数据采集与融合第四次作业
作业①:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
| 代码 |
myspider
import scrapy
from dangdang.items import BookItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
key = 'python'
source_url='http://search.dangdang.com/'
def start_requests(self):
url = MySpider.source_url+"?key="+MySpider.key
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
lis=selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title=li.xpath("./a[position()=1]/@title").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
#detail有时没有,结果None
item=BookItem()
item["title"]=title.strip() if title else ""
item["author"]=author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
#最后一页时link为None
#翻页
link=selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link:
url=response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
items
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
pipelines
import pymysql
class BookPipeline(object):
#连接数据库
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="root",db="db",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
#关闭连接
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
#插入表中
if self.opened:
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count+=1
except Exception as err:
print(err)
return item
settings
ITEM_PIPELINES = {
'dangdang.pipelines.BookPipeline': 300,
}
| 运行结果 |
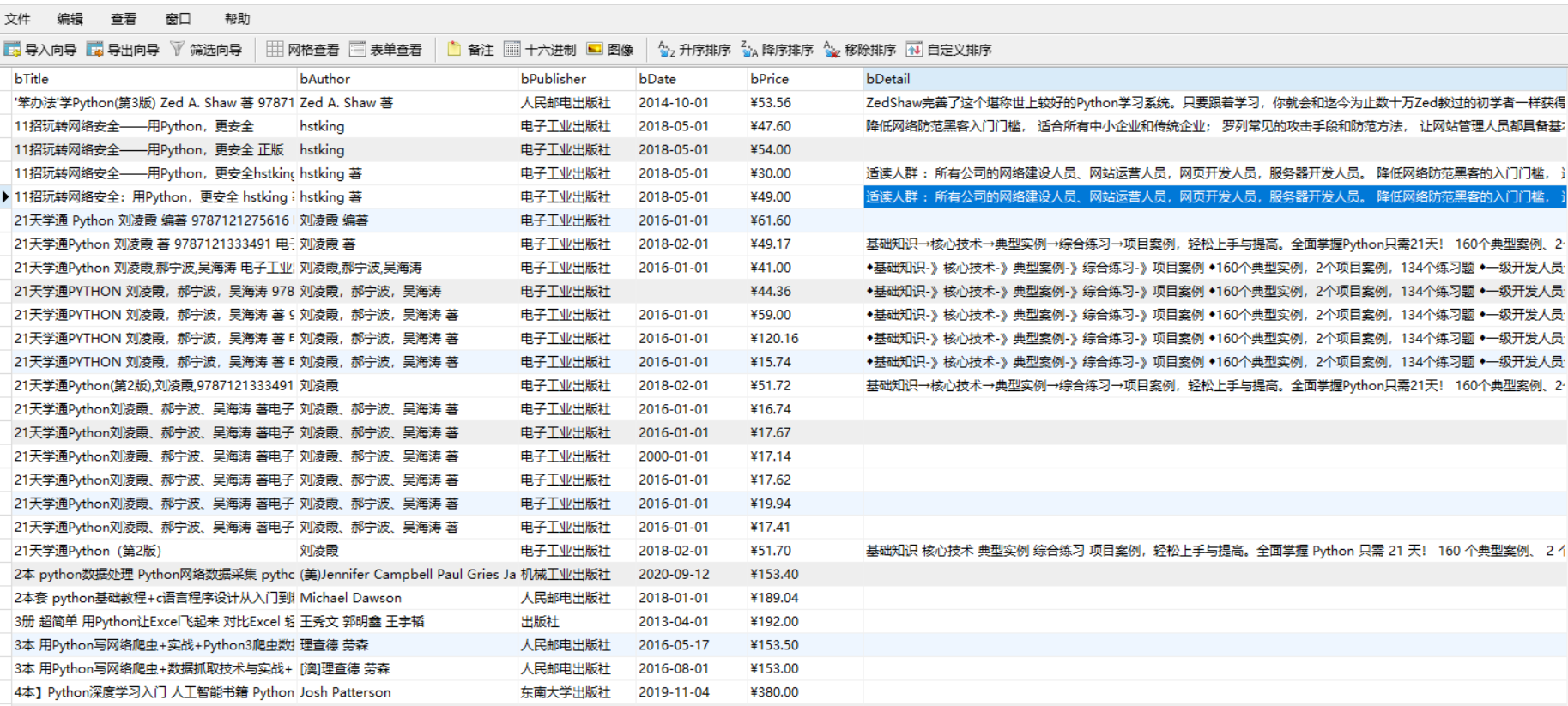
| 心得体会 |
(1)这个实验主要在于mysql的存储和xpath的使用,掌握了如何连接数据库,向表中插入数据
(2)相比来说,xpath像查找文件路径一样,用起来更易懂。
(3)通过这几次实验,对scrapy更加熟悉了。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
| 思路 |
(1)第一种:抓取json,用re正则表达式爬取,存储到数据库中(简单修改之前代码)
只修改上次作业的pipelines如下即可:
import pymysql
class SharesPipeline(object):
def open_spider(self,spider):
print("opened")
print("{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:12}\t{:12}\t{:8}\t{:8}\t{:8}\t{:8}".format("id","StockNo","StockName","StockQuote","Changerate","Chg","Volume","Turnover","StockAmplitude","highest","lowest","Pricetoday","PrevClose"))
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="root",db="db",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"条记录")
def process_item(self, item, spider):
try:
print("{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:12}\t{:12}\t{:8}\t{:8}\t{:8}\t{:8}".format(self.count+1,item["no"],item["name"],item["latest"],item["zdf"],item["zde"],item["cjl"],item["cje"],item["zf"],item["highest"],item["lowest"],item["today"],item["yesterday"]))
if self.opened:
self.cursor.execute(
"insert into stocks (id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(self.count+1,item["no"], item["name"], item["latest"], item["zdf"], item["zde"], item["cjl"], item["cje"],
item["zf"], item["highest"], item["lowest"], item["today"], item["yesterday"]))
self.count += 1
except Exception as err:
print(err)
return item
(2)第二种:用scrapy结合selenium,用xpath爬取(因为要用scrapy还要用xpath)
Ⅰ、用scrapy结合selenium参照了一篇博客[https://www.cnblogs.com/xiao-apple36/p/12635470.html]
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
Ⅱ、xpath爬取

有的数据在td下的a中,有的在td下的span中,有的在td中
| 代码 |
建表
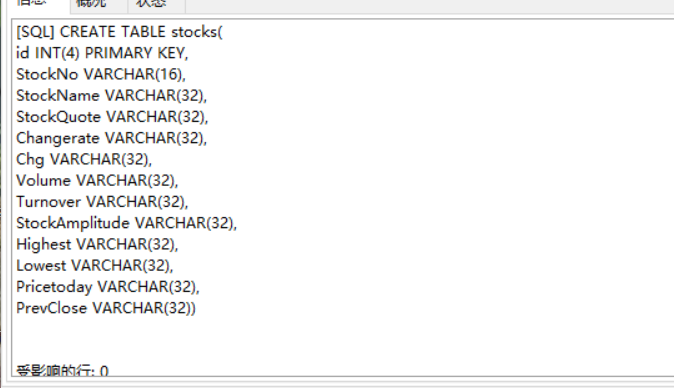
myspider
import scrapy
from shares.items import gupiaoItem
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import UnicodeDammit
chorme_options = Options()
chorme_options.add_argument("--headless") #无头
chorme_options.add_argument("--disable-gpu")
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://quote.eastmoney.com/center/gridlist.html#hs_a_board']
def __init__(self):
self.browser = webdriver.Chrome(chrome_options=chorme_options)
super().__init__()
def start_requests(self):
url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
response = scrapy.Request(url, callback=self.parse)
yield response
def close(self, spider):
self.browser.quit()
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
tdd=selector.xpath("//div[@class='listview full']/table/tbody/tr")
for td in tdd:
id = td.xpath("./td[position()=1]/text()").extract()
Volume = td.xpath("./td[position()=8]/text()").extract()
Turnover = td.xpath("./td[position()=9]/text()").extract()
StockAmplitude = td.xpath("./td[position()=10]/text()").extract()
PrevClose = td.xpath("./td[position()=14]/text()").extract()
no_name = td.xpath("./td/a/text()").extract()
number = td.xpath("./td/span/text()").extract()
item=gupiaoItem()
item["id"] = id[0].strip()
item["StockNo"] = no_name[0].strip()
item["StockName"] = no_name[1].strip()
item["StockQuote"] = number[0].strip()
item["Changerate"] = number[1].strip()
item["Chg"] = number[2].strip()
item["Volume"] =Volume[0].strip()
item["Turnover"] =Turnover[0].strip()
item["StockAmplitude"] =StockAmplitude[0].strip()
item["highest"] = number[3].strip()
item["lowest"] = number[4].strip()
item["Pricetoday"] = number[5].strip()
item["PrevClose"] =PrevClose[0].strip()
yield item
except Exception as err:
print(err)
items
import scrapy
class gupiaoItem(scrapy.Item):
id = scrapy.Field() #序号
StockNo = scrapy.Field() #代码
StockName = scrapy.Field() #名称
StockQuote= scrapy.Field() #最新价
Changerate = scrapy.Field() #涨跌幅
Chg = scrapy.Field() #涨跌额
Volume = scrapy.Field() #成交量
Turnover= scrapy.Field() #成交额
StockAmplitude = scrapy.Field() #振幅
highest = scrapy.Field() #最高
lowest= scrapy.Field() #最低
Pricetoday = scrapy.Field() #今开
PrevClose = scrapy.Field() #昨收
pipelines
import pymysql
class SharesPipeline(object):
def open_spider(self,spider):
print("opened")
print("{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:12}\t{:12}\t{:8}\t{:8}\t{:8}\t{:8}".format("id","StockNo","StockName","StockQuote","Changerate","Chg","Volume","Turnover","StockAmplitude","highest","lowest","Pricetoday","PrevClose"))
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="root",db="db",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"条记录")
def process_item(self, item, spider):
try:
print("{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:12}\t{:12}\t{:8}\t{:8}\t{:8}\t{:8}".format(item["id"],item["StockNo"], item["StockName"], item["StockQuote"], item["Changerate"], item["Chg"], item["Volume"], item["Turnover"],
item["StockAmplitude"], item["highest"], item["lowest"], item["Pricetoday"], item["PrevClose"]))
if self.opened:
self.cursor.execute(
"insert into stocks (id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(item["id"],item["StockNo"], item["StockName"], item["StockQuote"], item["Changerate"], item["Chg"], item["Volume"], item["Turnover"],
item["StockAmplitude"], item["highest"], item["lowest"], item["Pricetoday"], item["PrevClose"]))
self.count += 1
except Exception as err:
print(err)
return item
middlewares修改
from time import sleep
修改class SharesDownloaderMiddleware中的process_response如下
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
#挑选指定的响应对象进行篡改
#通过url指定request
#通过request指定response
#spider爬虫对象
bro = spider.browser # 获取爬虫类定义的浏览器对象
if request.url in spider.start_urls:
#response # 进行篡改 实例化新的响应对象(包含动态加载的新闻数据)替代原来的旧响应对象
# 基于seleium便捷获取动态数据
bro.get(request.url)
sleep(3)
bro.execute_script('window.scrollTo(0, document.body.scrollHeight)')
sleep(1)
page_text = bro.page_source # 包含了动态加载对象
new_response = HtmlResponse(url=request.url,body=page_text,encoding="utf-8",request=request)
return new_response
else:
return response
settings
ROBOTSTXT_OBEY = True #之前爬取json时改为了False,要改回来
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.8 Safari/537.36}"
}
DOWNLOADER_MIDDLEWARES = {
'shares.middlewares.SharesDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'shares.pipelines.SharesPipeline': 300,
}
| 运行结果 |
第一种结果:
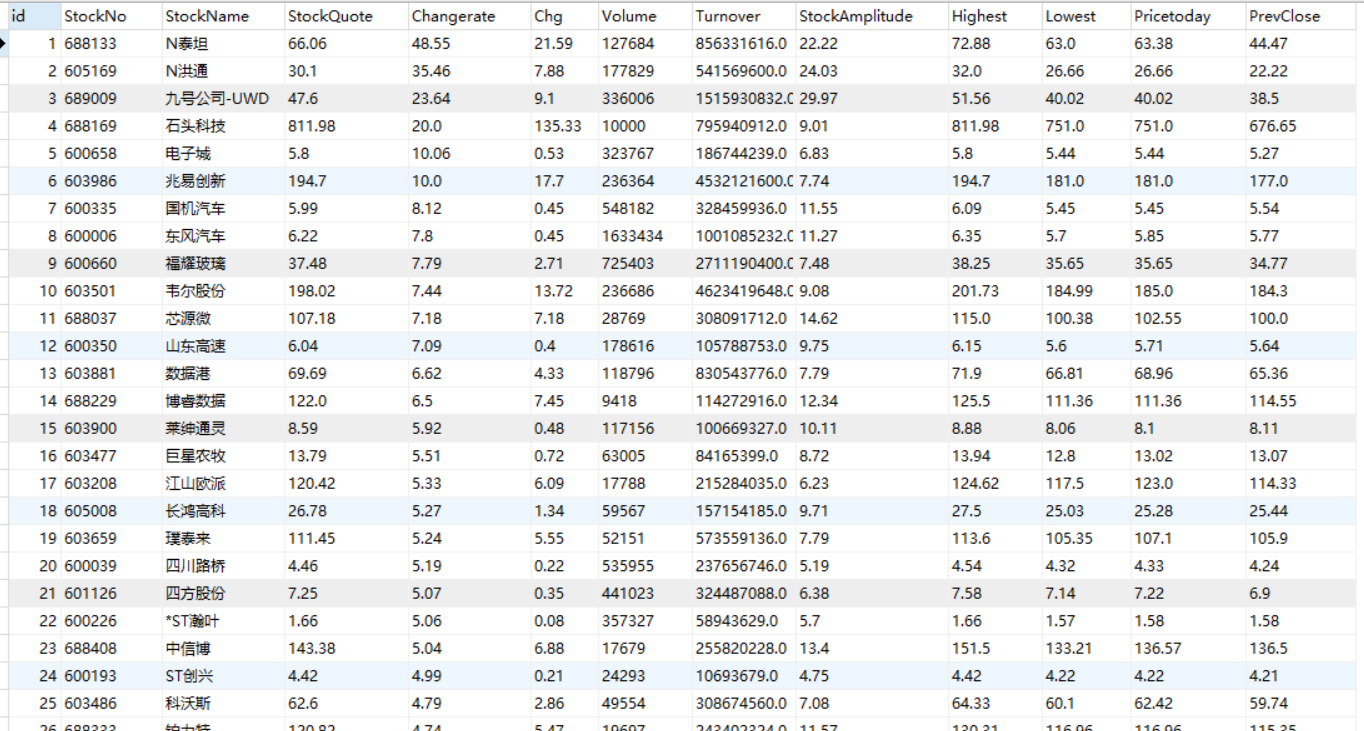
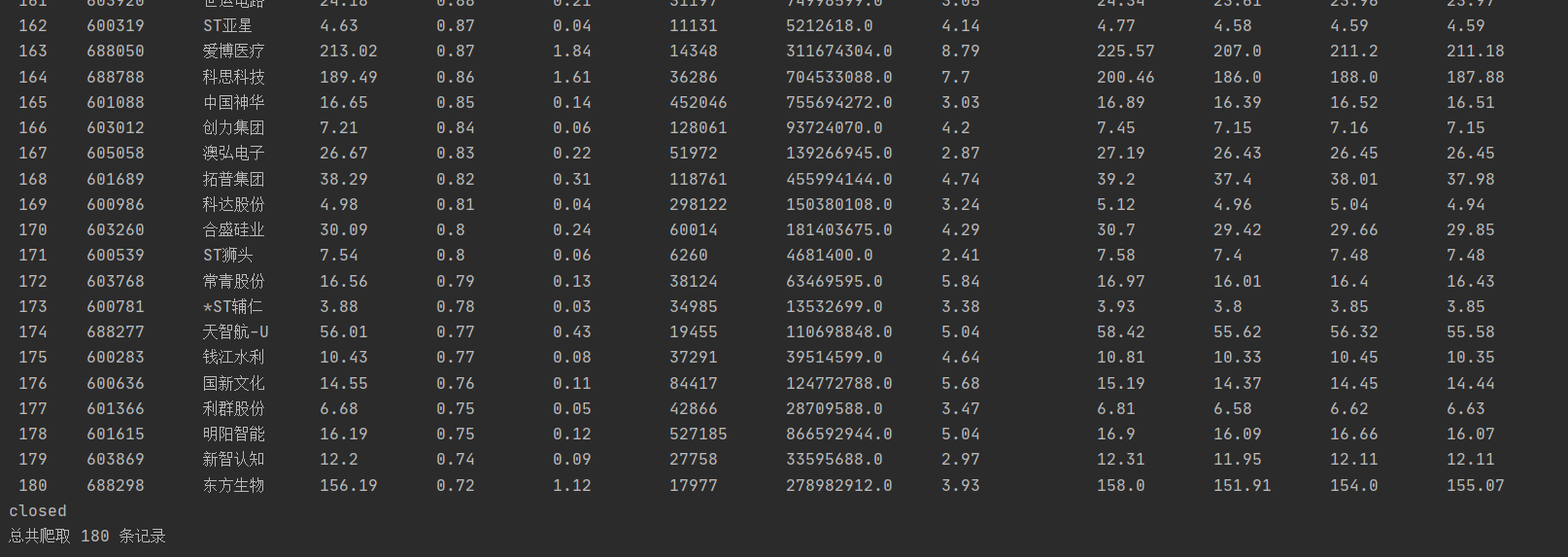
第二种的结果:
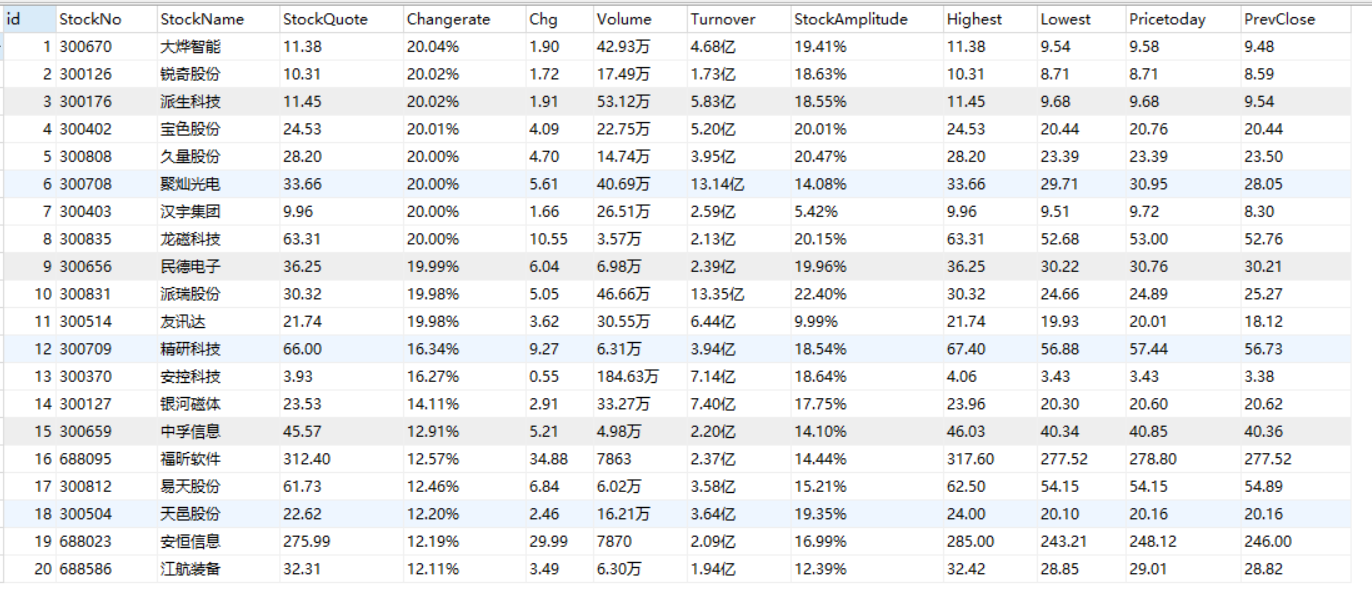
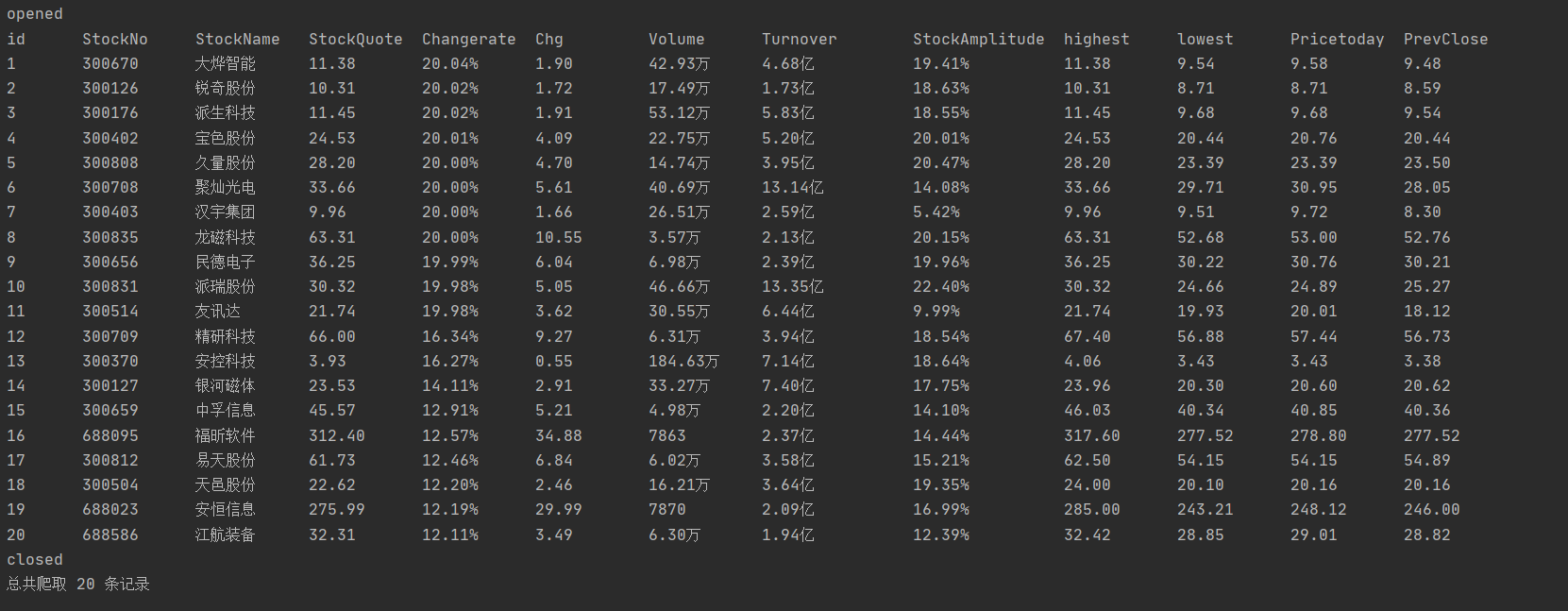
| 心得体会 |
(1)知道了怎么用scrapy结合selenium,要修改中间件,在settings中也要修改相应的值。
(2)对比通过js文件爬取与selenium模拟浏览器:
- 时间上selenium慢了不少
- selenium是实时的数据
- selenium加上xpath比较方便,比用re获取js文件中的值简单。
(3)对于用scrapy结合selenium实现翻页,快截至了没来得及做,之后补上。
(4)数据库建表时id要设为int型,一开始设成varchar,数据库中存储排序按照1,10.....来排序,而不是1,2,3...
(5) 还有就是之前没装谷歌浏览器的驱动,配置环境变量。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
| 思路 |

每条数据在一个tr,第一个是表头,遍历tr下的每个td,就得到数据了,之后就是一样的连接数据库,插入数据。
| 代码 |
建表

myspider
import scrapy
from ICBC.items import IcbcItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
key = 'python'
def start_requests(self):
url = 'http://fx.cmbchina.com/hq/'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
trr = selector.xpath("//table[@class='data']/tr") #去掉了tbody
for tr in trr[1:]:
Currency = tr.xpath("./td[@class='fontbold']/text()").extract_first()
TSP =tr.xpath("./td[@class='numberright']/text()").extract_first()
CSP =tr.xpath("./td[@class='numberright']/text()")[1].extract()
TBP=tr.xpath("./td[@class='numberright']/text()")[2].extract()
CBP=tr.xpath("./td[@class='numberright']/text()")[3].extract()
Time=tr.xpath("./td[@align='center']/text()")[2].extract()
item = IcbcItem()
item["Currency"] = Currency.strip()
item["TSP"] = TSP.strip()
item["CSP"] = CSP.strip()
item["TBP"] = TBP.strip()
item["CBP"] = CBP.strip()
item["Time"] = Time.strip()
yield item
except Exception as err:
print(err)
items
import scrapy
class IcbcItem(scrapy.Item):
# define the fields for your item here like:
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
pipelines
import pymysql
class IcbcPipeline:
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="root",db="db",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from ICBC")
self.opened=True
self.count=0
print("{:2}\t{:7}\t{:8}\t{:4}\t{:4}\t{:4}\t{:20}".format("Id","Currency","TSP","CSP","TBP","CBP","Time"))
except Exception as err:
print(err)
self.opened=False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"条信息")
def process_item(self, item, spider):
try:
print("{:2}\t{:7}\t{:8}\t{:4}\t{:4}\t{:4}\t{:20}".format(self.count+1,item["Currency"],item["TSP"],item["CSP"],item["TBP"] ,item["CBP"],item["Time"]))
if self.opened:
self.cursor.execute(
"insert into ICBC(ID,Currency,TSP,CSP,TBP,CBP,Time) values(%s,%s,%s,%s,%s,%s,%s)",
(self.count+1,item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
self.count += 1
except Exception as err:
print(err)
return item
settings
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.8 Safari/537.36}"
}
ITEM_PIPELINES = {
'ICBC.pipelines.IcbcPipeline': 300,
}
| 运行结果 |
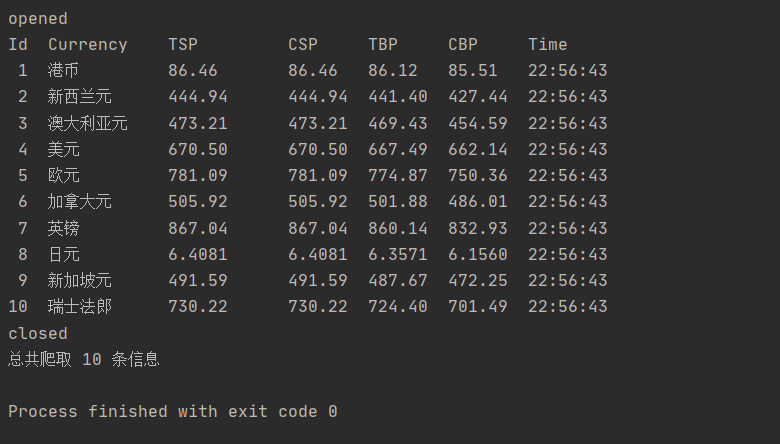
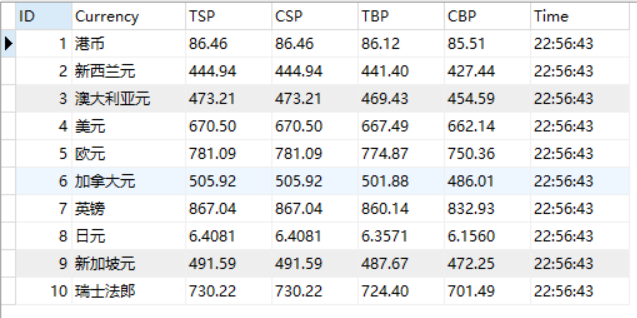
| 心得体会 |
(1)使用scapy的xpath在匹配位置时无法获取,会爬取到空列表,去掉tbody就可以了
(2)与第一题基本类似,就是用来熟悉xpath,与mysql存储,还有scrapy的Item、Pipeline 数据的序列化输出方法
