第一次作业——结合三次小作业
作业①
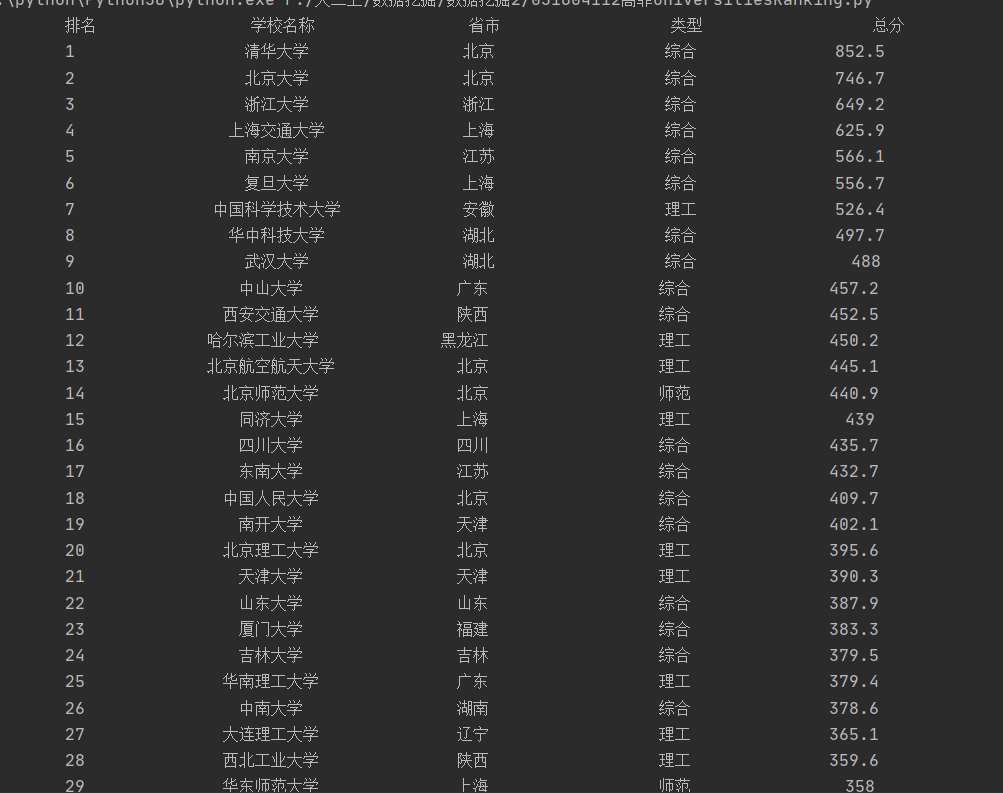
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
(1)实验代码与结果1
代码部分:
import urllib.request
from bs4 import BeautifulSoup
def gethtml(url):
html=urllib.request.urlopen(url)
return html
def printdata(html):
soup = BeautifulSoup(html, "html.parser")
title=['排名','学校名称','省市','类型','总分'] #标题
for i in range(5):
print(title[i].center(12,chr(12288)),end=' ') #居中对齐,中文空格填充
print('')
for tr in soup.find('tbody').children: #通过.children找到tr标签
t=0
for td in tr.children: #通过.children找到td标签
t+=1
print(td.text.strip().center(12,chr(12288)),end=' ') #格式化输出td的text
if(t>4): #输出前5个,即办学层次不输出
break
print('') #执行换行
if __name__ == '__main__':
url="http://www.shanghairanking.cn/rankings/bcur/2020"
html=gethtml(url)
printdata(html)
输出结果:
(2)心得体会1
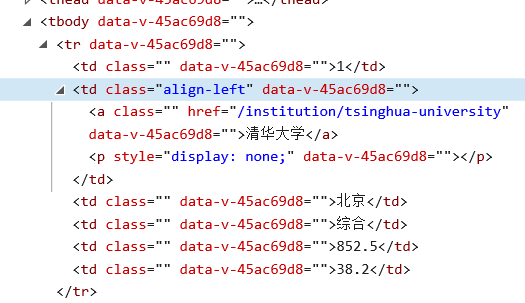
1.这次使用了find()方法来找到tbody,再通过遍历其子节点的前五个子节点来获取数据。
2.加深了对html的树结构和beautifulsoup的方法的了解。
作业②
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
(1)实验代码与结果2
代码部分:
import requests
import re
# 爬取的是淘宝网的书包,爬取价格和商品名称
# headers是登录搜索书包后复制了search文件中的user-agent和cookie
def getHtml(url):
header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36',
'cookie':'lLtC1_=1; xlly_s=1; t=4be53b788938ea8ce9ba7c2e103de98a; enc=GX0DYtGxbBUlvdX66bMfRDodgbpE9C1%2FNqxvecoWgtOtwL8CFEcgWnBVbXt1Yr79npACCvd74X1XnLKiebe%2Fgw%3D%3D; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; _m_h5_tk=8e20996d7b9cef4d7ab1f184ca684931_1600684874391; _m_h5_tk_enc=8cc9385faf7ee9e5f1784d542595aba0; XSRF-TOKEN=345eba8b-4b17-4841-b6da-6e5aa97f0321; cookie2=1650903b671126e609c6ac4e51d5eaab; _tb_token_=ebea86eebb348; '
'_samesite_flag_=true; cna=dk1jF5nMz1sCAXjQepw3F2cQ; sgcookie=E100SAdOj4bjiEGc4C2Vd7jSY3RKwiXrLxV5zj%2FY2jBmqnm6HIYKSOmp6Nt%2BLp0n8%2BMshtdxQt0pL1Ue5%2BaO6r0Yeg%3D%3D; unb=4159438384; uc3=vt3=F8dCufeKwhcCBR4P9kA%3D&nk2=F5RMGoDRDG%2FrDn8%3D&lg2=UIHiLt3xD8xYTw%3D%3D&id2=Vy0WqANXyLs4Bg%3D%3D; csg=e5661e8b; lgc=tb934518942; cookie17=Vy0WqANXyLs4Bg%3D%3D; dnk=tb934518942; skt=3bac74297569de66; existShop=MTYwMDY3NzYwOA%3D%3D;'
' uc4=id4=0%40VXqYzIs5jcyTW1R6Gw44QvvD0%2BT6&nk4=0%40FY4HX7Jz67CCTN9fBvcCkaRbls9olQ%3D%3D; tracknick=tb934518942; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; sg=249; _nk_=tb934518942; cookie1=ACixLlTxxu3%2FZy9T9EI0xT8Y8Rw1mzsO%2Fp4bffR5oCE%3D; mt=ci=0_1; uc1=cookie15=UtASsssmOIJ0bQ%3D%3D&cookie14=Uoe0bU5TpnKklA%3D%3D&pas=0&cookie21=Vq8l%2BKCLjA%2Bl&cookie16=VFC%2FuZ9az08KUQ56dCrZDlbNdA%3D%3D&existShop=false; '
'tfstk=ciwNB0mj7OBakxkfwAM2h2cJjIDOZqgmPporsSAJvHWOMchGil8xxMTxYmuRKff..;'
' l=eBxbtxR7OFMOT5GbBOfahurza77OSIRYluPzaNbMiOCP9Ifp5BDNWZrtTzL9C3hVhs_9R3-WSGYuBeYBq3xonxvtNSVsr4Dmn; isg=BAwM2mnSvzcEIKtLcF2RaC9H3Wo-RbDvKvdMV2bNGLda8az7jlWAfwJDkPlJ_-hH',}
r = requests.get(url, headers=header)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
def getdata(html):
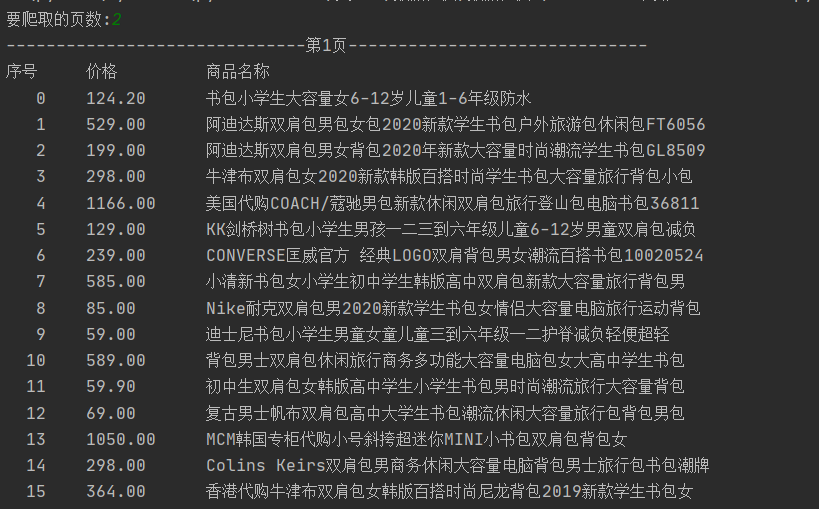
print("{:4}\t{:8}\t{:16}".format("序号","价格","商品名称"))
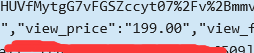
p = re.findall(r'"view_price":"[\d\.]*"',html) #[\d\.]匹配数字或小数点
t = re.findall(r'"raw_title":".+?"',html) # 加问号懒惰匹配,匹配到第一个"就结束了
for i in range(len(p)):
price = eval(p[i].split(':')[1])
name = eval(t[i].split(':')[1]) #冒号分割,eval去引号
print("{:4}\t{:8}\t{:16}".format(i,price,name))
if __name__ == '__main__':
url = "https://s.taobao.com/search?q=书包"
page = int(input("要爬取的页数:")) #获取需要爬取的页数
for i in range(page):
print('-'*30+'第'+str(i+1)+'页'+'-'*30)
url = url +'&s='+str(44*i) # 用修改s属性的方式进行翻页
html = getHtml(url)
getdata(html)
输出结果:

(2)心得体会2
在淘宝搜索书包,F12找到商品名称和价格如下图:

1.通过正则表达式来匹配这样的键值对,然后用冒号分割,得到商品名称和价格。
2.".+?"问号懒惰匹配,匹配到第一个"结束。
3.爬取淘宝数据要设置请求头Headers,headers是登录搜索书包后复制了F12->network->find all->search文件中的user-agent和cookie,来解决反爬机制。
4.对于翻页:
对比1,2,3页网址
第一页:https://s.taobao.com/search?q=书包&s=0
第二页:https://s.taobao.com/search?q=书包&s=44
第三页:https://s.taobao.com/search?q=书包&s=88
可以通过修改s属性的方式翻页。
作业③
要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
(1)实验代码与结果3
代码部分:
import urllib.request
from bs4 import BeautifulSoup
import re
import os
#爬取了福大新闻网的jpg形式图片
def gethtml(url):
html=urllib.request.urlopen(url)
return html
def get_save_jpg(html,path):
soup = BeautifulSoup(html,"html.parser")
img=".+\.(jpg|JPG)" #所有jpg图片
jpg = soup.find_all("img",{"src":re.compile(img)}) #beautifulsoup和正则表达式结合
for r in jpg:
name = r.attrs["src"] #获取src值
rename=name.replace("/","_") #图片名中的"/"会和路径冲突,所以换成下划线
img_url=url+name #绝对路径
urllib.request.urlretrieve(img_url, path+rename) #保存到F:/image/下
print("文件保存成功")
if __name__ == '__main__':
url = "http://news.fzu.edu.cn/" #福大新闻网
path = "F:/image/"
os.mkdir(path) #新建一个目录
html=gethtml(url)
get_save_jpg(html,path)
文件保存结果:
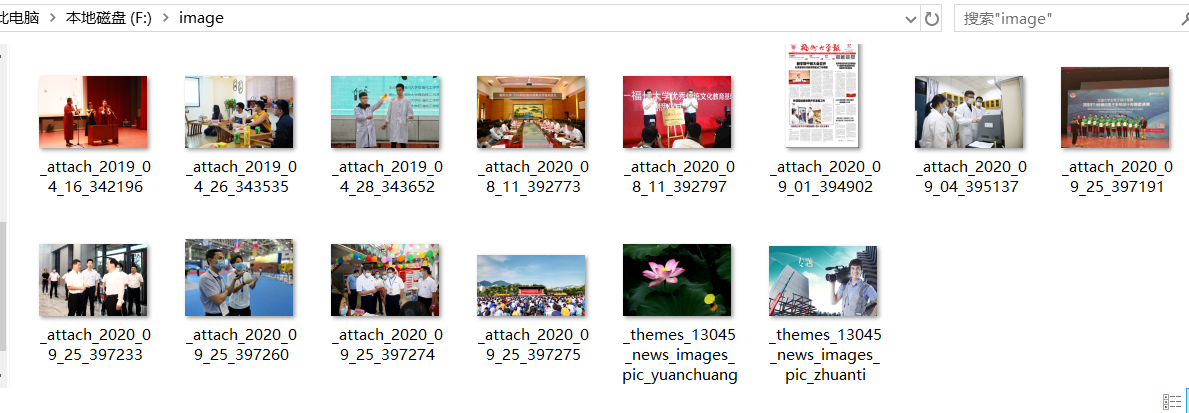
(2)心得体会3
1.爬取图片要找到图片链接,通过beautifulsoup和正则表达式结合来找到所有的jpg图片的相对路径,再用url+相对路径换成绝对路径,通过urllib.request.urlretrieve来复制到本地。
2.有的图片是JPG后缀,一开始忽略了。
3.保存时图片名中有'/',保存时会被当成保存路径,所以替换成了下划线。
