
MapReduce的思想就是“分而治之”。
1)Mapper负责“分”
把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:
数据或计算的规模相对原任务要大大缩小
就近计算原则,任务会分配到存放着所需数据的节点上进行计算
这些小任务可以并行计算彼此间几乎没有依赖关系
2)Reducer负责对map阶段的结果进行汇总。
至于需要多少个Reducer,可以根据具体问题,
通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
MapReduce工作机制:
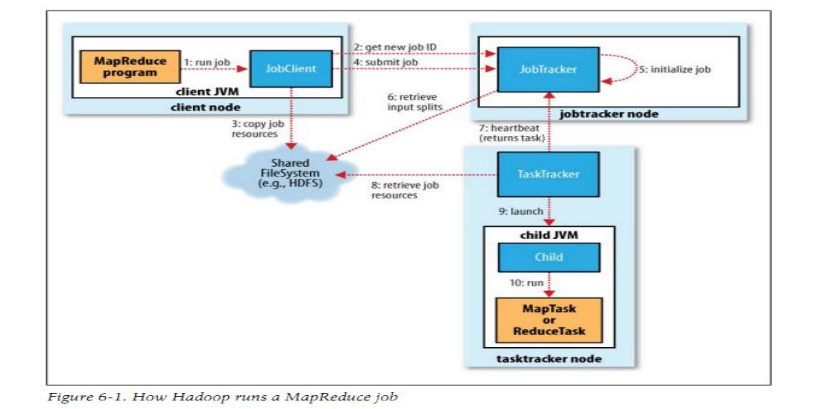
Mapreduce作业的4个对象:
客户端(client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行;
TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务, TaskTracker和JobTracker的不同有个很重要的方面,就是在执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个(JobTracker只能有一个就和hdfs里namenode一样存在单点故障)。
Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面。
mapreduce运行步骤:
首先是客户端要编写好mapreduce程序,配置好mapreduce的作业也就是job,
接下来就是提交job了,提交job是提交到JobTracker上的,这个时候JobTracker就会构建这个job,具体就是分配一个新的job任务的ID值
接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误,至于输入分片我后面会做讲解的,这些都做好了JobTracker就会配置Job需要的资源了。
分配好资源后,JobTracker就会初始化作业,初始化主要做的是将Job放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器会初始化这个job,初始化就是创建一个正在运行的job对象(封装任务和记录信息),以便JobTracker跟踪job的状态和进程。
初始化完毕后,作业调度器会获取输入分片信息(input split),每个分片创建一个map任务。
接下来就是任务分配了,这个时候tasktracker会运行一个简单的循环机制定期发送心跳给jobtracker,心跳间隔是5秒,程序员可以配置这个时间,心跳就是jobtracker和tasktracker沟通的桥梁,通过心跳,jobtracker可以监控tasktracker是否存活,也可以获取tasktracker处理的状态和问题,同时tasktracker也可以通过心跳里的返回值获取jobtracker给它的操作指令。
任务分配好后就是执行任务了。在任务执行时候jobtracker可以通过心跳机制监控tasktracker的状态和进度,同时也能计算出整个job的状态和进度,而tasktracker也可以本地监控自己的状态和进度。当jobtracker获得了最后一个完成指定任务的tasktracker操作成功的通知时候,jobtracker会把整个job状态置为成功,然后当客户端查询job运行状态时候(注意:这个是异步操作),客户端会查到job完成的通知的。如果job中途失败,mapreduce也会有相应机制处理,一般而言如果不是程序员程序本身有bug,mapreduce错误处理机制都能保证提交的job能正常完成。
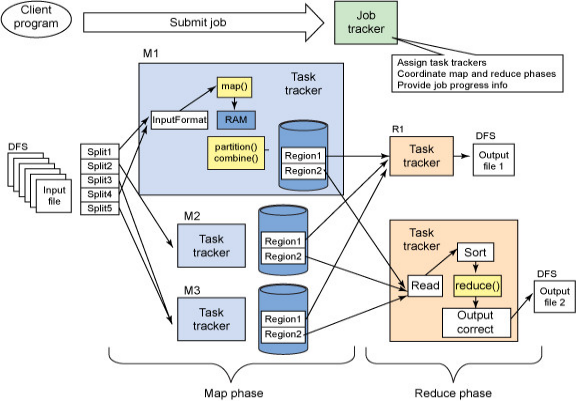
在Hadoop中,一个MapReduce作业会把输入的数据集切分为若干独立的数据块,由Map任务以完全并行的方式处理
框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。
作业的输入和输出都会被存储在文件系统中,整个框架负责任务的调度和监控,以及重新执行已经关闭的任务
MapReduce框架和分布式文件系统是运行在一组相同的节点,计算节点和存储节点都是在一起的
一个MapReduce作业的输入和输出类型:
会有三组<key,value>键值对类型的存在:

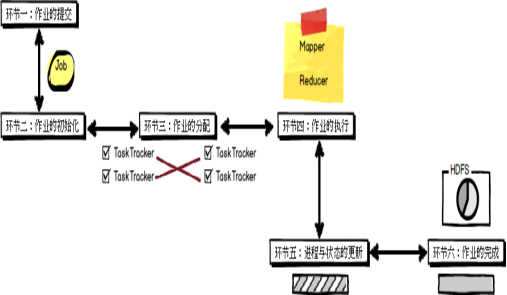
Mapreduce作业的处理流程:
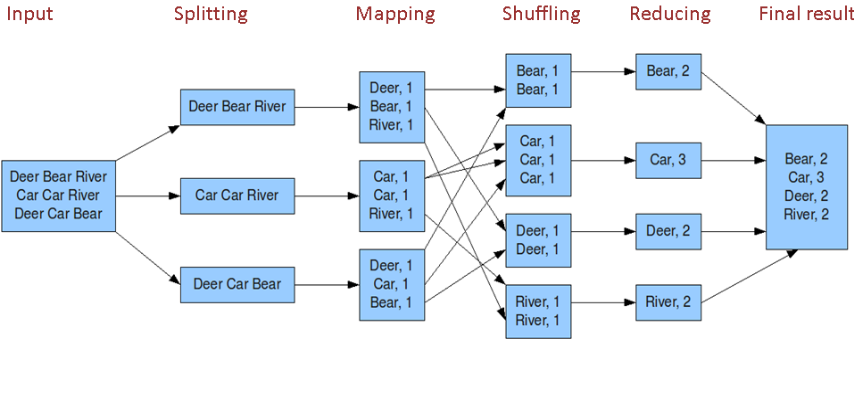
按照时间顺序包括:
输入分片(input split)、map阶段、combiner阶段、shuffle阶段和reduce阶段。
输入分片(input split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务 输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片(input split)往往和hdfs的block(块)关系很密切 假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片(input split),65mb则是两个输入分片(input split)而127mb也是两个输入分片(input split) 即我们如果在map计算前做输入分片调整,例如合并小文件,那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
map阶段: 程序员编写好的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行;
combiner阶段:combiner阶段是程序员可以选择的,combiner其实也是一种reduce操作,因此我们看见WordCount类里是用reduce进行加载的。 Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,例如我们对文件里的单词频率做统计,map计算时候如果碰到一个hadoop的单词就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么文件会变小,这样就提高了宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入, 例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
shuffle阶段:将map的输出作为reduce的输入的过程就是shuffle了。
reduce阶段:和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号