数据采集第五次作业
作业①:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
| 代码 |
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import pymysql
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
# # Initializing Chrome browser
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
self.threads = []
self.No = 0
self.imgNo = 0
self.page=0
#建立与mysql连接,建表
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="root", db="db", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from phones")
try:# 建立新的表
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
#新建文件夹保存图片
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
#关闭连接
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
#插入数据
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(mNo,mMark,mPrice,mNote,mFile))
except Exception as err:
print(err)
#将mysql中数据输出到终端
def showDB(self):
try:
con = pymysql.connect(host="localhost", port=3306, user="root", passwd="root", db="db", charset="utf8")
cursor = con.cursor()
print("{:2}\t\t{:12}\t{:8}\t{:12}\t{:56}".format("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("{:2}\t{:12}\t{:8}\t{:12}\t{:56}".format(row[0], row[1], row[2], row[3], row[4]))
con.close()
except Exception as err:
print(err)
#下载图片
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
#爬取数据
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("京品手机\n", "") #将“京品手机”标签去掉
mark = mark.replace(",", "")
note = note.replace("京品手机\n", "") #将“京品手机”标签去掉
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
#爬取两页
if self.page<2:
self.page+=1
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
nextPage.click()
self.processSpider()
#try:
#self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
#except:
#nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
#time.sleep(10)
#nextPage.click()
#self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
| 运行结果 |
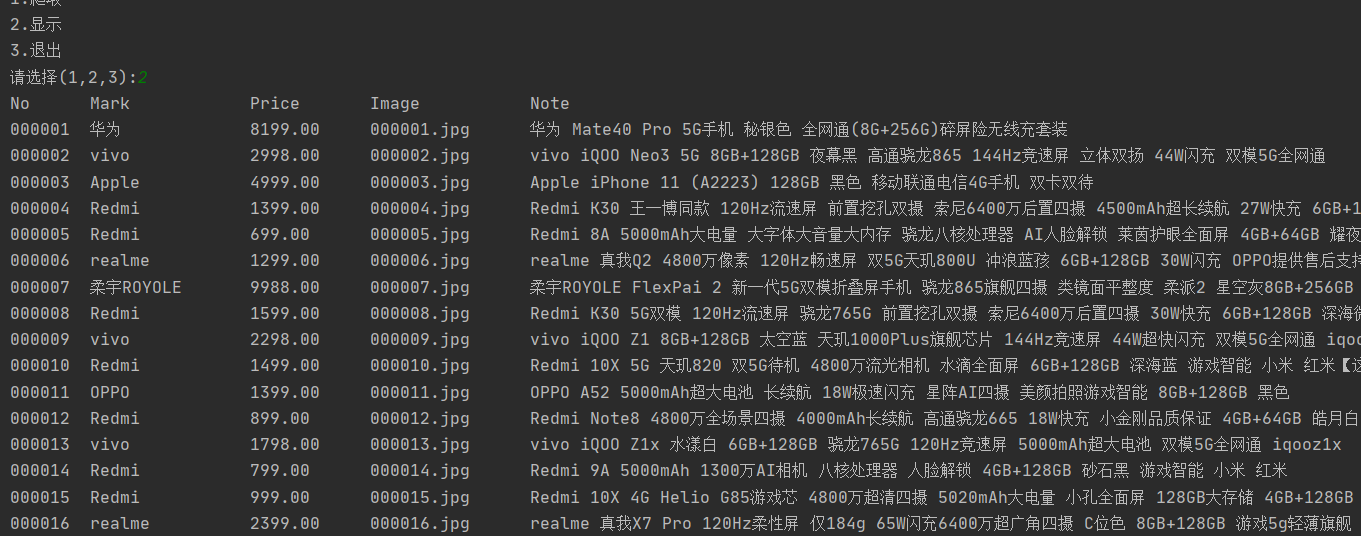
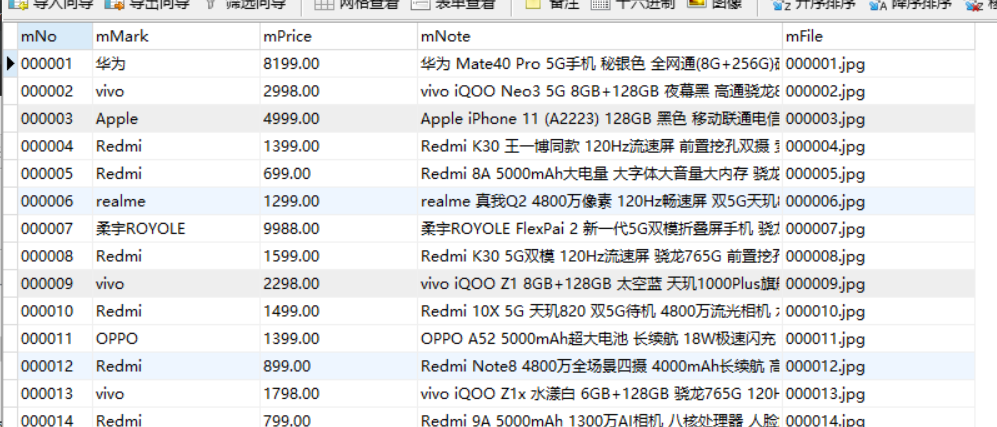

| 心得体会 |
(1)修改成了mysql,爬取前几页
(2)京东手机会挡后面的品牌,要把这个标签去掉

作业②
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
| 代码 |
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import datetime
import time
class MySpider:
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def startUp(self, url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
self.driver = webdriver.Chrome(options=chrome_options)
self.page = 0 # 爬取页数
self.section=["nav_hs_a_board","nav_sh_a_board","nav_sz_a_board"] #要点击的板块的属性
self.sectionid=0; #第一个板块
self.driver.get(url)
#建立与mysql连接,建三个表来保存三个板块的数据
try:
print("connecting to mysql")
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="root", db="db", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("DROP TABLE IF EXISTS nav_hs_a_board")
self.cursor.execute("DROP TABLE IF EXISTS nav_sh_a_board")
self.cursor.execute("DROP TABLE IF EXISTS nav_sz_a_board")
except:
pass
try:
# 建立新的表
sql1 = "CREATE TABLE nav_hs_a_board(id INT(4) PRIMARY KEY, StockNo VARCHAR(16), StockName VARCHAR(32), StockQuote VARCHAR(32), Changerate VARCHAR(32), Chg VARCHAR(32), Volume VARCHAR(32), Turnover VARCHAR(32), StockAmplitude VARCHAR(32), Highest VARCHAR(32), Lowest VARCHAR(32), Pricetoday VARCHAR(32), PrevClose VARCHAR(32))"
self.cursor.execute(sql1)
sql2 = "CREATE TABLE nav_sh_a_board(id INT(4) PRIMARY KEY, StockNo VARCHAR(16), StockName VARCHAR(32), StockQuote VARCHAR(32), Changerate VARCHAR(32), Chg VARCHAR(32), Volume VARCHAR(32), Turnover VARCHAR(32), StockAmplitude VARCHAR(32), Highest VARCHAR(32), Lowest VARCHAR(32), Pricetoday VARCHAR(32), PrevClose VARCHAR(32))"
sql3 = "CREATE TABLE nav_sz_a_board(id INT(4) PRIMARY KEY, StockNo VARCHAR(16), StockName VARCHAR(32), StockQuote VARCHAR(32), Changerate VARCHAR(32), Chg VARCHAR(32), Volume VARCHAR(32), Turnover VARCHAR(32), StockAmplitude VARCHAR(32), Highest VARCHAR(32), Lowest VARCHAR(32), Pricetoday VARCHAR(32), PrevClose VARCHAR(32))"
self.cursor.execute(sql2)
self.cursor.execute(sql3)
except Exception as err:
print(err)
except Exception as err :
print(err)
def showDB(self,section):
try:
print("{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:12}\t{:12}\t{:8}\t{:8}\t{:8}\t{:8}".format("id", "StockNo","StockName","StockQuote","Changerate","Chg", "Volume","Turnover", "StockAmplitude","highest","lowesr","Pricetoday","PrevClose"))
con = pymysql.connect(host="localhost", port=3306, user="root", passwd="root", db="db", charset="utf8")
cursor = con.cursor()
cursor.execute("SELECT * FROM "+section)
items = cursor.fetchall()
for item in items:
print("{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:12}\t{:12}\t{:8}\t{:8}\t{:8}\t{:8}".format(
item[0], item[1], item[2], item[3], item[4], item[5],
item[6], item[7],
item[8], item[9], item[10], item[11], item[12]))
self.con.close()
except Exception as err:
print(err)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertDB(self,section,id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose):
try:
sql = "insert into "+section+"(id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose))
except Exception as err:
print(err)
def processSpider(self):
time.sleep(2)
try:
trr = self.driver.find_elements_by_xpath("//table[@id='table_wrapper-table']/tbody/tr")
for tr in trr:
id = tr.find_element_by_xpath(".//td[1]").text
StockNo = tr.find_element_by_xpath("./td[2]/a").text
StockName= tr.find_element_by_xpath("./td[3]/a").text
StockQuote = tr.find_element_by_xpath("./td[5]/span").text
Changerate = tr.find_element_by_xpath("./td[6]/span").text
Chg = tr.find_element_by_xpath("./td[7]/span").text
Volume = tr.find_element_by_xpath("./td[8]").text
Turnover = tr.find_element_by_xpath("./td[9]").text
StockAmplitude = tr.find_element_by_xpath("./td[10]").text
highest = tr.find_element_by_xpath("./td[11]/span").text
lowest = tr.find_element_by_xpath("./td[12]/span").text
Pricetoday = tr.find_element_by_xpath("./td[13]/span").text
PrevClose = tr.find_element_by_xpath("./td[14]").text
section=self.section[self.sectionid]
self.insertDB(section,id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,highest,lowest,Pricetoday,PrevClose)
#爬取前2页
if self.page < 2:
self.page += 1
print("第", self.page, "页已经爬取完成")
nextPage = self.driver.find_element_by_xpath("//div[@class='dataTables_paginate paging_input']/a[2]")
nextPage.click()
time.sleep(10)
self.processSpider()
elif self.sectionid <3:
#爬取下一个板块
print(self.section[self.sectionid]+"爬取完成")
self.sectionid+=1
self.page=0
nextsec=self.driver.find_element_by_xpath("//li[@id='"+self.section[self.sectionid]+"']/a")
self.driver.execute_script("arguments[0].click();", nextsec)
time.sleep(10)
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
spider = MySpider()
url="http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url)
continue
elif s == "2":
print("1.沪深A股")
print("2.上证A股")
print("3.深证A股")
h = input("请选择(1,2,3):")
if h =="1":
spider.showDB("nav_hs_a_board")
elif h == "2":
spider.showDB("nav_sh_a_board")
elif h == "3":
spider.showDB("nav_sz_a_board")
continue
elif s == "3":
break
| 运行结果 |
爬取结果
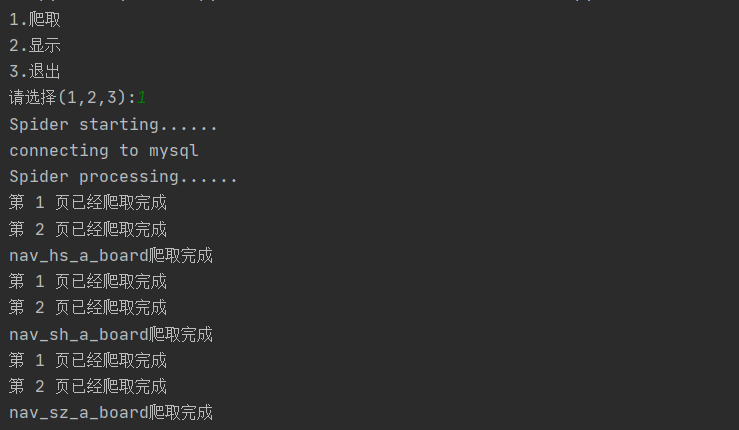
showdb结果

数据库中表:

数据库中某一板块的结果
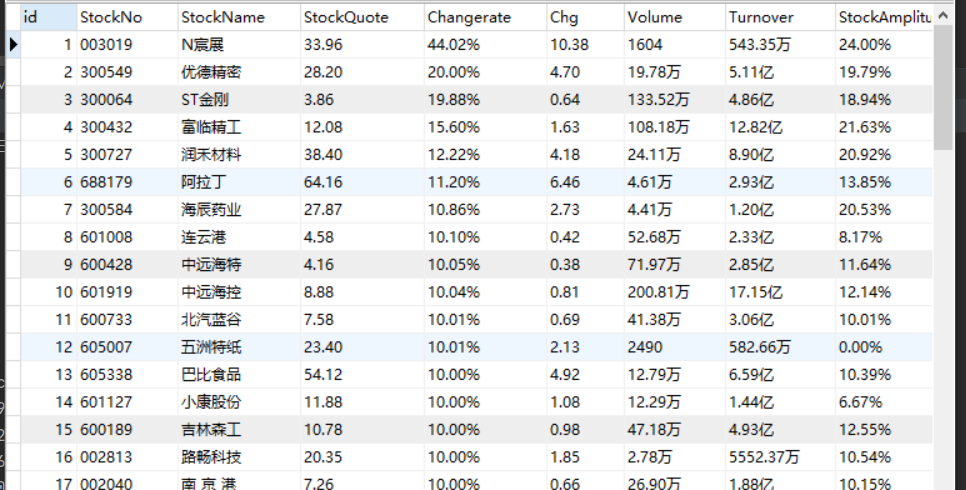
| 心得体会 |
(1)click时有遇到这个错误

解决方法:
如:driver.execute_script("arguments[0].click();", element)
(2)与第一题基本类似,多加了一个爬取不同板块到不同表中,对selenium框架熟练了
作业③:
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
| 代码 |
import pymysql
from selenium import webdriver
import re,time
from selenium.webdriver.chrome.options import Options
# https://www.icourse163.org/
class db():
def __init__(self):
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="root", db="db", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
def insert_db(self,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief):
try:
sql = "INSERT INTO course_data(cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) VALUES('%s','%s','%s','%s','%s','%s','%s');" % (pymysql.escape_string(cCourse),cCollege,cTeacher,cTeam,cCount,cProcess,pymysql.escape_string(cBrief))
return self.cursor.execute(sql)
except Exception as e:
print('插入信息出错:{}'.format(e))
return 0
def __del__(self):
self.cursor.close() #先关闭游标对象
self.con.close() #关闭连接
class mooc():
def __init__(self):
self.option = webdriver.ChromeOptions()
self.option.add_argument('headless')
self.option.add_argument('--disable-gpu')
self.option.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"')
self.driver = webdriver.Chrome(options=self.option)
self.driver.implicitly_wait(3)
self.mysql = db()
def search_content(self):
self.url_list = []
course = input("请输入要搜索的课程:")
self.driver.get('https://www.icourse163.org/search.htm?search='+course+'#/')
#爬取前2页的课程链接
for item in range(2):
list = self.driver.find_elements_by_xpath('//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]') #该页面上所有的课程
for item in list: #获取所有课程url
self.url_list.append('https://www.icourse163.org' + item.get_attribute('data-href'))
self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]/a').click() #点击下一页
time.sleep(3)
#登录
def login(self):
username = '1085491098@qq.com'
password = ''
self.driver.get('https://www.icourse163.org/member/login.htm#/webLoginIndex')
self.driver.find_element_by_xpath('//*[@class="f-f0 navLoginBtn"]').click()
self.driver.find_element_by_xpath('//*[@class="ux-login-set-scan-code_ft_back"]').click()
# 切换iframe
element = self.driver.find_element_by_xpath('/html/body/div[4]/div[2]/div/div/div/div/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[1]/iframe')
self.driver.switch_to.frame(element)
# 登陆邮箱
self.driver.find_element_by_name("email").send_keys(username)
self.driver.find_element_by_name("password").send_keys(password)
time.sleep(2)
#点击登录
self.driver.find_element_by_xpath('//*[@id="dologin"]').click()
self.driver.switch_to.default_content()
def FetchData(self):
for url in self.url_list:
self.driver.get(url)
cCourse = self.driver.find_element_by_xpath('//*[@id="g-body"]//div/span[@class="course-title f-ib f-vam"]').text
cProcess = self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[1]/div[2]/div[1]/span[2]').text
cCount = self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[2]/div[1]/span').text
pattern = re.compile("已有 (.*?) 人参加")
cCount = pattern.findall(cCount)[0]
cCollege = self.driver.find_element_by_xpath('//img[@class="u-img"]').get_attribute('alt')
cTeam = ""
cTeacher = self.driver.find_element_by_xpath('//div[@class="um-list-slider_con"]//div//img').get_attribute('alt')
teacher_list = self.driver.find_elements_by_xpath('//div[@class="um-list-slider_con"]//div//img')
for index,item in enumerate(teacher_list):
if index != 0:
cTeam += "," + item.get_attribute('alt')
else:
cTeam += item.get_attribute('alt')
cBrief = self.driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text
print(cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief)
self.mysql.insert_db(cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief)
if __name__ == '__main__':
mc = mooc()
#mc.login()
mc.search_content()
mc.FetchData()
| 运行结果 |

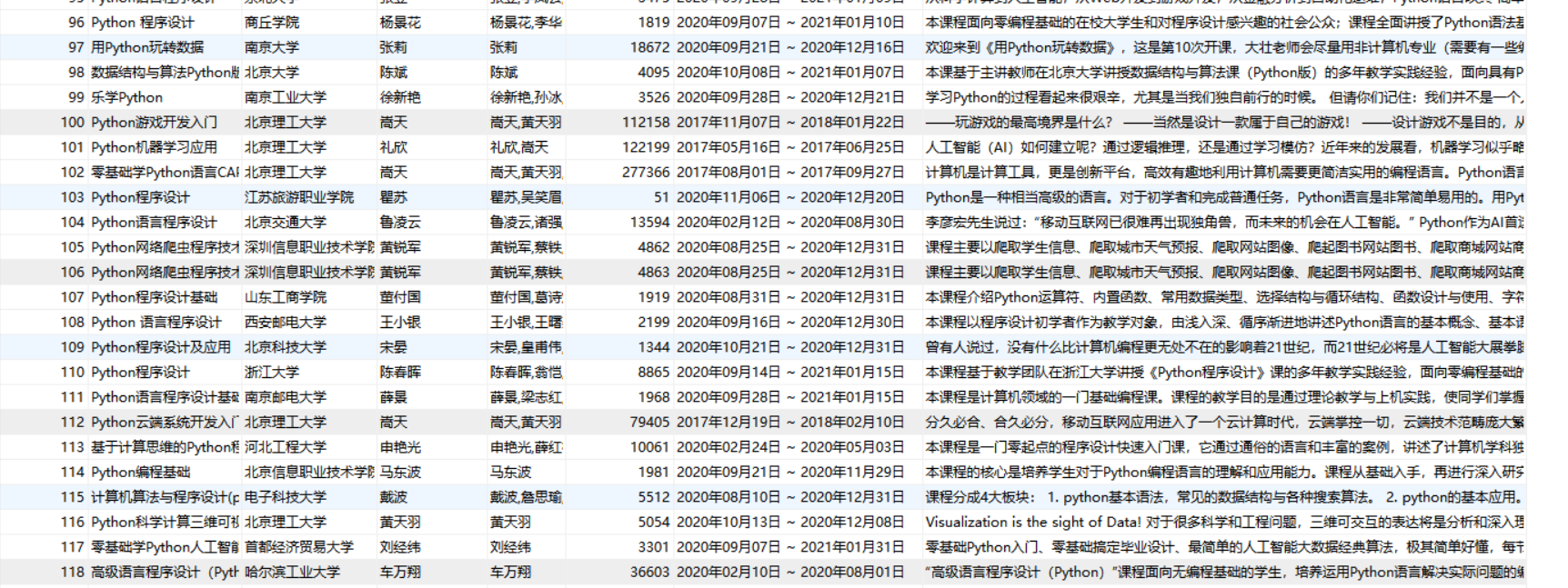
| 心得体会 |
(1)登录时用到了切换iframe
(2)爬取的思路是先将每个课程的url保存下来再爬取相关信息,也可以一个一个点击,不过可能会比较慢。
(3)一开始爬不到数据库中,是数据库表的引擎设置的问题,改成了MyISAM.
(4)熟练了selenium的一些常用定位元素语法
