


十分钟Pandas快速入门--机器学习基础(python)(二)
@
目录
基本数据操作
本文基本数据操作数据准备:
# 创建一个符合均匀分布的数据集(634,7)
import numpy as np
import pandas as pd
# 生成数据
data = np.random.uniform(-20,20, (634,7))
# 生成行索引
date = pd.date_range(start="20210601", periods=634, freq="B")
# 生成列索引
stock_name = ["open","high","close","low","volume","price_change","p_change"]
# 将数据加载到DataFrame中,并加上行列索引
data = pd.DataFrame(data, index = date, columns=stock_name)
data
下面展示部分生成数据

一、索引操作
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用。
直接使用行列索引(先列后行)
获取‘2021-06-04’这天的close的结果
# 注意先列后行
data["close"]["2021-06-04"]
# output
# -1.0426990669399316
结合loc或者iloc使用索引
若想要先行后列
获取"2021-06-01"至"2021-06-06",‘close’的数据
# 二者输出结果相同
data.loc["2021-06-04"]["close"]
data.loc["2021-06-04","close"]
# output
# -1.0426990669399316
# 使用iloc可直接使用数字索引
data.iloc[3,2]
# output
# -1.0426990669399316
# 组合索引
data.ix[:4,["open", "close", "high", "low"]]
组合索引输出:
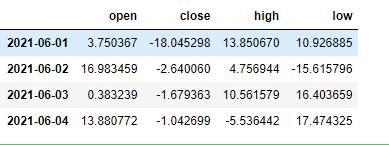
但是这种组合版本在以后的版本中会被取消
DeprecationWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
但是我们仍有办法使用组合索引:
# 使用loc来使用组合索引
data.loc[data.index[0:4],["open", "close", "high", "low"]]
# 使用iloc来使用组合索引
data.iloc[:4,data.columns.get_indexer(["open", "close", "high", "low"])]
返回结果与 ix 组合索引一样
二、赋值与排序
赋值
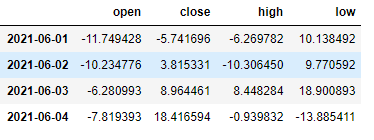
例如:对DataFrame中的close列重新赋值为1
# 直接修改原来的值
new_data1 = data
new_data["close"] = 1
# 或者
new_data2 = data
new_data2.close = 1
new_data1.head(5)
new_data2.head(5)
返回结果:
排序
排序有两种形式,一种是对内容进行排序,一种是对索引进行排序
DataFrame
- 使用df.sort_values(key = , ascending = ) 对内容进行排序
-- 单个键或者多个键惊醒排序,默认升序
-- ascending=False :降序
-- ascending=True :升序 - sort_index()
-- 按照索引进行排序 - 使用series.sort_values(ascending=True) 对内容进行排序
-- series排序时,只有一列,不需要参数
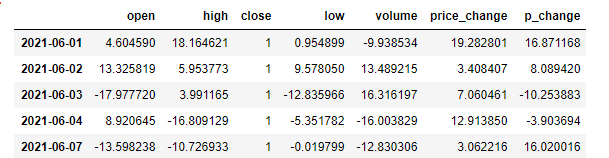
# 按 p_change进行排序
data = data.sort_values(by="p_change", ascending=True)
# 先按 high 进行排序, 再按 p_change进行排序
data = data.sort_values(by=["high","p_change"])
# 使用sort_index进行排序,按照日期索引从大到小排序,或从小到大排序
data = data.sort_index()
# Series
# 使用series.sort_values(ascending=True) 对内容进行排序
# series排序时,只有一列,不需要参数
data["p_change"].sort_values(ascending=True).head(
# 2022-10-20 -19.919984
# 2022-05-11 -19.919346
# 2023-02-06 -19.912896
# 2021-07-21 -19.886578
# 2021-09-07 -19.876232
# Name: p_change, dtype: float64
# 使用series.sort_index() 对索引进行排序
data["p_change"].sort_index().head()
# 2021-06-01 16.871168
# 2021-06-02 8.089420
# 2021-06-03 -10.253883
# 2021-06-04 -3.903694
# 2021-06-07 16.020016
# Name: p_change, dtype: float64
三、DataFrame的运算
注意:以下的运算操作对于DataFrame与series都适用
算术运算
# dataframe的加减乘除运算
# 加
data.add(10)
data + 10
# 减
data.sub(10)
data - 10
# 如果想要得到每天的涨跌大小?求出每天close - open价格差
# 1. 筛选两列数据
close = data.close
open = data.open
# 2. 收盘价减去开盘价
data['m_price_change'] = close.sub(open)
data.head()
逻辑运算
1.逻辑运算符号 < 、>、 |、 &
- 例如筛选p_change > 2 的日期数据
- data['p_change'] > 2 返回逻辑结果
data["p_change"] > 2
# 输出
2021-06-01 True
2021-06-02 False
2021-06-03 True
2021-06-04 True
2021-06-07 True
2021-06-08 True
2021-06-09 False
2021-06-10 True
# 获取p_change 大于二 且 open 小于 12的 结果
(data["p_change"] > 2) & (data["open"] < 12)
# 利用布尔索引获取
data[(data["p_change"] > 2) & (data["open"] < 12)]
逻辑运算函数
- query(expr)
-
expr:查询字符串
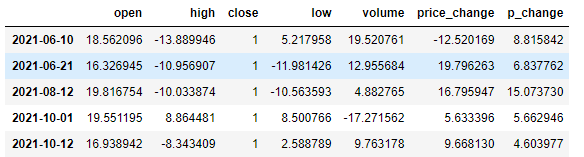
data.query("p_change > 2 & open > 15" ).head()
输出:
- isin(values)
- 例如判断“close” 是否为-8.343409,8.864481
data[data["open"].isin( [-10.243635090215308,-12.40666134379941])]

统计运算
1.describe()
综合分析:能够直接得出很多统计结果,count、mean、stf、min、max、等
# 计算平均值、标准差、最大值、最小值
data.describe()

2.统计函数
- max() min()
- std() var() 方差、标准差
- median()
- idxmax() idxmin() 求最大值、最小值位置 (对应numpy中的argmax()、 argmin())
累计统计函数

# 观察p_change的累加走势情况
data.p_change.sort_index().cumsum().plot()

自定义运算
- apply(func, axis=0)
-
func:自定义函数 -
axis=0:默认是列,axis=1为进行行运算
例如计算最大值最小值之差:
# 计算最大值最小值之差
data.apply(lambda x: x.max() -x.min(), )
四、pandas画图
pandas.DataFrame.plot()
DataFrame.plot (x=None, y=None, kind='line')
x : label or position,default None
y : label, position or list of label, positions, default None
- Allows plotting of one column versus another
kind : str
- ‘line’: line plot (default)
- "bar": vertical bar plot
- "barh" : horizontal bar plot
- "hist” : histogram
- ‘pie': pie plot
- 'scatter" : scatter plot
data.plot(x="volume", y= "open", kind="scatter")

文件的读取与存储
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的Api支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5
总结
本文主要介绍了索引操作、复制与排序、DataFrame的运算和pandas画图。
