
HDFS和MR主要针对大数据文件来设计,在小文件处理上效率低.解决方法是选择一个容器,将这些小文件包装起来,将整个文件作为一条记录,可以获取更高效率的储存和处理,避免多次打开关闭流耗费计算资源.hdfs提供了两种类型的容器 SequenceFile和MapFile。
小文件问题解决方案 在原有HDFS基础上添加一个小文件处理模块,具体操作流程如下: 当用户上传文件时,判断该文件是否属于小文件,如果是,则交给小文件处理模块处理,否则,交给通用文件处理模块处理。在小文件模块中开启一定时任务,其主要功能是当模块中文件总size大于HDFS上block大小的文件时,则通过SequenceFile组件以文件名做key,相应的文件内容为value将这些小文件一次性写入hdfs模块。 同时删除已处理的文件,并将结果写入数据库。 当用户进行读取操作时,可根据数据库中的结果标志来读取文件。
Sequence file
Sequence file由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。Hadoop-0.21.0版本开始中提供了SequenceFile,包括Writer,Reader和SequenceFileSorter类进行写,读和排序操作。该方案对于小文件的存取都比较自由,不限制用户和文件的多少,支持Append追加写入,支持三级文档压缩(不压缩、文件级、块级别)。其存储结构如下图所示:

SequenceFile储存
文件中每条记录是可序列化,可持久化的键值对,提供相应的读写器和排序器,写操作根据压缩的类型分为3种 :
Write 无压缩写数据。
RecordCompressWriter记录级压缩文件,只压缩值。
BlockCompressWrite块级压缩文件,键值采用独立压缩方式。
在储存结构上,sequenceFile主要由一个Header后跟多条Record组成,如图:
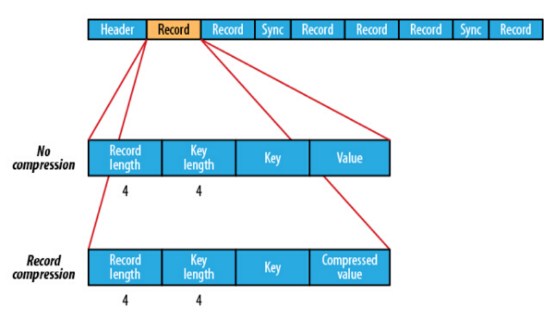
前三个字节是一个Bytes SEQ代表着版本号,同时header也包括key的名称,value class , 压缩细节,metadata,以及Sync markers。Sync markers的作用在于可以读取任意位置的数据。 在records中,又分为是否压缩格式。当没有被压缩时,key与value使用Serialization序列化写入SequenceFile。当选择压缩格式时,record的压缩格式与没有压缩其实不尽相同,除了value的bytes被压缩,key是不被压缩的。 当保存的记录很多时候,可以把一串记录组织到一起同一压缩成一块。 在Block中,它使所有的信息进行压缩,压缩的最小大小由配置文件中,io.seqfile.compress.blocksize配置项决定。
SequenceFile写操作:
通过createWrite创建SequenceFile对象,返回Write实例,指定待写入的数据流如FSDataOutputStream或FileSystem对象和Path对象。还需指定Configuration对象和键值类型(都需要能序列化)。 SequenceFile通过API来完成新记录的添加操作 fileWriter.append(key,value);
fileWriter.append(key,value);
private static void writeTest(FileSystem fs, int count, int seed, Path file,
CompressionType compressionType, CompressionCodec codec)
throws IOException {
fs.delete(file, true);
LOG.info("creating " + count + " records with " + compressionType +
" compression");
//指明压缩方式
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf, file,
RandomDatum.class, RandomDatum.class, compressionType, codec);
RandomDatum.Generator generator = new RandomDatum.Generator(seed);
for (int i = 0; i < count; i++) {
generator.next();
//keyh
RandomDatum key = generator.getKey();
//value
RandomDatum value = generator.getValue();
//追加写入
writer.append(key, value);
}
writer.close();
}
public class SequenceFileWriteDemo {
private static final String[] DATA = { "One, two, buckle my shoe", "Three, four, shut the door", "Five, six, pick up sticks", "Seven, eight, lay them straight", "Nine, ten, a big fat hen" };
public static void main(String[] args) throws IOException {
String uri = =“hdfs://master:8020/number.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]); System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
} }
finally { IOUtils.closeStream(writer); }
}
}
读取SequenceFile:
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = =“hdfs://master:8020/number.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
//同步记录的边界
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}

MapFile:
一个MapFile可以通过SequenceFile的地址,进行分类查找的格式。使用这个格式的优点在于,首先会将SequenceFile中的地址都加载入内存,并且进行了key值排序,从而提供更快的数据查找。 与SequenceFile只生成一个文件不同,MapFile生成一个文件夹。 索引模型按128个键建立的,可以通过io.map.index.interval来修改 缺点
1.文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录。
2.当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的。
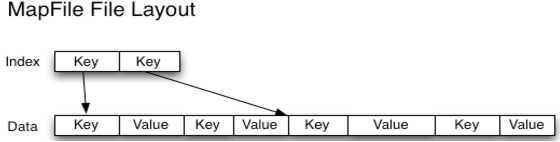
排序后的SequeneceFile,并且它会额外生成一个索引文件提供按键的查找.读写mapFile与读写SequenceFile 非常类似,只需要换成MapFile.Reader和MapFile.Writer就可以了。 在命令行显示mapFile的文件内容同样要用 -text。
MapFile写操作:
public class MapFileWriteFile
{
private static final String[] myValue={"hello world","bye world","hello hadoop","bye hadoop"};
public static void main(String[] args)
{
String uri=“hdfs://master:8020/number.map";
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
IntWritable key=new IntWritable();
Text value=new Text();
MapFile.Writer writer=null;
try
{
writer=new MapFile.Writer(conf,fs,uri,key.getClass(),value.getClass());
for(int i=0;i<500;i )
{
key.set(i);
value.set(myValue[i%myValue.length]);
writer.append(key,value);
}
finally {IOUtils.closeStream(writer);}
}
}
}
MapFile会生成2个文件 1个名data,1个名index
查看前10条data+index $ hdfs –fs –text /number.map/data | head
读取MapFile:
public class MapFileReadFile
{
public static void main(String[] args)
{
String uri=“hdfs://master:8020/number.map";
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
MapFile.Reader reader=null;
try
{
reader=new MapFile.Reader(fs,uri,conf);
WritableComparable key=(WritableComparable)ReflectionUtils.newInstance(reader.getValueClass(),conf);
while(reader.next(key,value))
{
System.out.printf("%s\t%s\n",key,value);
}
reader.get(new IntWritable(7),value);
System.out.printf("%s\n",value);
}
finally
{ IOUtils.closeStream(reader); }
}
}
SequenceFile文件是用来存储key-value数据的,但它并不保证这些存储的key-value是有序的, 而MapFile文件则可以看做是存储有序key-value的SequenceFile文件。 MapFile文件保证key-value的有序(基于key)是通过每一次写入key-value时的检查机制,这种检查机制其实很简单,就是保证当前正要写入的key-value与上一个刚写入的key-value符合设定的顺序, 但是,这种有序是由用户来保证的,一旦写入的key-value不符合key的非递减顺序,则会直接报错而不是自动的去对输入的key-value排序。
SequenceFile转换为MapFile mapFile既然是排序和索引后的SequenceFile那么自然可以把SequenceFile转换为MapFile使用mapFile.fix()方法把一个SequenceFile文件转换成MapFile

 浙公网安备 33010602011771号
浙公网安备 33010602011771号