第一次个人编程作业
### [ <font color="#5F9EA0">Github链接</font><br/>](https://github.com/lumosqqq/gf)</font><br/>
一、计算模块接口的设计与实现过程
对于这个题目,搜索到了很多算法。跟着这篇博客试了一下doc2vec之后,发现结果很高,决定放弃。
本来想用TF-IDF做的,后面看到了这篇博客:余弦相似度.发现关键词就按照jieba分词后去停用词,比较简单,效果也挺好,时间比起TF-IDF也要短些,就这么写了。
| 代码的大体流程如下: |
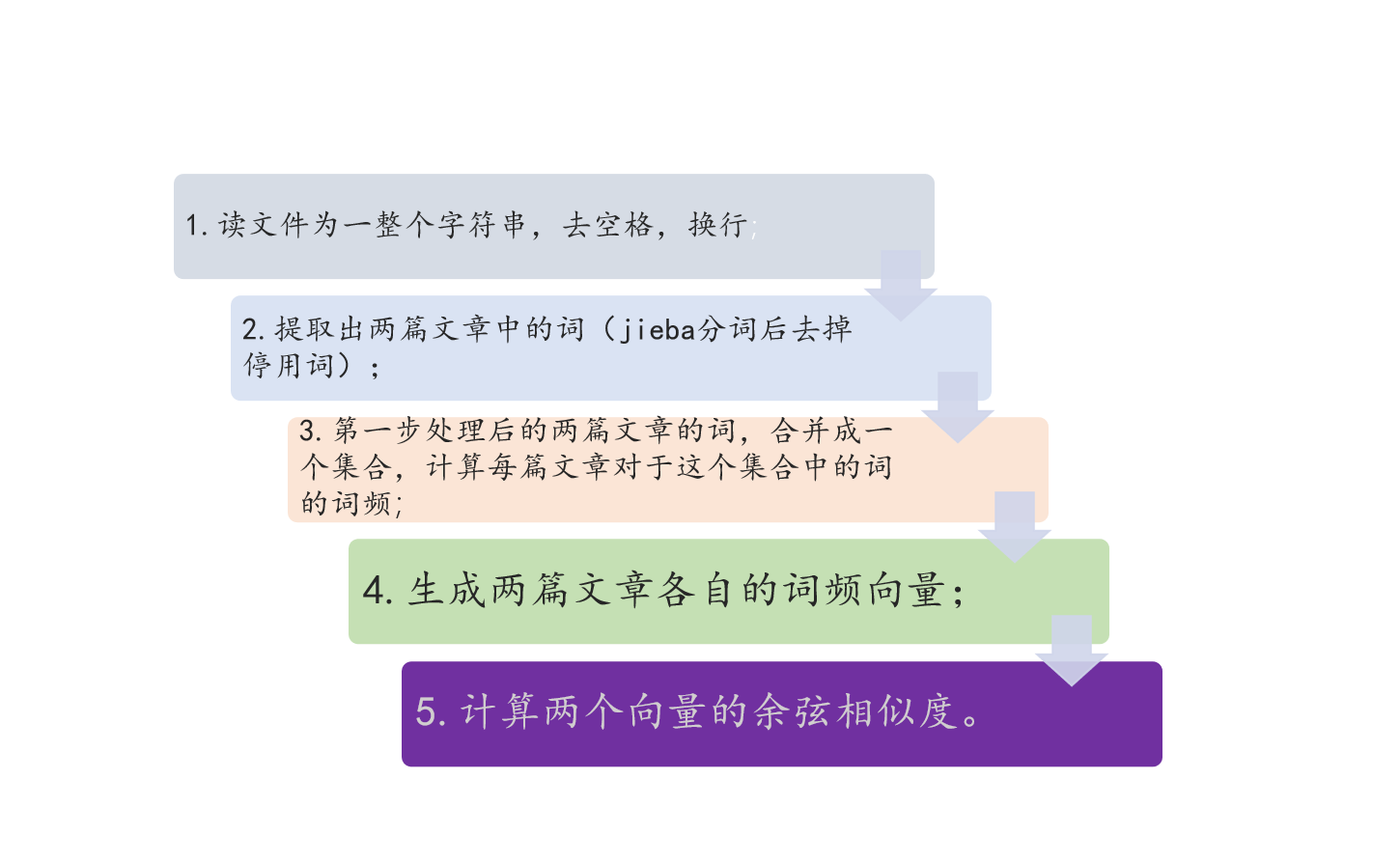
| 设计的函数有: |
-
read_file(path)
读文件,去换行符和空格 -
get_stopwords()
加载停用词 -
text2vector(text, stopwords)
去停用词,计算词频 -
cos_similarity(v1, v2)
计算相似度 -
向量化过程写进主函数中了
| 比较关键的是词频向量: |
def text2vector(text, stopwords):
# 分词,去停用词(停用词含常用标点)
words = jieba.cut(text)
words = [word for word in words if word not in stopwords]
word_counts = Counter(words)
return word_counts
| 之后将第一步处理后的两篇文章的词,合并成一个集合,计算每篇文章对于这个集合中的词的词频,生成两篇文章各自的词频(这些我写在主函数里) |
ori_counter = text2vector(ori_text, stopword)
comp_counter = text2vector(comp_text, stopword)
total_words = set(list(ori_counter.keys()) + list(comp_counter.keys()))
ori_vector = np.zeros(len(total_words))
comp_vector = np.zeros(len(total_words))
for idx, word in enumerate(total_words):
ori_vector[idx] = ori_counter.get(word, 0)
comp_vector[idx] = comp_counter.get(word, 0)
| 余弦相似度计算: |
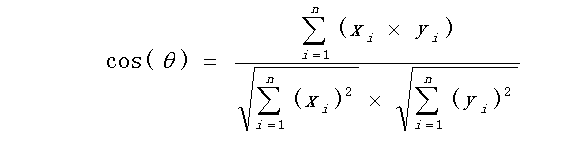
def cos_similarity(v1, v2):
# 计算余弦相似度
numerator = np.inner(v1,v2)
denominator = np.linalg.norm(v1) * np.linalg.norm(v2)
if denominator!=0:
return numerator / denominator
else:
return 0
| 结果 |
- orig.txt orig_0.8_add.txt 0.85
- orig.txt orig_0.8_del.txt 0.88
- orig.txt orig_0.8_dis_1.txt 0.97
- orig.txt orig_0.8_dis_3.txt 0.95
- orig.txt orig_0.8_dis_7.txt 0.93
- orig.txt orig_0.8_dis_10.txt 0.90
- orig.txt orig_0.8_dis_15.txt 0.72
- orig.txt orig_0.8_mix.txt 0.92
- orig.txt orig_0.8_rep.txt 0.81
| 独到之处: |
二、计算模块接口部分的性能改进
用pycharm的Profile性能分析如下:
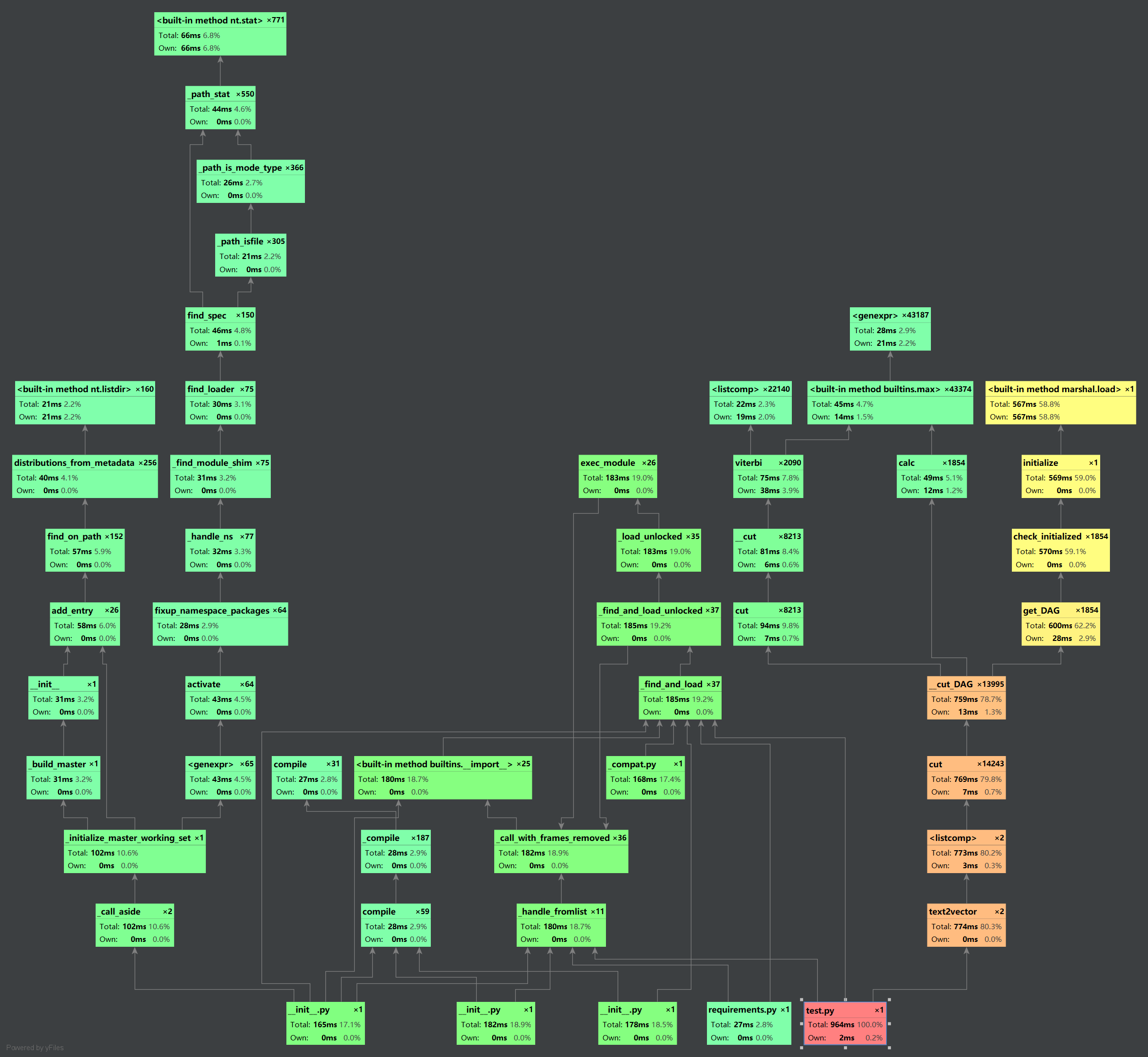
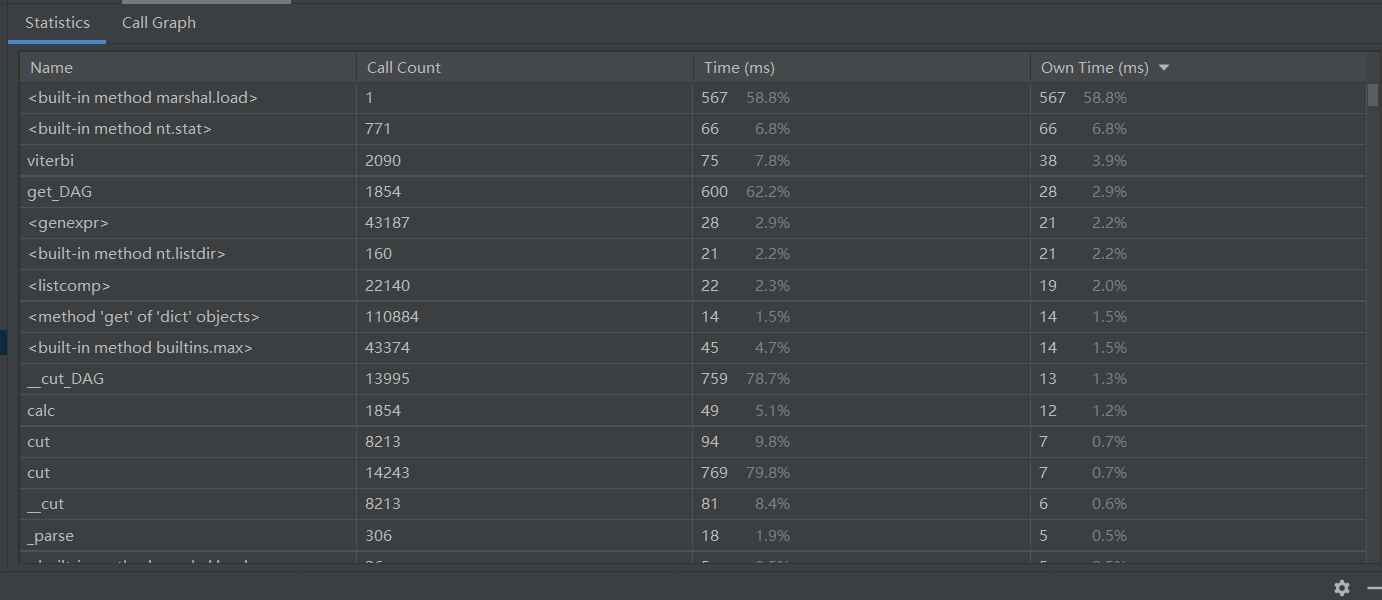
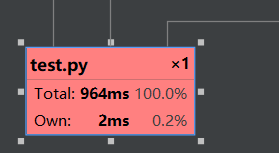
性能改进的过程就是从TF-IDF到TF,之前使用TF-IDF时间几乎是改进后的两倍。
因为有停用词的存在,所以TF准确度还可以,时间上要快一些。
之后改进的方向是准确度方面。
三、计算模块部分单元测试展示
| 部分测试代码: |
import unittest
import test
from BeautifulReport import BeautifulReport
class TestForAllText(unittest.TestCase):
def test_self2(self):
test.simi('orig.txt', 'orig_self2.txt', 'D:/xx.txt')
def test_self3(self):
test.simi('orig.txt', 'orig_self3.txt', 'D:/xx.txt')
def test_self4(self):
test.simi('orig.txt', 'orig_self4.txt', 'D:/xx.txt')
def test_self5(self):
test.simi('orig.txt', 'orig_self5.txt', 'D:/xx.txt')
def test_self6(self):
test.simi('orig.txt', 'orig_self6.txt', 'D:/xx.txt')
def test_self7(self):
test.simi('orig.txt', 'orig_self7.txt', 'D:/xx.txt')
def test_self8(self):
test.simi('orig.txt', 'orig_self8.txt', 'D:/xx.txt')
def test_self9(self):
test.simi('orig.txt', 'orig_self9.txt', 'D:/xx.txt')
def test_self10(self):
test.simi('orig.txt', 'orig_self10.txt', 'D:/xx.txt')
def test_self11(self):
test.simi('orig.txt', 'orig_selfk.txt', 'D:/xx.txt')
if __name__ == '__main__':
suite.addTest(TestForAllText('test_self2'))
suite.addTest(TestForAllText('test_self3'))
suite.addTest(TestForAllText('test_self4'))
suite.addTest(TestForAllText('test_self5'))
suite.addTest(TestForAllText('test_self6'))
suite.addTest(TestForAllText('test_self7'))
suite.addTest(TestForAllText('test_self8'))
suite.addTest(TestForAllText('test_self9'))
suite.addTest(TestForAllText('test_self10'))
suite.addTest(TestForAllText('test_self11'))
runner = BeautifulReport(suite)
runner.report(
description='论文查重测试报告', # => 报告描述
filename='nlp_TFIDF.html', # => 生成的报告文件名
log_path='.' # => 报告路径
)
| 报告结果 |
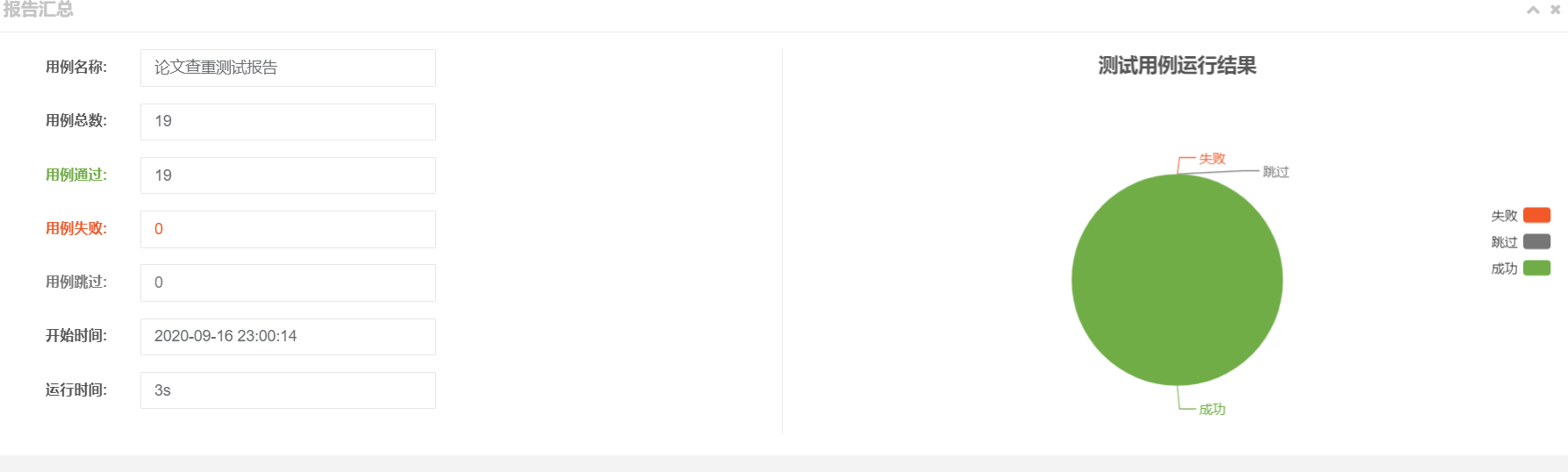
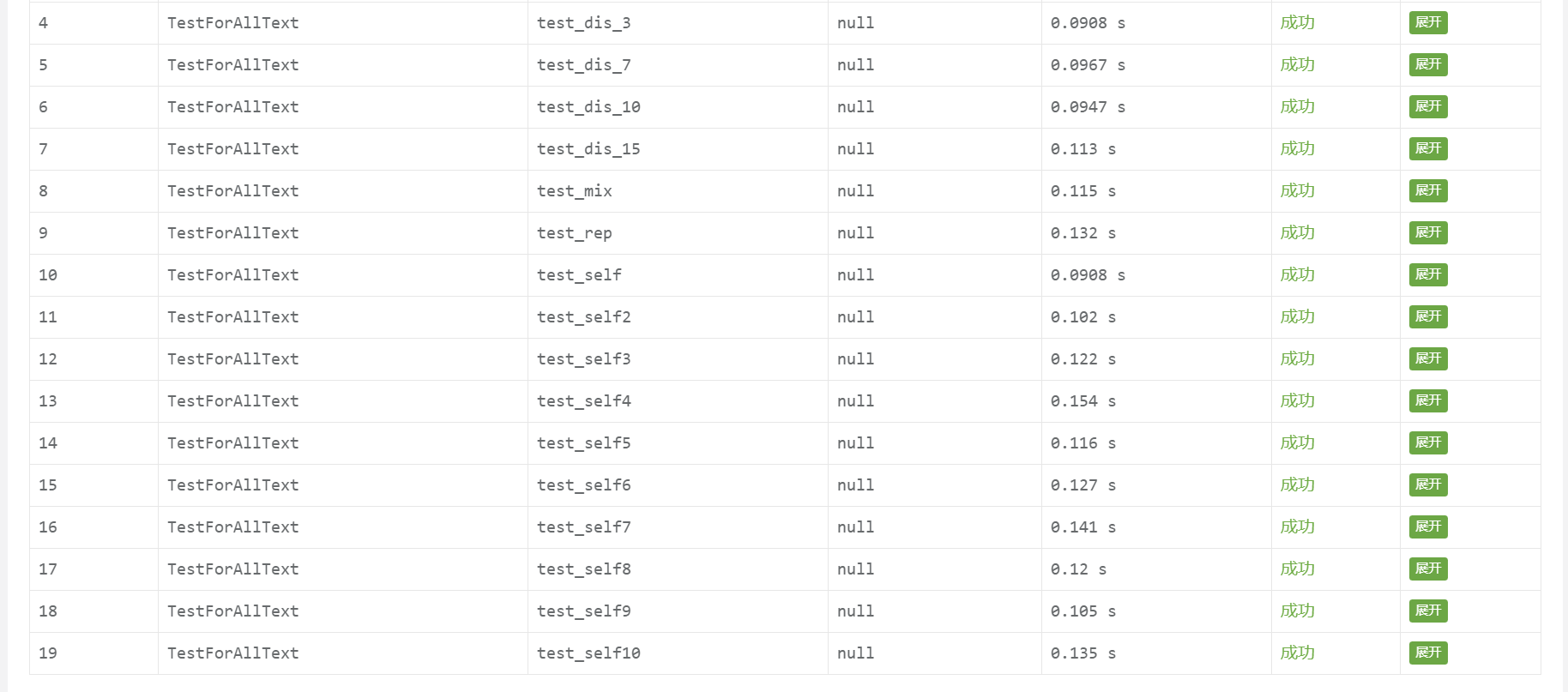
| 对自己生成的文件的测试情况 |
- orig.txt orig_self.txt 0.98
- orig.txt orig_self2.txt 0.93
- orig.txt orig_self3.txt 0.87
- orig.txt orig_self4.txt 0.72
- orig.txt orig_self5.txt 0.86
- orig.txt orig_self6.txt 0.86
- orig.txt orig_self7.txt 0.83
- orig.txt orig_self8.txt 0.91
- orig.txt orig_self9.txt 0.94
- orig.txt orig_self10.txt 0.94
其中9个作业测试文本,还有10个自己生成的测试文本。生成测试文本的思路就是参考了苏艺淞同学博客中的代码。
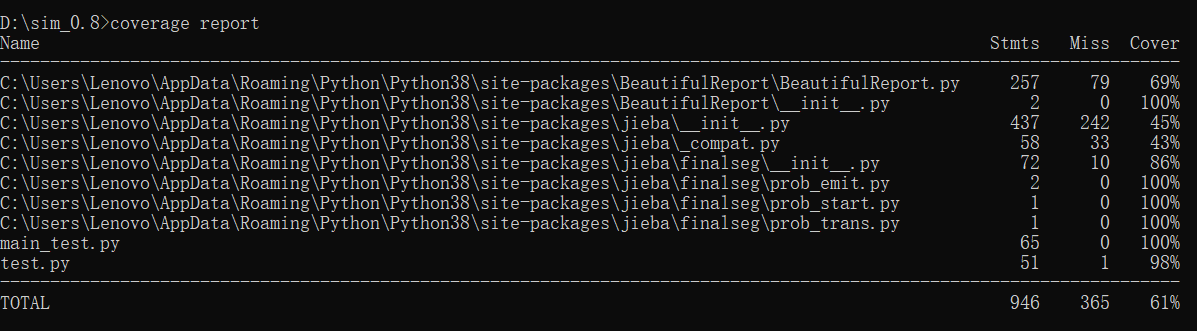
| 代码覆盖率 |
四、计算模块部分异常处理说明
1.简单对文件读入路径不存在做了一个异常处理。
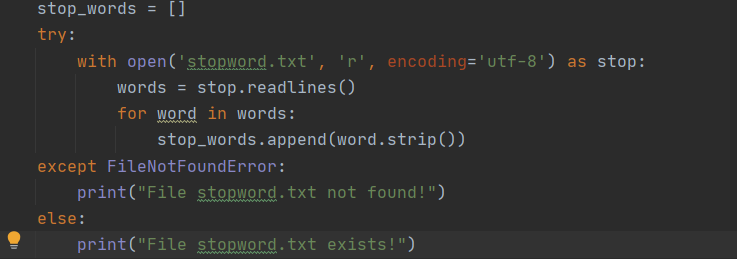
样例:
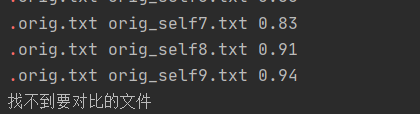

2.对读入文本为空的异常处理

样例:


五:PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 480 | 720 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 240 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 50 |
| · Coding | · 具体编码 | 240 | 320 |
| · Code Review | · 代码复审 | 30 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 40 |
| Reporting | 报告 | 60 | 80 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 40 |
| · 合计 | 1680 | 1790 |
六:作业总结
这次作业我开始做的时间比较晚,导致这几天花了非常多时间在这个项目上面,比较赶,是一个教训吧。
学习了很多新的东西,比如在github上上传代码,使用性能分析工具,单元测试等。
收获很大,自己对软工这门课的认知有所改变
七:一些小问题
1.一开始用round来保留两位小数,结果round在实际位数小于输入参数的时候,按照实际位数,所以换成了"%.2f" % sim


