李宏毅unsupervised learning-Word Embedding 课堂笔记
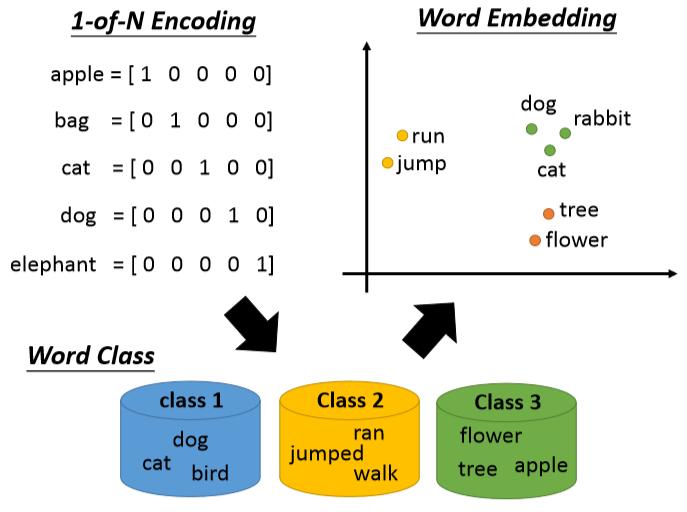 有多少个词汇就有多少维向量,只有表示它那维是1其他都是0。这样不知道词汇之间的关系,所以可以采用class。但是这样太粗糙了,引入word embedding。
有多少个词汇就有多少维向量,只有表示它那维是1其他都是0。这样不知道词汇之间的关系,所以可以采用class。但是这样太粗糙了,引入word embedding。
word embedding简介:

根据词汇的上下文找出它的vector
 count based:两个词经常一起出现,给他们一个相似的向量
count based:两个词经常一起出现,给他们一个相似的向量
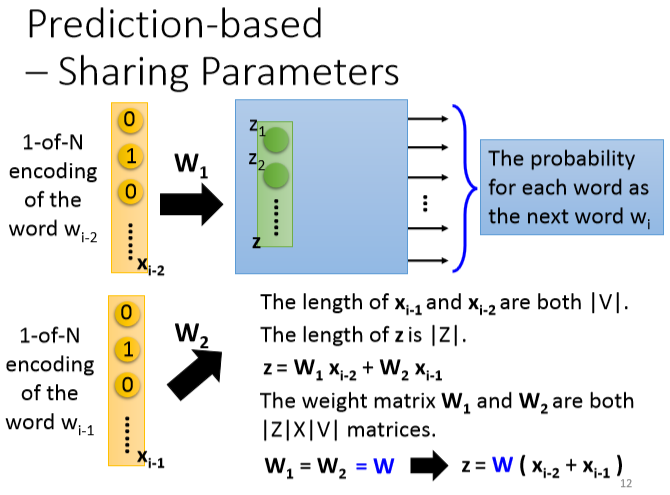
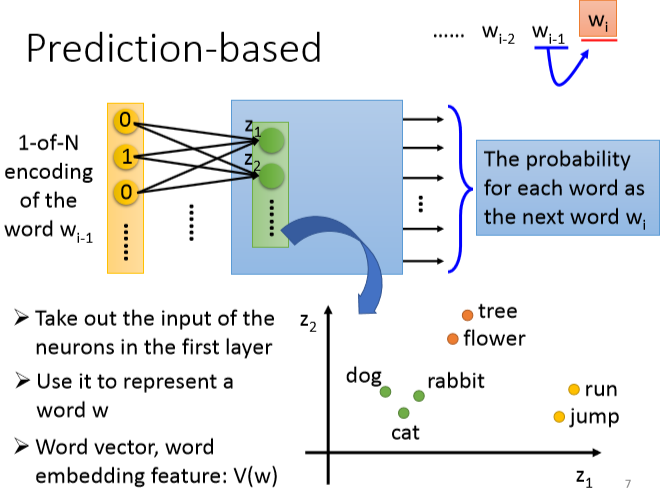
prediction based:
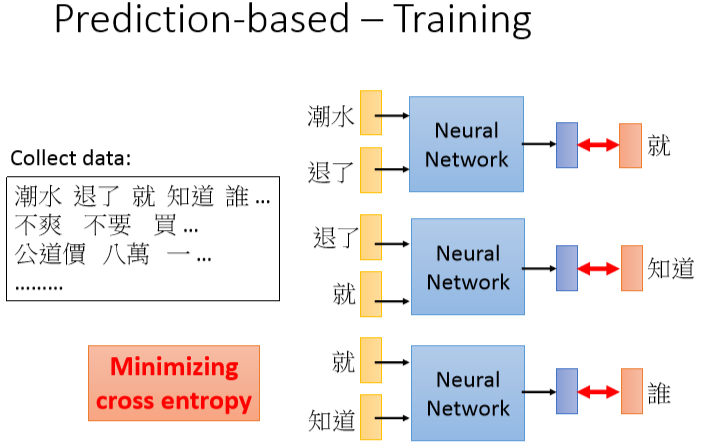 这种推词可以用在language modeling
这种推词可以用在language modeling
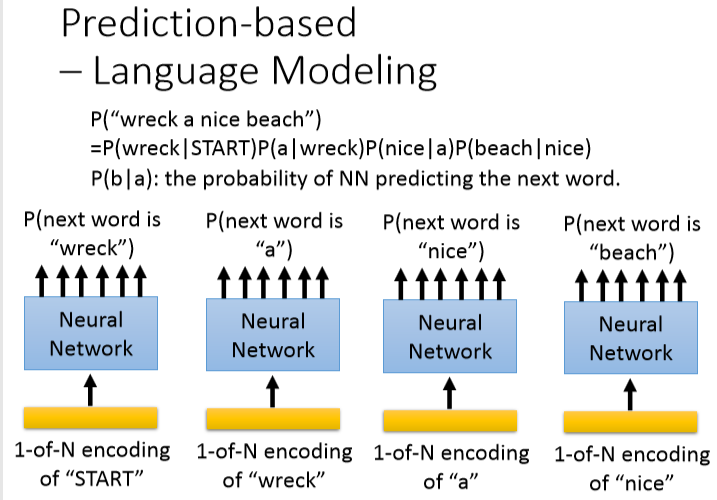
 先把1-of-N encoding通过第一层网络,乘以一个matrix降维
先把1-of-N encoding通过第一层网络,乘以一个matrix降维