数据采集第六次作业
作业①:
| 要求 |
- 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
- 每部电影的图片,采用多线程的方法爬取,图片名字为电影名
- 了解正则的使用方法
| 思路 |
(1)ol下的每个li元素对应着每个电影,再通过find li下的元素来获取信息
(2)主演、导演以及评价人数等的爬取需要用到正则式去匹配
(3)用多线程去下载图片到指定路径
(4)信息太长了输出到终端会太乱,所以选择爬取到数据库中
| 代码 |
import urllib.request
from bs4 import BeautifulSoup
import re
import pymysql
import threading
import os
def gethtml(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"}
req=urllib.request.Request(url=url,headers=headers)
html=urllib.request.urlopen(req)
return html
def printdata(html,count):
soup = BeautifulSoup(html, "html.parser")
ol = soup.find('ol', attrs={'class': 'grid_view'})
li=ol.find_all('li')
urls=[]
for li in li:
rank = li.find('em').text.strip() # 排名
name=li.find(name="span",attrs={"class":"title"}).text.strip() #电影名称
p =li.find('p', attrs={'class':''}).text.strip().split("\n")
director=p[0].split('\xa0')[0].split(':')[1].strip()
try:
actor=re.search(r'主演:.*',p[0].strip()).group().replace('主演:','')
except:
actor='null'
time=p[1].split('/')[0].strip()
country=p[1].split('/')[1].strip()
style=p[1].split('/')[2].strip()
score=li.find('span',attrs={"class":"rating_num","property":"v:average"}).text.strip()
number=re.search(r'[\d]+人评价',li.find('div',attrs={"class":"star"}).text).group()[:-3].strip()
try:
quote=li.find(name="span",attrs={"class":"inq"}).text.strip()
except:
quote='null'
img1=li.find('div',attrs={"class":"pic"})
url=img1.find('img').get("src")
if url not in urls:
urls.append(url) # 没有这一步就会有重复的
count = count + 1
T = threading.Thread(target=download, args=(url, name)) # 实例化线程,函数为download,传入参数为url和count
T.setDaemon(False) # 设为前台线程
T.start() # 启动线程
threads.append(T)
imgfile=name+'.jpg'
#print("{:^4}\t{:^30}\t{:^30}\t{:^30}\t{:^5}\t{:^25}\t{:^25}\t{:^20}\t{:^10}\t{:^30}\t{:^10}".format(rank,name,director[0:25],actor[0:20],time,country,style,score,number,quote,imgfile))
cursor.execute(
"insert into movies(排名,名称,导演,主演,上映时间,国家,电影类型,评分,评价人数,引用,文件路径) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(rank,name,director,actor,time,country,style,score,number,quote,imgfile))
def download(url,name):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"}
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("someimages\\"+name+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+name+ext)
except Exception as err:
print(err)
if __name__ == '__main__':
con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="root", db="db", charset="utf8")
cursor = con.cursor(pymysql.cursors.DictCursor)
cursor.execute("drop table movies")
sql = "create table movies(排名 int(20) primary key, 名称 varchar(20), 导演 varchar(256), 主演 varchar(256), 上映时间 varchar(64), 国家 varchar(256),电影类型 varchar(64),评分 varchar(64),评价人数 varchar(64),引用 varchar(64) ,文件路径 varchar(64))"
cursor.execute(sql)
print("{:^4}\t{:^30}\t{:^30}\t{:^30}\t{:^5}\t{:^25}\t{:^25}\t{:^20}\t{:^10}\t{:^30}\t{:^10}".format('排名','名称','导演','主演','上映时间','国家','电影类型','评分','评价人数','引用','文件路径'))
count=0
threads = []
os.mkdir('someimages')
for i in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i)
gethtml(url)
html=gethtml(url)
printdata(html,count)
#关闭数据库连接
con.commit()
con.close()
for t in threads:
t.join() # 阻塞主线程
| 运行结果 |
多线程下载图片:
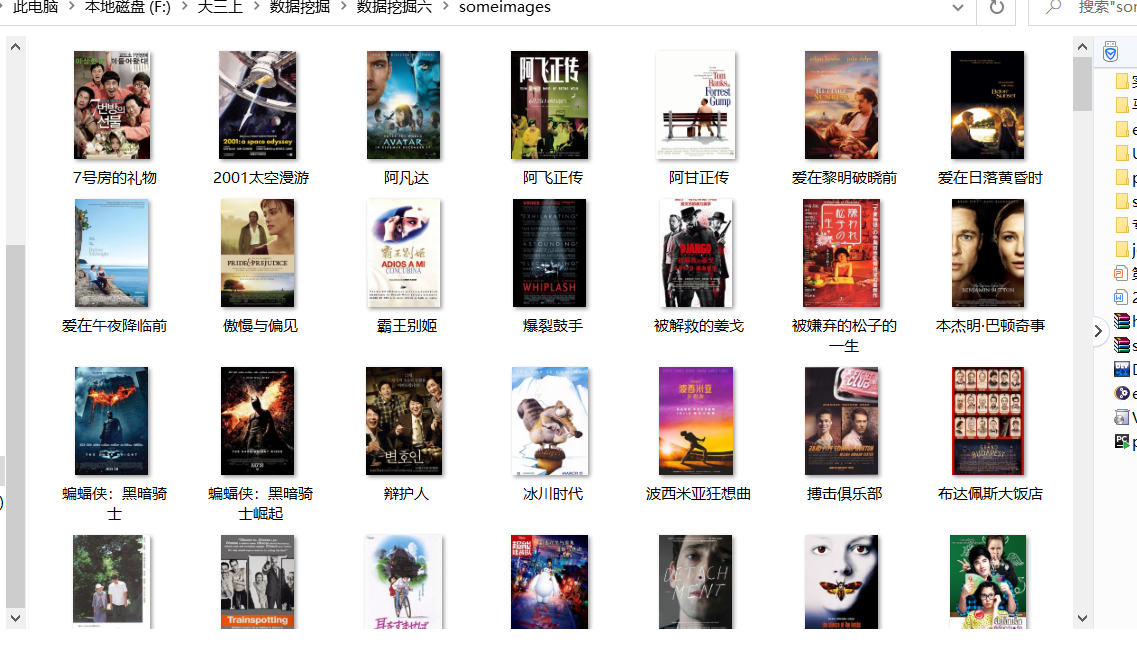
数据:
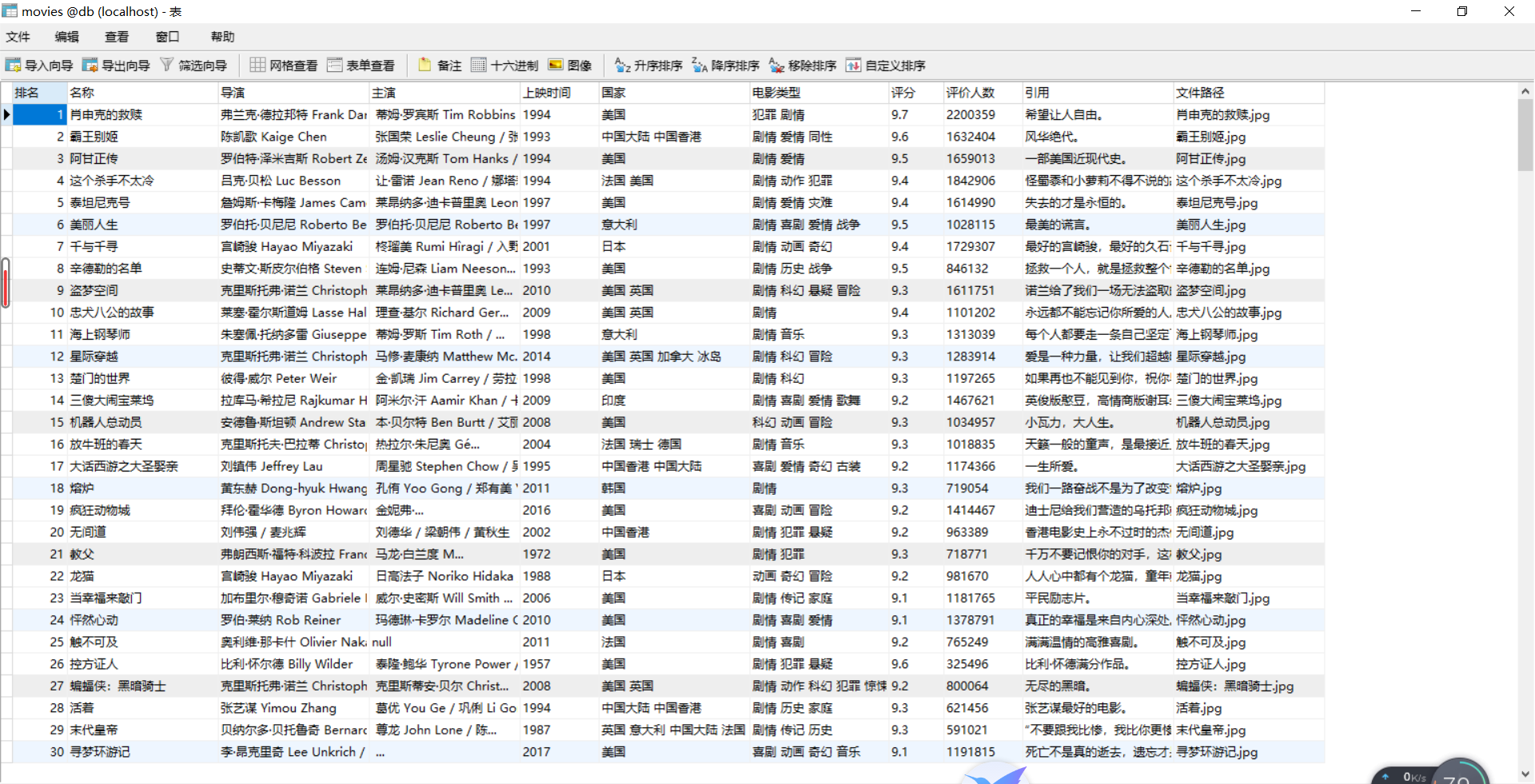
| 心得体会 |
(1)复习了BeautifulSoup的语法,以及正则表达式匹配。记录一下忘记的一些方法:.group() .text() .get() re.search() re.match()
(2)复习了多线程下载图片,以及数据库的使用
(3)爬豆瓣网很容易被封ip,有几次运行频率过快直接就不能爬了,所以要保持一个较慢的频率或者多切换User-Agent。
作业②
| 要求 |
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
- 爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
| 思路 |
(1)学校排名的这个网站之前用beautifulsoup爬取过,所以改一下语法用xpath就很容易爬到名称,排名和城市
(2)重点在获取学校的详细链接,并进入爬取。这种多级页面的爬取,就要用到meta来传递item。
(3)爬取之后还是同样的写入数据库
| 代码 |
myspider
import scrapy
from college.items import CollegeItem
class MySpider(scrapy.Spider):
name = 'mySpider'
allowed_domains = ['www.shanghairanking.cn']
start_urls = ['https://www.shanghairanking.cn/rankings/bcur/2020']
def parse(self, response):
trr=response.xpath("//table[@class='rk-table']//tr")
for tr in trr[1:]:
item = CollegeItem()
Sno = tr.xpath("./td[1]/text()").extract_first()
schoolName = tr.xpath("./td[2]/a/text()").extract_first()
city = tr.xpath("./td/text()")[3].extract()
url = tr.xpath("./td[2]/a/@href").extract_first()
item["Sno"] = Sno.strip()
item["schoolName"] = schoolName.strip()
item["city"] = city.strip()
next_url ='https://www.shanghairanking.cn'+url
yield scrapy.Request(url=next_url, callback=self.parse_detail, meta ={'item':item})
def parse_detail(self, response):
item = response.meta['item']# 这里实例化的是meta的,是parse函数传递过来的第二层内容
officeUrl = response.xpath('//div[@class="univ-website"]/a/@href').extract_first()
info=response.xpath('//div[@class="univ-introduce"]/p/text()').extract_first()
mFile = response.xpath('//td[@class="univ-logo"]/img/@src').extract_first()
item["officeUrl"] = officeUrl.strip()
item["info"] = info.strip()
item["mFile"] = mFile.strip()
yield item
items
import scrapy
class CollegeItem(scrapy.Item):
Sno=scrapy.Field()
schoolName=scrapy.Field()
city=scrapy.Field()
officeUrl=scrapy.Field()
info=scrapy.Field()
mFile=scrapy.Field()
pipelines
import urllib.request
import pymysql
class CollegePipeline:
count = 0
urls = []
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="root", db="db", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("drop table college")
sql="create table college(Sno int(20) primary key, schoolName varchar(20), city varchar(20), officeUrl varchar(64), info varchar(1024), mFile varchar(256))"
self.cursor.execute(sql)
self.opened = True
self.count = 0
print("{0:7}\t{1:^16}\t{2:^8}\t{3:^4}\t{4:^32}\t{5:^20}".format("Sno", "schoolName", "city", "officeUrl", "info", "mFile"))
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条信息")
def process_item(self, item, spider):
try:
#下载图片
try:
url=item["mFile"]
if url not in self.urls: # 去重
self.count += 1 # 图片名
self.urls.append(url)
req = urllib.request.Request(url)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("E:\images\\" + str(self.count) + '.png', "wb")
fobj.write(data)
fobj.close()
item["mFile"]='E:\images\\'+str(self.count)+'.png'
except Exception as err:
print(err)
print("{0:7}\t{1:^16}\t{2:^8}\t{3:^4}\t{4:^16}\t{5:^20}".format(item["Sno"], item["schoolName"],
item["city"], item["officeUrl"], item["info"],
item["mFile"],chr(12288)))
if self.opened:
self.cursor.execute(
"insert into college(Sno, schoolName, city, officeUrl, info, mFile) values(%s,%s,%s,%s,%s,%s)",
(
item["Sno"], item["schoolName"], item["city"], item["officeUrl"], item["info"], item["mFile"]))
self.count += 1
except Exception as err:
print(err)
return item
settings
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.8 Safari/537.36}"
}
ITEM_PIPELINES = {
'college.pipelines.CollegePipeline': 300,
}
| 运行结果 |


| 心得体会 |
(1)一开始 yield scrapy.Request(url=next_url, callback=self.parse_detail, meta ={'item':item})这一句总是无法实现,原因是allowed_domains设置的问题,改为allowed_domains = ['www.shanghairanking.cn']后就成功了
(2)这次新学习了用scrapy进行多级url爬取, 通过meta ={'item':item}就可以传递item,用 item = response.meta['item']接收。
(3)巩固了数据库,复习了xpath语法和scrapy框架。
作业③:
| 要求 |
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
- 使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
- 其中模拟登录账号环节需要录制gif图。
| 思路 |
(1)登录要进行一个iframe的切换,然后send进去账户信息
(2)这次爬取的是已学的课程,所以点开课程后还要再点一下才能跳转到获取信息的那个界面。看了一下url后发现可以直接修改url,就是将url中的'learn'替换为'course',并用re匹配'?tid'之前的链接,就不用再次点击了。
| 代码 |
import pymysql
from selenium import webdriver
import re,time
class db():
#初始化建立连接,建表
def __init__(self):
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="root", db="db", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("drop table course_data")
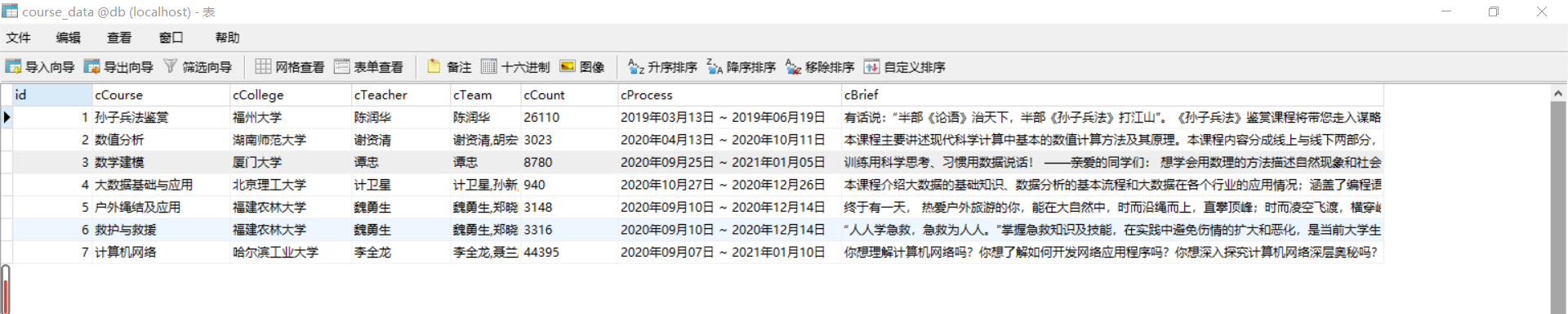
sql="CREATE TABLE course_data(id int(10) PRIMARY KEY AUTO_INCREMENT,cCourse varchar(30), cCollege varchar(30), cTeacher varchar(30), cTeam varchar(30), cCount varchar(30), cProcess varchar(30), cBrief varchar(256))engine=MyISAM;"
self.cursor.execute(sql)
#插入数据
def insert_db(self,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief):
try:
sql = "INSERT INTO course_data(cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) VALUES('%s','%s','%s','%s','%s','%s','%s')" % (pymysql.escape_string(cCourse),cCollege,cTeacher,cTeam,cCount,cProcess,pymysql.escape_string(cBrief))
return self.cursor.execute(sql)
except Exception as e:
print('插入信息出错:{}'.format(e))
return 0
#关闭连接
def __del__(self):
self.cursor.close() #先关闭游标对象
self.con.close() #关闭连接
class mooc():
def __init__(self):
self.option = webdriver.ChromeOptions()
self.option.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"')
self.driver = webdriver.Chrome(options=self.option)
self.driver.implicitly_wait(3)
self.mysql = db()
#登录以及爬取url存入一个列表
def login_and_spider(self):
username = "15235388522@163.com"
password = "***************"
self.driver.get('https://www.icourse163.org/member/login.htm#/webLoginIndex')
self.driver.maximize_window()
self.driver.find_element_by_xpath('//a[@class="f-f0 navLoginBtn"]').click()
self.driver.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]').click()
# 切换iframe
element = self.driver.find_element_by_xpath('/html/body/div[4]/div[2]/div/div/div/div/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[1]/iframe')
self.driver.switch_to.frame(element)
# 登陆邮箱
self.driver.find_element_by_name("email").send_keys(username)
self.driver.find_element_by_name("password").send_keys(password)
time.sleep(2)
#点击登录
self.driver.find_element_by_xpath('//*[@id="dologin"]').click()
time.sleep(3)
self.driver.get(self.driver.current_url)
self.url_list = []
self.driver.find_element_by_xpath('//div[@class="ga-click u-navLogin-myCourse u-navLogin-center-container"]').click()
time.sleep(2)
list = self.driver.find_elements_by_xpath('//div[@class="course-card-wrapper"]/div[@class="box"]/a') #该页面上所有的课程
for item in list: #获取所有课程url
url1=str(item.get_attribute('href'))
url=re.findall(r"(.+)\?",url1)[0].replace('learn','course') #用正则匹配得到课程的新的url,相当于再点击。
self.url_list.append(url)
print(url)
time.sleep(3)
#通过上一个函数的列表,进行一个一个爬取。
def FetchData(self):
for url in self.url_list:
self.driver.get(url)
cCourse = self.driver.find_element_by_xpath('//*[@id="g-body"]//div/span[@class="course-title f-ib f-vam"]').text
cProcess = self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[1]/div[2]/div[1]/span[2]').text
cCount = self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[2]/div[1]/span').text
pattern = re.compile("已有 (.*?) 人参加")
cCount = pattern.findall(cCount)[0]
cCollege = self.driver.find_element_by_xpath('//img[@class="u-img"]').get_attribute('alt')
cTeam = ""
cTeacher = self.driver.find_element_by_xpath('//div[@class="um-list-slider_con"]//div//img').get_attribute('alt')
teacher_list = self.driver.find_elements_by_xpath('//div[@class="um-list-slider_con"]//div//img')
for index,item in enumerate(teacher_list):
if index != 0:
cTeam += "," + item.get_attribute('alt')
else:
cTeam += item.get_attribute('alt')
cBrief = self.driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text
print("{:20}\t{:20}\t{:15}\t{:15}\t{:5}\t{:20}\t{:30}".format(cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief))
self.mysql.insert_db(cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief)
if __name__ == '__main__':
mc = mooc()
mc.login_and_spider()
mc.FetchData()
| 运行结果 |
登录动图:

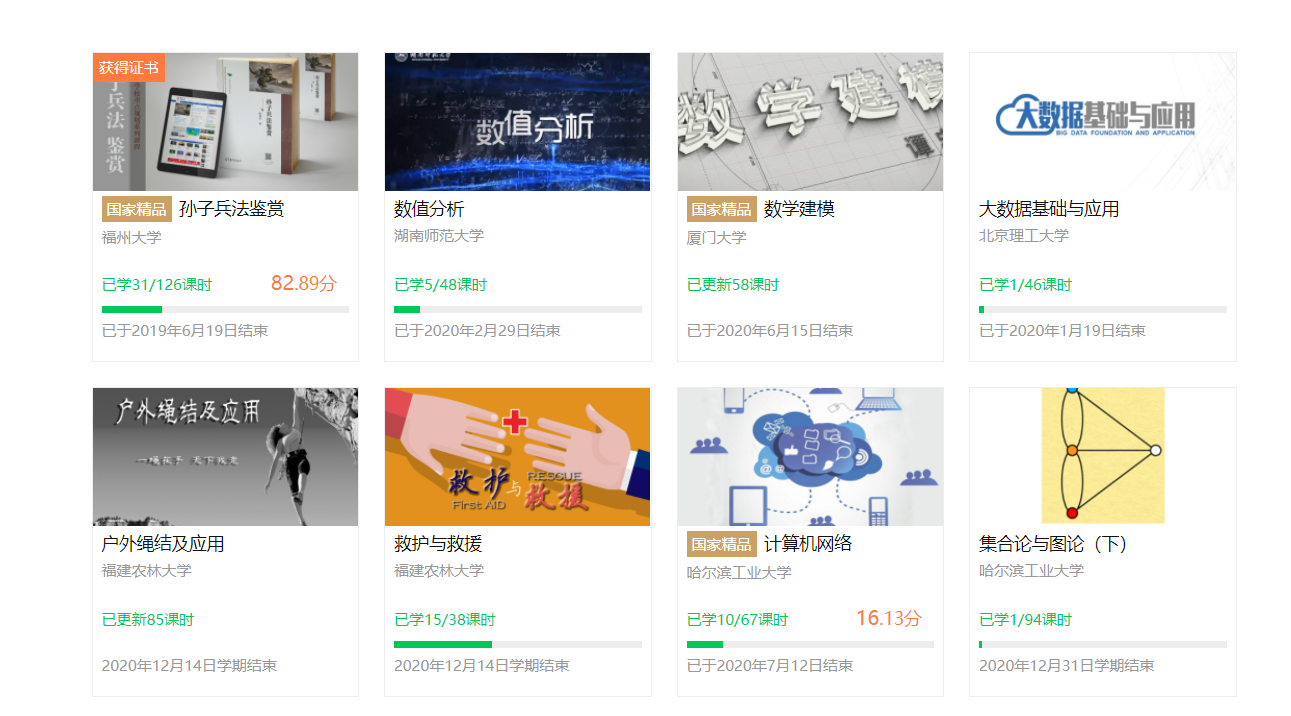
| 心得体会 |
(1)本来写好的代码突然不能用了,困惑了挺久,原来是谷歌浏览器自己升级了导致驱动不能用了,于是下了新的驱动,关了自动更新才继续。
(2)对selenium还是不够熟练,有时候一个小细节就要花挺长时间的。
最终总结:
这次实验就是最后一次作业了,实验内容算是对之前学过知识的一个汇总。beautifulsoup,re正则匹配,scrapy框架,多线程,selenium自动化框架……现在回想起来学了这么多东西。之前觉得写博客好麻烦,但这次忘记了好多之前的语法,去翻自己写过的博客的时候才发现:写博客真的是一个好习惯,能让人快速回忆起很多知识。在上这门课之前,觉得别人短短几行代码就能爬取很多东西很神奇,现在自己也能很熟练地去爬取各种信息了。收获颇多,感谢老师。
