

机器学习笔记(五)——多项式回归(sklearn)
本博客仅用于个人学习,不用于传播教学,主要是记自己能够看得懂的笔记(
学习知识、资源和数据来自:机器学习算法基础-覃秉丰_哔哩哔哩_bilibili
利用sklearn处理多项式回归问题非常方便,毕竟sklearn这个东西设计出来就是为了方便的:D。
PolynomialFeatures().fit_transform()的作用是将普通的x数据转变为多项式数据,如将[2]变为[1,2,4,8]。详见上述B站课程。利用特征转变以及多元线性回归,即可完成多项式回归。
数据会放在最底下,可自行保存成csv文件。
Python代码如下:
from sklearn.linear_model import LinearRegression import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import PolynomialFeatures #计算Loss函数 def cal_error(y_data,z): sum=0 for i in range(len(y_data)): sum+=(z[i]-y_data[i])**2 return sum/float(len(y_data))/2.0 data=np.genfromtxt('C:/Users/Lenovo/Desktop/学习/机器学习资料/线性回归以及非线性回归/job.csv',delimiter=',') x_data=data[1:,1,np.newaxis] #构建模型时需要2维以上 y_data=data[1:,2] model=LinearRegression() model.fit(x_data,y_data) #数据输出 z=model.predict(x_data) print(cal_error(y_data,z)) plt.plot(x_data,y_data,'b.') plt.plot(x_data,z,'r') plt.show() #设置特征转换,degree就是转换过后x的最高次幂,也就是用degree次多项式来进行拟合。 ploy=PolynomialFeatures(degree=2) x_ploy=ploy.fit_transform(x_data) #对x_data进行特征处理 model.fit(x_ploy,y_data) #数据输出 z=model.predict(x_ploy) print(cal_error(y_data,z)) plt.plot(x_data,y_data,'b.') plt.plot(x_data,z,'r') plt.show()
得到结果:
error=13347939393.939392
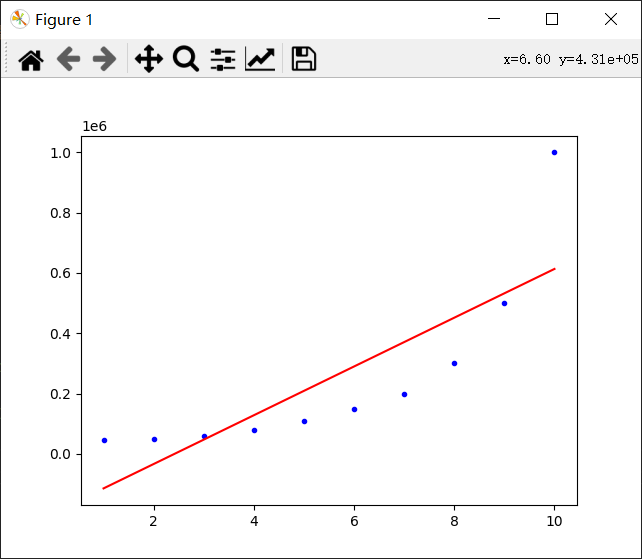
error=3379416666.666669
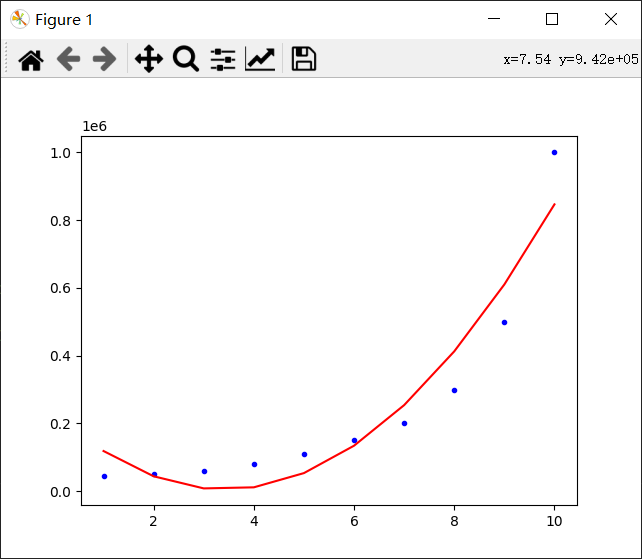
我们还可以修改degree,使拟合效果更好。
比如,degree=3:
error=757831002.3310019
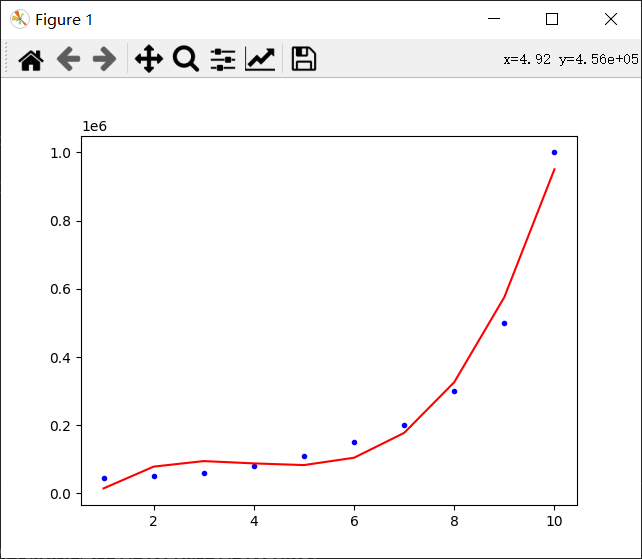
degree=5:
error=8191142.191142735
当然,这只是对于train_data是这样的,对于test_data则可能会出现过拟合状态。
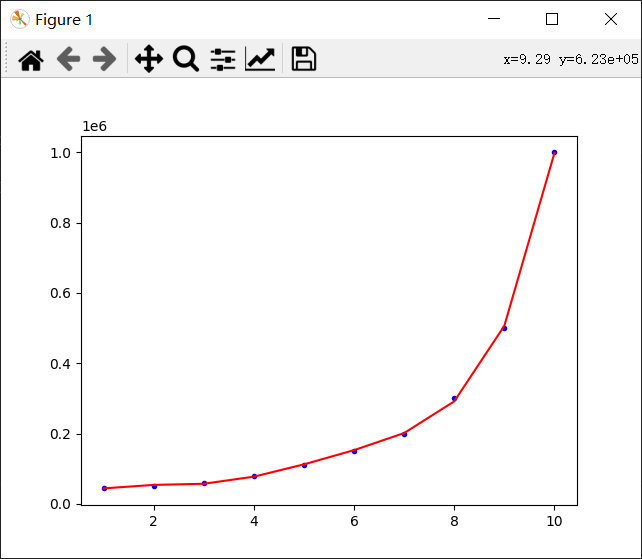
从图中可以看出,作出的曲线并不平滑。这是因为这条曲线只是简单的把十个点连起来了而已。可以多弄几个点,使曲线看上去平滑一些。可以用numpy.linspace()生成点。
修改的最后一部分的代码:
#数据输出 z=model.predict(x_ploy) print('error={0}'.format(cal_error(y_data,z))) plt.plot(x_data,y_data,'b.') x_data=linspace(1,10,100) #1到10之间生成100个点 x_data=x_data.reshape(-1,1) #增加一个维度 x_ploy=ploy.fit_transform(x_data) z=model.predict(x_ploy) plt.plot(x_data,z,'r') plt.show()
得到结果图:
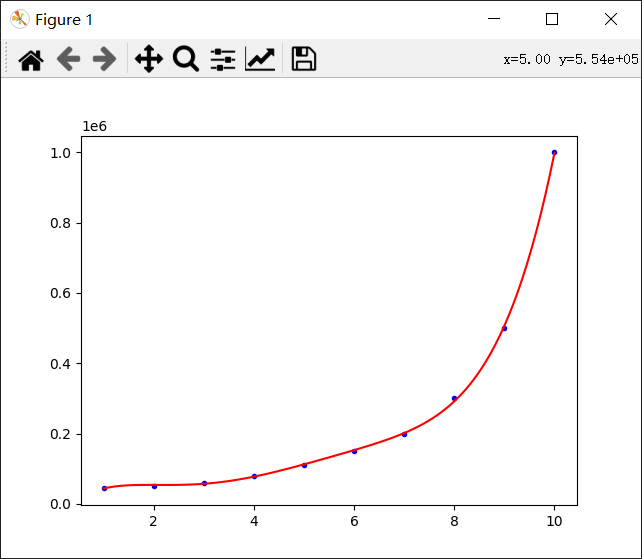
这样就平滑多了。
使用数据:
Position,Level,Salary
Business Analyst,1,45000
Junior Consultant,2,50000
Senior Consultant,3,60000
Manager,4,80000
Country Manager,5,110000
Region Manager,6,150000
Partner,7,200000
Senior Partner,8,300000
C-level,9,500000
CEO,10,1000000

