数据采集与融合第三次作业
作业一:
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
| 单线程代码 |
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import os
import time
def imageSpider(start_url):
try:
urls=[]
#一些获取,解析,提取的操作
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img") #用css提取img
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src) #相对路径
if url not in urls:
urls.append(url)#去重
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count=count+1
#提取文件后缀扩展名
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
#打开,写入,关闭
fobj=open("singleimages\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
start = time.perf_counter() #开始时间
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
os.mkdir('singleimages')
imageSpider(start_url)
end = time.perf_counter() #结束时间
print (str(end-start)+'s')
| 单线程结果 |
控制台结果:
用时2.12s
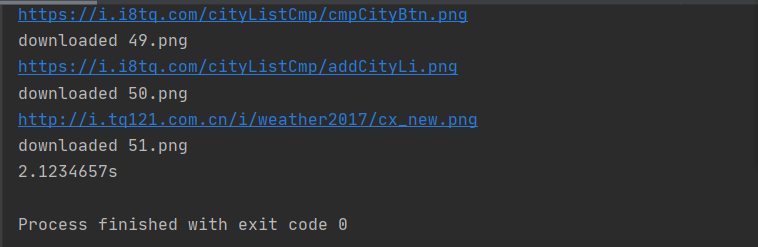
文件夹:

| 多线程代码 |
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
import os
import time
def imageSpider(start_url):
global threads
global count
try:
urls=[]
#与单线程相同
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
urls.append(url) #没有这一步就会有重复的
print(url)
count=count+1
T=threading.Thread(target=download,args=(url,count)) #实例化线程,函数为download,传入参数为url和count
T.setDaemon(False) #设为前台线程
T.start() #启动线程
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("someimages\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
start = time.perf_counter() #开始时间
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
threads=[]
os.mkdir('someimages')
imageSpider(start_url)
for t in threads:
t.join() #阻塞主线程
end = time.perf_counter() #结束时间
print("The End")
print (str(end-start)+'s')
控制台结果:
用时0.67s
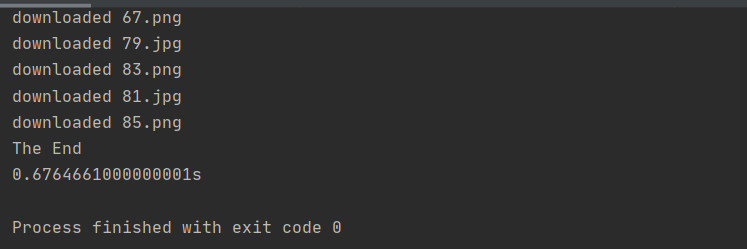
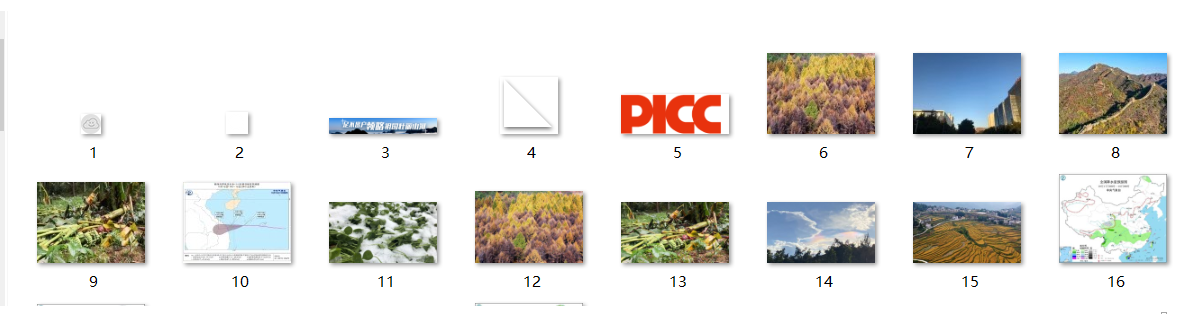
文件夹结果:
(1)书上的代码没有去重,所以第一次有80多张图片

(2)添加去重后,与单线程结果一致了
| 心得体会 |
(1)学会了如何实现多线程
(2)实验时间对比来看,单线程会因为网站的某个图像下载过慢而效率低下,而多线程中如果一个图像下载缓慢,不影响别的爬行过程
作业二、
要求:
使用scrapy框架复现作业①。
输出信息:
同作业①
| 思路 |
(1)设计items
这个就只需要一个变量来传输图片相对路径
(2)设计myspider
xpath获取所有img元素的src属性的值
(3)设计pipelines
得到图片的绝对路径,并将图片保存在指定文件夹中
(4)设计settings
DEFAULT_REQUEST_HEADERS里设置Headers
设置ITEM_PIPELINES
| 代码 |
items.py
import scrapy
class imgItem(scrapy.Item):
# define the fields for your item here like:
img = scrapy.Field()
myspider.py
import scrapy
from Weather.items import imgItem
class StocksSpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.weather.com.cn/weather/101280601.shtml']
def parse(self, response):
try:
data=response.body.decode()
selector=scrapy.Selector(text=data)
imgs=selector.xpath("//img/@src").extract() #获取所以img元素的src属性值
for img in imgs:
item=imgItem()
item['img']=img
yield item #返回item
except Exception as err:
print(err)
pipelines.py
import urllib.request
class imgPipeline(object):
count=0
urls=[]
def process_item(self, item, spider):
start_url='http://www.weather.com.cn/weather/101280601.shtml'
url=urllib.request.urljoin(start_url, item['img']) #获取绝对路径
try:
#获取后缀名
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
if url not in self.urls: #去重
self.count += 1 #图片名
print(url)
self.urls.append(url)
req = urllib.request.Request(url)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("E:\images\\" + str(self.count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(self.count) + ext)
except Exception as err:
print(err)
return item
settings.py
设置Headers和ITEM_PIPELINES
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
ITEM_PIPELINES = {
'Weather.pipelines.imgPipeline': 300,
}
entrypoint.py
用于控制台输出,--nolog不输出log信息
from scrapy import cmdline
cmdline.execute(['scrapy','crawl','myspider','--nolog'])
| 结果 |
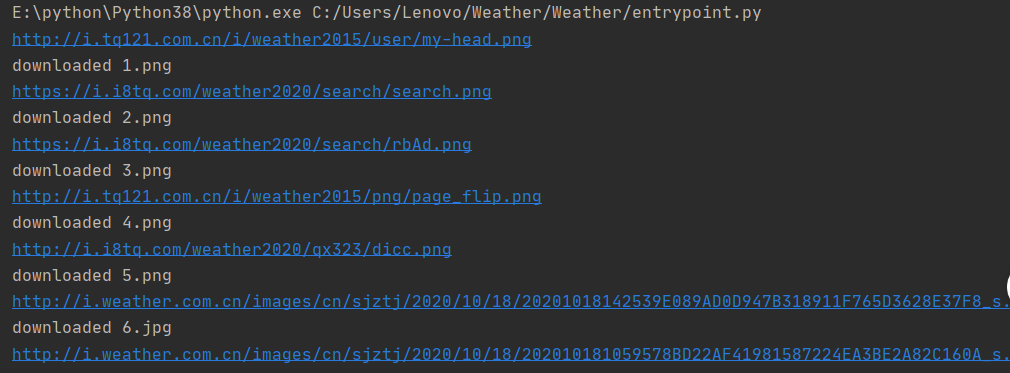
| 心得 |
(1)加深了对xpath的运用
(2)学习了scrapy框架的使用,了解了每个部分的作用,以及如何将它们串接起来,具体如下:
- items.py是定义scrapy内部数据的文件
- myspider.py 爬取数据,把数据传给 items.py
- 当items被返回的时候,会自动调用pipelines.py中的process_item()去处理数据
(3)scrapy的效率很高,会同时爬取多个url。
作业三:
要求:使用scrapy框架爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
| 思路 |
(1)设计items
item包括要获得的代码、名称、最新价等
(2)设计myspider
- 与上次一样'},{'分割不同股票,','分割不同信息
- 翻页要用yield scrapy.Request(next_url,callback = self.parse)
(3)设计pipelines
创建xls文件,将数据逐行写入
(4)设计settings
- 爬取json要设置ROBOTSTXT_OBEY = False
- 同样在DEFAULT_REQUEST_HEADERS中设置headers
- 设置ITEM_PIPELINES
| 代码 |
items.py
import scrapy
class gupiaoItem(scrapy.Item):
# define the fields for your item here like:
no = scrapy.Field() #代码
name= scrapy.Field() #名称
latest = scrapy.Field() #最新价
zdf = scrapy.Field() #涨跌幅
zde = scrapy.Field() #涨跌额
cjl = scrapy.Field() #成交量
cje = scrapy.Field() #成交额
zf = scrapy.Field() #振幅
highest= scrapy.Field() #最高
lowest = scrapy.Field() #最低
today = scrapy.Field() #今开
yesterday = scrapy.Field() #昨收
myspider.py
import scrapy
import re
from shares.items import gupiaoItem
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://28.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124015106710048560834_1602940872850&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602940872855']
page=1
def parse(self, response):
try:
data=response.body.decode()
pat = "\"data\":.*\]"
data = re.compile(pat, re.S).findall(data) # 正则表达式匹配
# 去除前面的total和diff数据
data[0] = data[0][29:]
datas = data[0].split('},{') # 不同股票分割
stocks = []
for i in range(len(datas)):
stock = datas[i].replace('"', "").split(',') # 不同信息分割,并且去掉引号
for j in range(len(stock)):
# 冒号分割,获取信息的值
t = stock[j].split(':')
stock[j] = t[1]
item=gupiaoItem()
item['no']=stock[11]
item['name'] = stock[13]
item["latest"] = stock[1]
item["zdf"] = stock[2]
item["zde"] = stock[3]
item["cjl"] = stock[4]
item["cje"] = stock[5]
item["zf"] = stock[6]
item["highest"] = stock[14]
item["lowest"] = stock[15]
item["today"] = stock[16]
item["yesterday"] = stock[17]
yield item
self.page+=1
#翻页处理,爬取前9页的数据
if self.page < 10:
next_url = 'http://28.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124015106710048560834_1602940872850&pn='+str(self.page)+'&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602940872855'
yield scrapy.Request(next_url,callback = self.parse)
except Exception as err:
print(err)
pipelines.py
import xlwt
class SharesPipeline(object):
count=0
def process_item(self, item, spider):
SharesPipeline.count+=1 #count每次加一,用于后面存储行的变化
#准备保存到xls文件中
global workbook
global worksheet
if SharesPipeline.count ==1:
workbook = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('My Worksheet')
title=['代码','名称',"最新价","涨跌幅(%)","涨跌额","成交量","成交额","振幅(%)","最高","最低","今开",'昨收']
i=0 #各个标题对应的列
for k in title:
i += 1
worksheet.write(0, i, k)
# 序号写入
worksheet.write(SharesPipeline.count, 0, SharesPipeline.count) #参数对应行,列,值
#数据写入
j=0 #列
for k in item:
j+=1
worksheet.write(SharesPipeline.count,j,item[k])
# 保存
if SharesPipeline.count ==180: #读完9页
workbook.save('Excel_test.xls')
return item
settings.py要设置的
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'shares.pipelines.SharesPipeline': 300,
}
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.8 Safari/537.36}"
}
entrypoint.py
控制台输出
from scrapy import cmdline
cmdline.execute(['scrapy','crawl','myspider','--nolog'])
| 结果 |
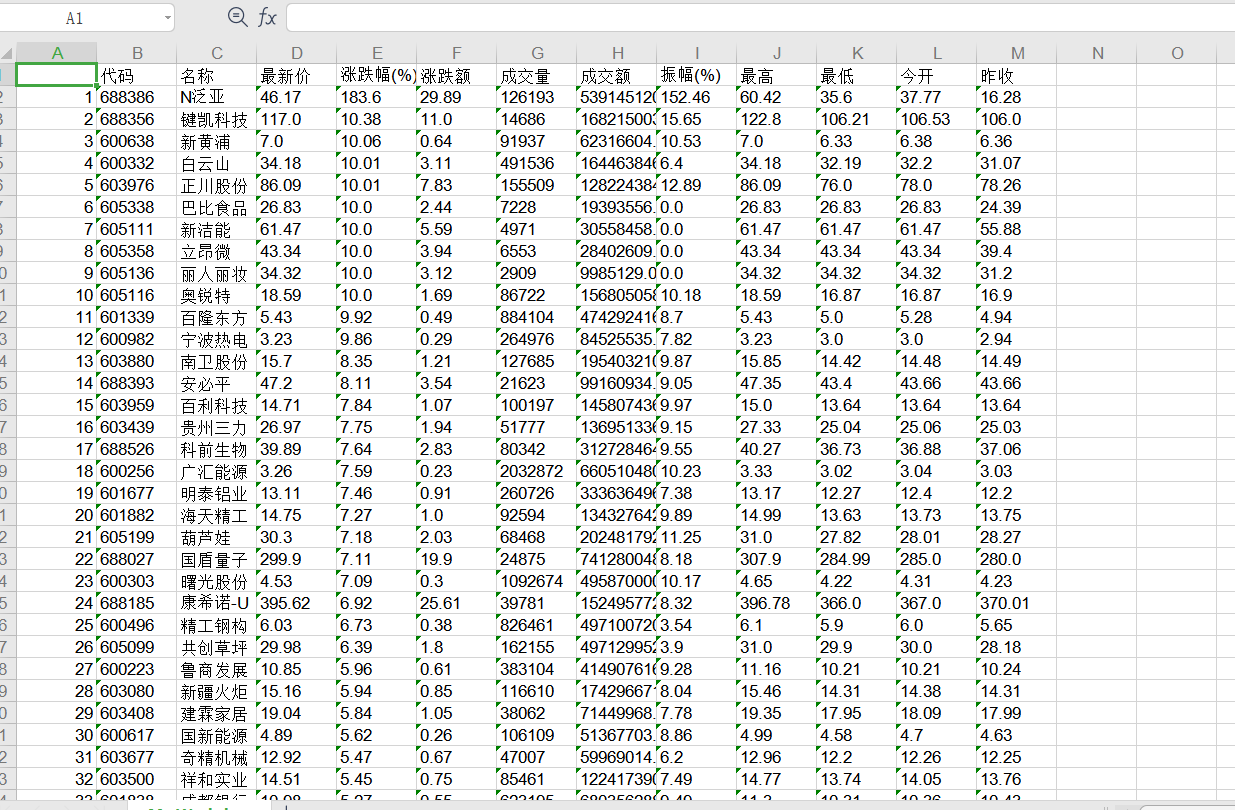
| 心得 |
(1)了解了scrapy的翻页处理,知道了myspider中的parse可以用两个yield,一个翻页,一个返回item
(2) 一开始爬取时返回一直为空,查找资料后知道要将settings文件中ROBOTSTXT_OBEY 改为 False
(3)对于xls文件的创建与写入保存更熟练了,上次直接用dataframe的to_excel,这次由于返回的是一个个item,所以逐行输入xls文件
