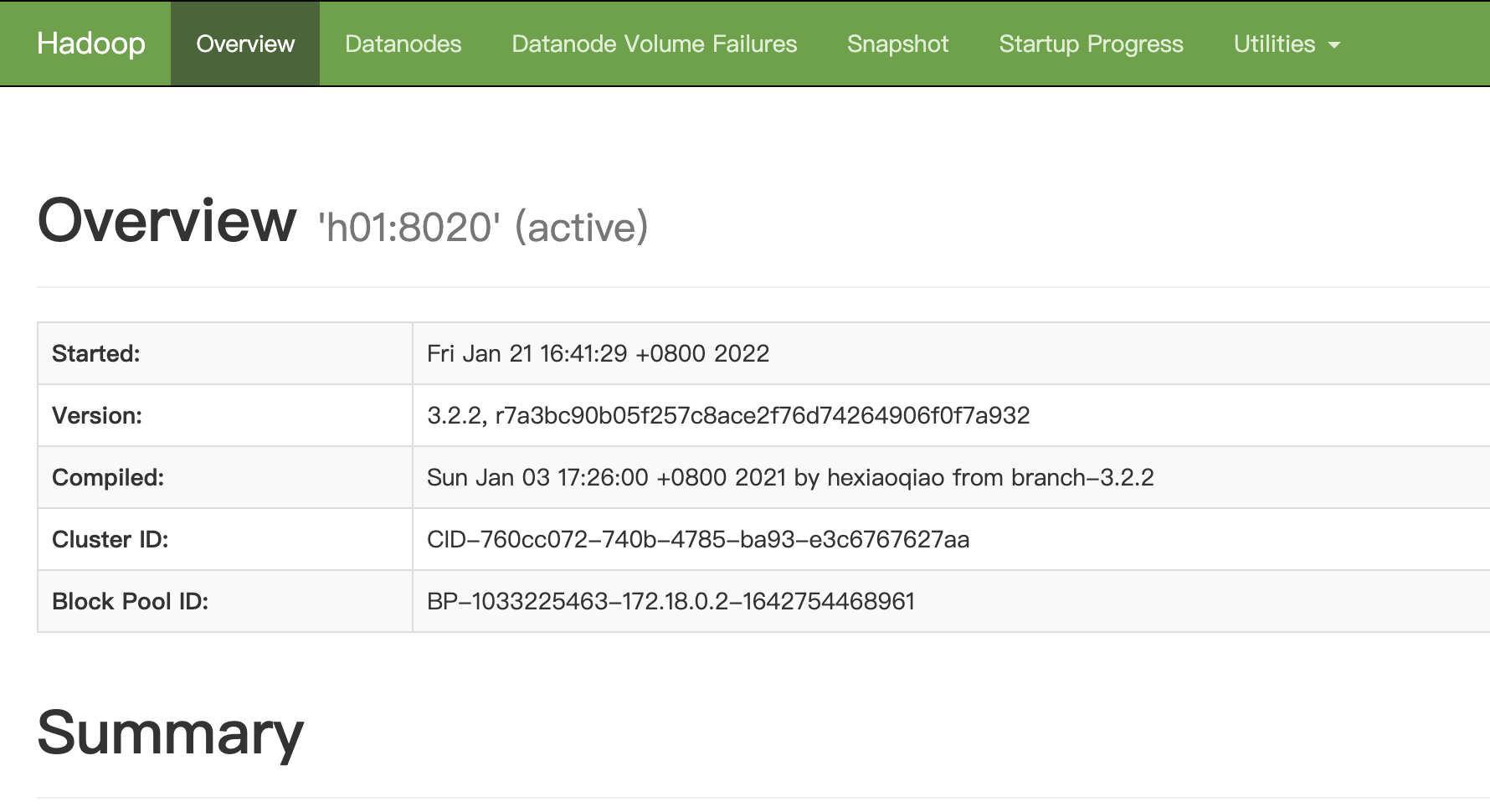
1.浏览器访问本机的9870端口,可以看到Hadoop的文件管理系统:
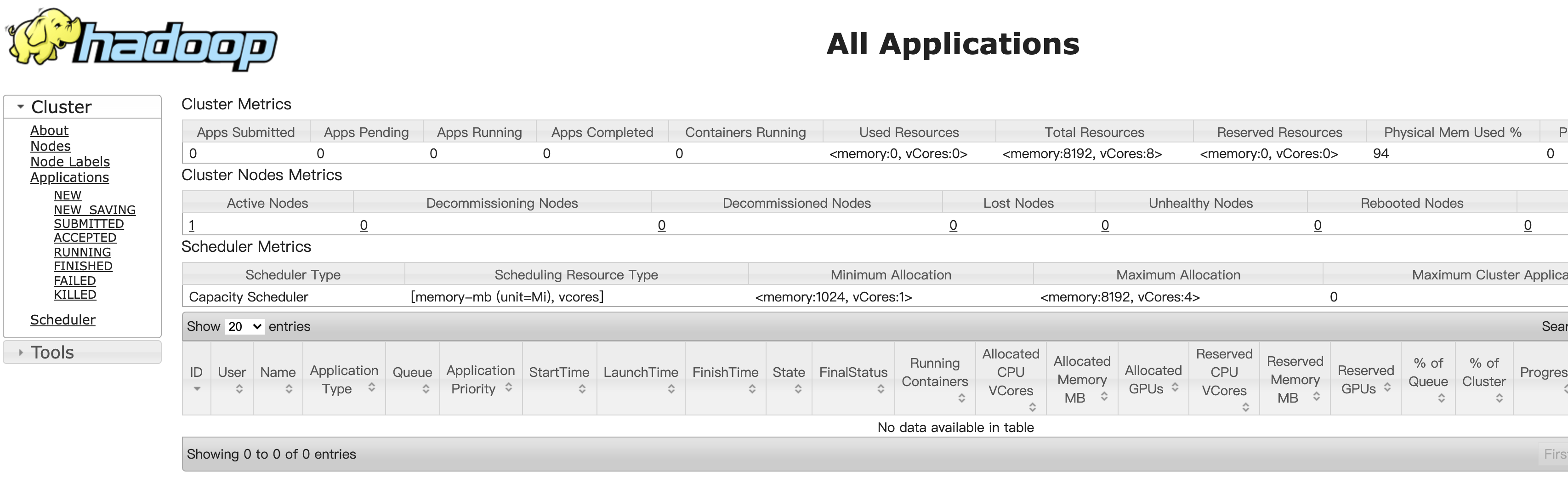
2.浏览器访问本机的8088端口,可以看到Hadoop中 Yarn的资源调度系统:
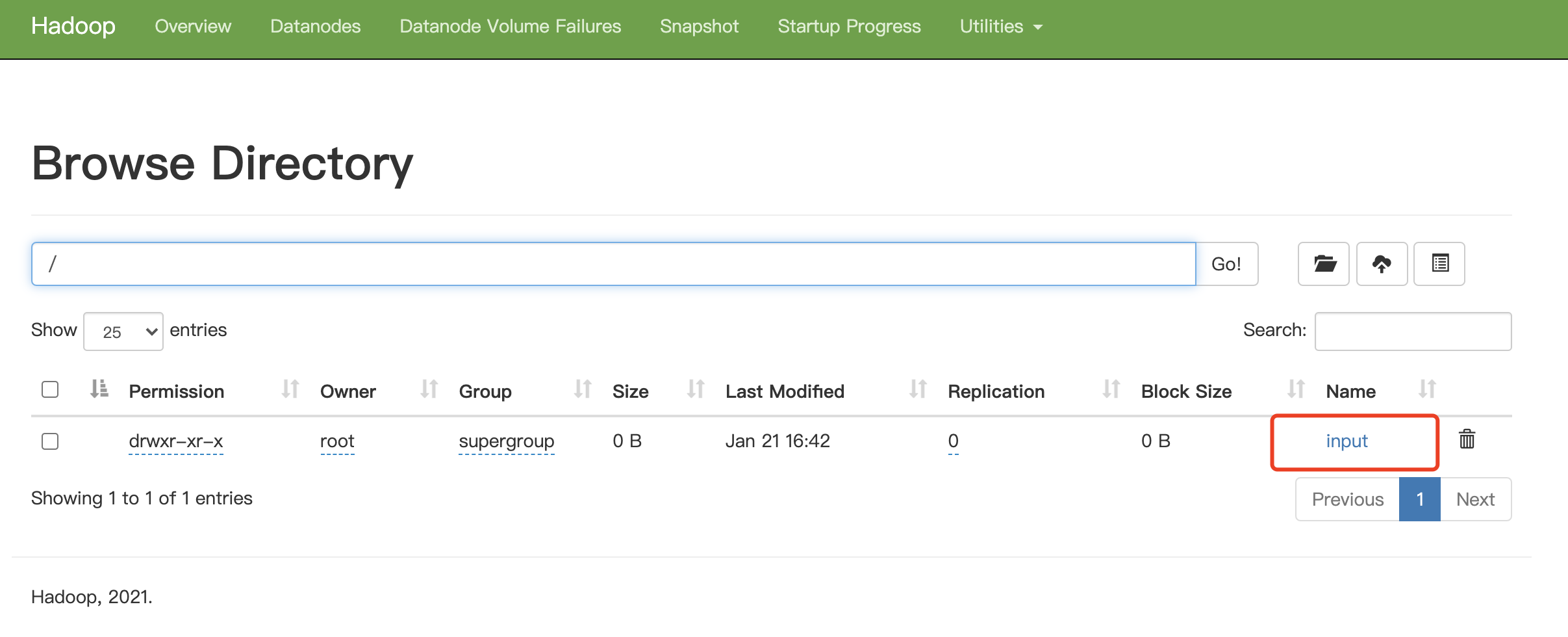
3.在 HDFS 中创建 input 文件夹:
root@h01:/usr/local/hadoop# ./bin/hadoop fs -mkdir /input
要是不想每次都输 ./bin,也可以 cd 进入到 bin目录中:
root@h01:/usr/local/hadoop/bin# ./hadoop fs -mkdir /input
在刚刚打开的网页上,点击进入文件管理系统:
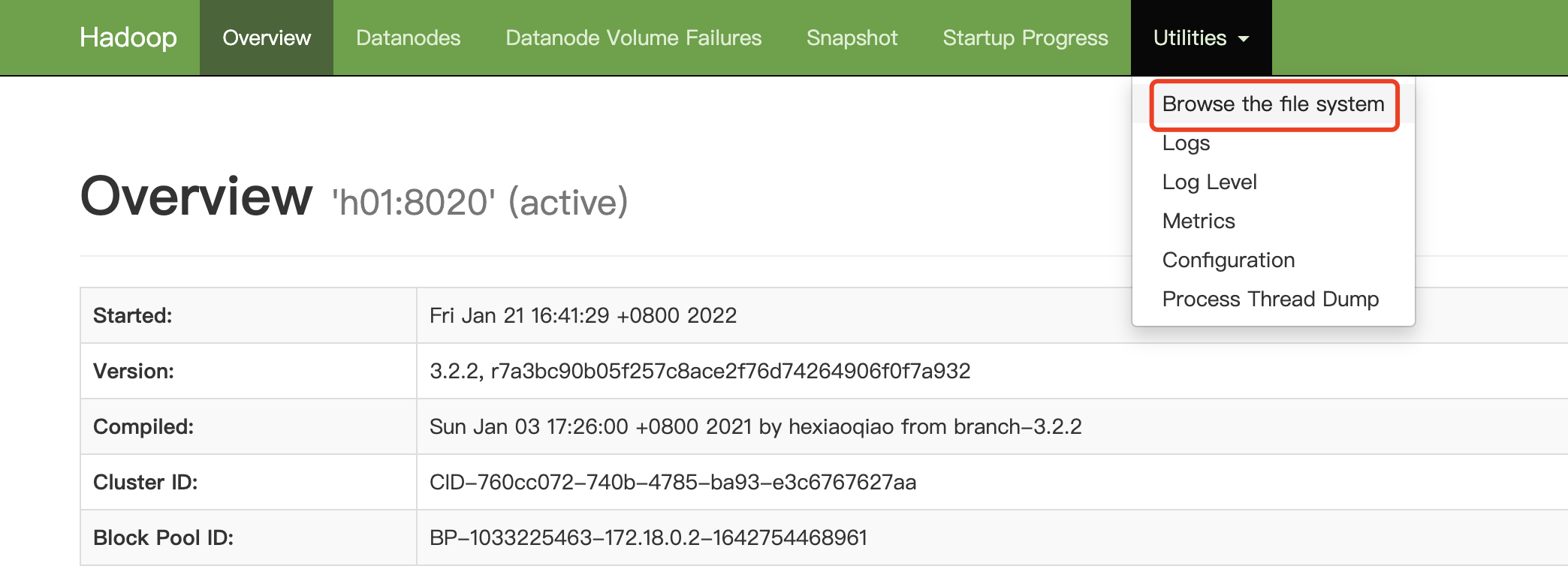
可以看到刚刚创建的文件夹:
4.上传文件
root@h01:/usr/local/hadoop# ls LICENSE.txt NOTICE.txt README.txt bin data etc include lib libexec logs sbin share text.txt root@h01:/usr/local/hadoop# ./bin/hadoop fs -put ./text.txt /input root@h01:/usr/local/hadoop#
在网页从点击 input文件夹可以看到:
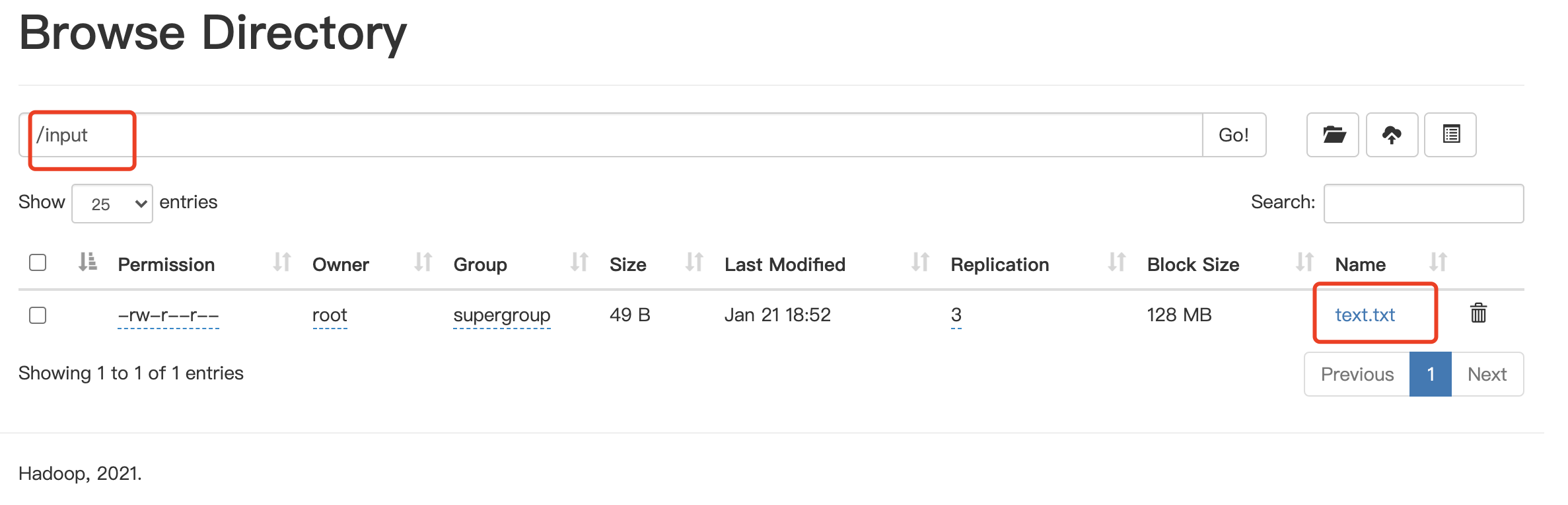
点击文件 text.txt,点击Tail the file 可以看到文件中最后32k的内容,或者也可以点击 Download下载文件
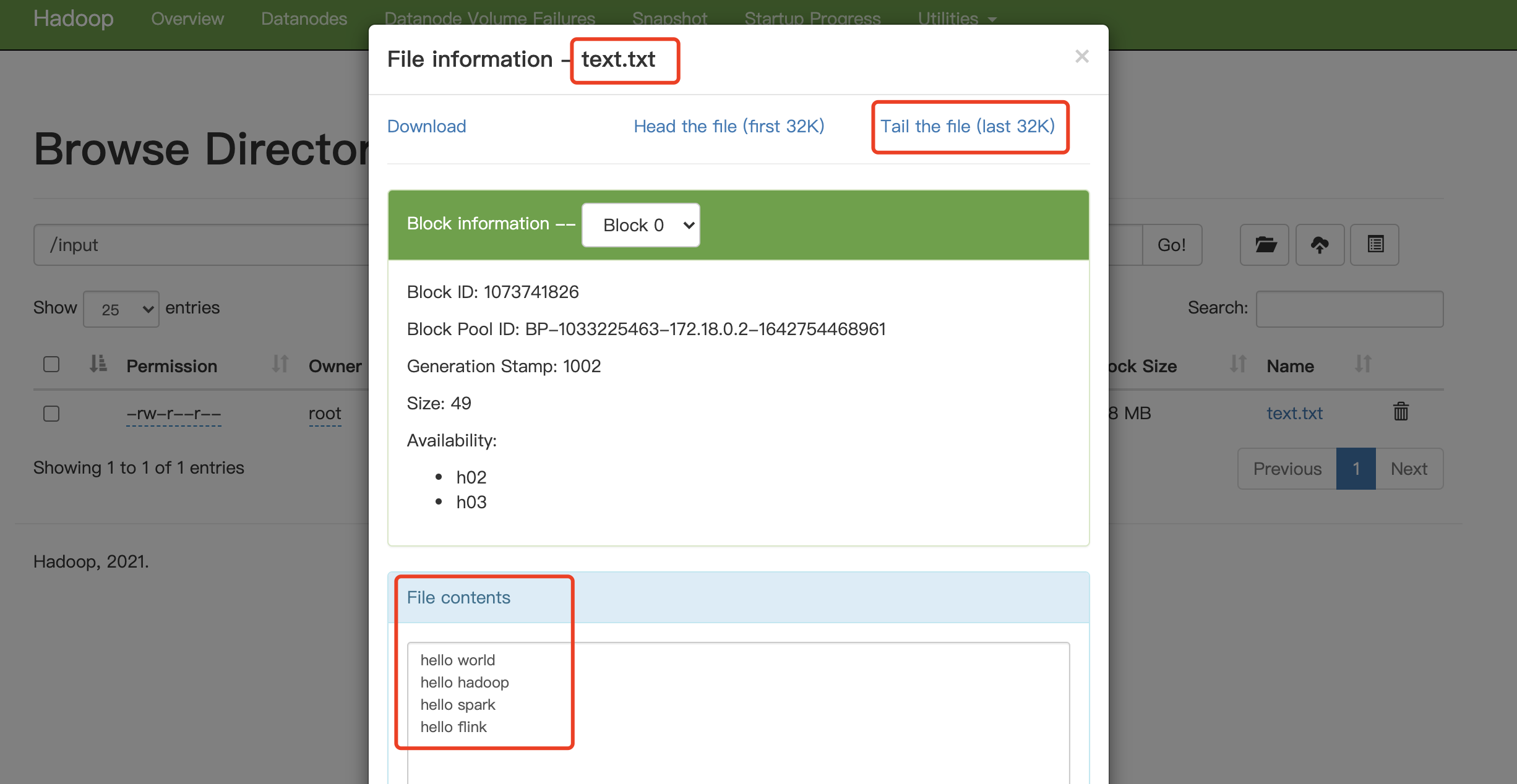
注:如果点击 Tail the file查看不了文件的内容,不要慌,配置下面的 “八、踩坑以及一些日常使用” - 第3、第4小节中的内容即可。
八、踩坑以及一些日常使用
1.单独启动/停止一台机器的HDFS组件: nameNode/ DataNode/ SecondaryNameNode
root@h01:/usr/local/hadoop# ./bin/hdfs --daemon start/stop namenode/datanode/secondarynamenode
2.单独启动/停止一台机器的Yarn组件:ResourceManager/ NodeManager
root@h01:/usr/local/hadoop# ./bin/yarn --daemon start/stop resourcemanager/ nodemanager
3.对于HDFS网页,查看文件的内容时,显示:Couldn‘t preview the file
修改浏览器所在系统的 hosts 文件(这里要用管理员权限 sudo)
sudo vim /etc/hosts
增加内容(Hadoop集群中各节点及主机名的映射):
172.18.0.2 h01 172.18.0.3 h02 172.18.0.4 h03
4.在Mac主机ping不通Docker容器中集群节点的地址:
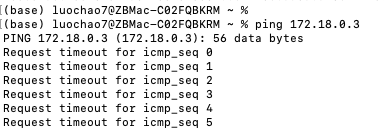
解决办法,见:https://www.cnblogs.com/luo-c/p/15830769.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号