
1、概念
哈希之所以广泛存在,是因为它能在绝大多数情况下可以在O(1)的时间复杂度中完成元素的查找。它的核心是数组,如果输入是一个自然数,那么当然可以在常数时间内搜索到自然数所对应的数组元素了。但在工程实践中,要查找的关键字往往都不是自然数,即使是自然数也有可能是很大的值。因此,只要我们提前把关键字转换为在固定较小范围内的自然数,就可以实现常数时间的查找。那么问题来了,如何实现该转换关系呢?这就是哈希函数所要完成的工作。
哈希函数:又称散列函数,是把一段有限二进制串(字符串,整数等)转换为自然数的一种函数。
哈希值:哈希函数输出的最终结果。
字符串哈希函数:输入是字符串的哈希函数。
既然是函数,就有可能出现多对一的情况(多个输入对应同一个哈希值),这种情况称为冲突。没有冲突的哈希函数称为完全哈希函数,但这种函数只在理论分析中出现。为了保证每一个元素对应不同的存储地址,可使用以下两类方法:
链接法:数组元素存储指向链表的指针,链表的每个元素都可以存储一个输入的元素。
开放地址法:所有的元素都存放在散列表中,它不用指针,是计算出要存取的槽序列。
使用哈希函数得到哈希值只是Hash算法的第一步,此外一般还需要进行高位运算和取模运算。
2、常见方法
评价hash函数性能的一个重要指标就是冲突,在相关资源允许的条件下冲突越少hash函数的性能越好。显然,对于字符串哈希函数,尽可能使每个字符都影响哈希值可以减少冲突。目前常见的字符串hash算法有BKDRHash,APHash,DJBHash,
JSHash,RSHash,SDBMHash,PJWHash,ELFHash等等。
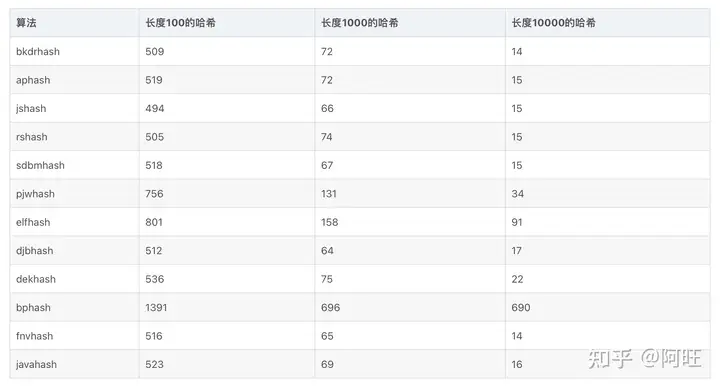
其中数据1为100000个字母和数字组成的随机串哈希冲突个数。数据2为100000个有意义的英文句子哈希冲突个数。数据3为数据1的哈希值与 1000003(大素数)求模后存储到线性表中冲突的个数。数据4为数据1的哈希值与10000019(更大素数)求模后存储到线性表中冲突的个数。
经过比较,得出以上平均得分。平均数为平方平均数。可以发现,BKDRHash无论是在实际效果还是编码实现中,效果都是最突出的。APHash也是较为优秀的算法。DJBHash,JSHash,RSHash与SDBMHash各有千秋。PJWHash与ELFHash效果最差,但得分相似,其算法本质是相似的。
3、实现原理和常用算法
所有的字符串哈希算法都是基于对字符编码的迭代运算,只是运算规则不同而已。
1)BKDRHash算法
BKDRHash是Kernighan和Dennis在《The C programming language》中提出的。
// BKDR Hash Function
unsigned int BKDRHash(char *str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313 etc..
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
2)APHash算法
Arash Partow提出了这个算法,声称具有很好地分布性。
// AP Hash Function
unsigned int APHash(char *str)
{
unsigned int hash = 0;
int i;
for (i=0; *str; i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (*str++) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (*str++) ^ (hash >> 5)));
}
}
return (hash & 0x7FFFFFFF);
}
3)DJBHash算法
Daniel J. Bernstein在comp.lang.c邮件列表中发表的,是距今为止比较高效的哈希函数之一。
// DJB Hash Function
unsigned int DJBHash(char *str)
{
unsigned int hash = 5381;
while (*str)
{
hash += (hash << 5) + (*str++);
}
return (hash & 0x7FFFFFFF);
}
4)JSHash算法
Justin Sobel提出的基于位的函数函数。
// JS Hash Function
unsigned int JSHash(char *str)
{
unsigned int hash = 1315423911;
while (*str)
{
hash ^= ((hash << 5) + (*str++) + (hash >> 2));
}
return (hash & 0x7FFFFFFF);
}
5)RSHash算法
其作者是Robert Sedgwicks。实现如下:
// RS Hash Function
unsigned int RSHash(char *str)
{
unsigned int b = 378551;
unsigned int a = 63689;
unsigned int hash = 0;
while (*str)
{
hash = hash * a + (*str++);
a *= b;
}
return (hash & 0x7FFFFFFF);
}
6)SDBMHash算法
SDBM项目使用的哈希函数,声称对所有的数据集有很好地分布性。
unsigned int SDBMHash(char *str)
{
unsigned int hash = 0;
while (*str)
{
// equivalent to: hash = 65599*hash + (*str++);
hash = (*str++) + (hash << 6) + (hash << 16) - hash;
}
return (hash & 0x7FFFFFFF);
}
7)PJWHash算法
Peter J. Weinberger在其编译器著作中提出的。
// P. J. Weinberger Hash Function
unsigned int PJWHash(char *str)
{
unsigned int BitsInUnignedInt = (unsigned int)(sizeof(unsigned int) * 8);
unsigned int ThreeQuarters = (unsigned int)((BitsInUnignedInt * 3) / 4);
unsigned int OneEighth = (unsigned int)(BitsInUnignedInt / 8);
unsigned int HighBits = (unsigned int)(0xFFFFFFFF) << (BitsInUnignedInt - OneEighth);
unsigned int hash = 0;
unsigned int test = 0;
while (*str)
{
hash = (hash << OneEighth) + (*str++);
if ((test = hash & HighBits) != 0)
{
hash = ((hash ^ (test >> ThreeQuarters)) & (~HighBits));
}
}
return (hash & 0x7FFFFFFF);
}
8)ELFHash算法
Unix系统上面广泛使用的哈希函数。
// ELF Hash Function
unsigned int ELFHash(char *str)
{
unsigned int hash = 0;
unsigned int x = 0;
while (*str)
{
hash = (hash << 4) + (*str++);
if ((x = hash & 0xF0000000L) != 0)
{
hash ^= (x >> 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF);
}
9)DEKHash算法
Donald E. Knuth在《计算机程序设计的艺术》中提出的哈希函数。
public static int dekhash(String str) {
int hash = str.length();
for (int i = 0; i < str.length(); i++) {
hash = (hash << 5) ^ (hash >> 27) ^ (int)str.charAt(i);
}
return hash & 0x7FFFFFFF;
}
10)BPHash算法
public static int bphash(String str) {
int hash = str.length();
for (int i = 0; i < str.length(); i++) {
hash = (hash << 7) ^ (int)str.charAt(i);
}
return hash & 0x7FFFFFFF;
}
11)FNVHash算法
public static int fnvhash(String str) {
int fnvprime = 0x811C9DC5;
int hash = 0;
for (int i = 0; i < str.length(); i++) {
hash *= fnvprime;
hash ^= (int)str.charAt(i);
}
return hash & 0x7FFFFFFF;
}
12)Java String Hashcode算法
这是Java的字符串类的Hash算法,简单实用高效。
public static int javahash(String str) {
int hash = 0;
for (int i = 0; i < str.length(); i++) {
hash = hash * 31 + (int)str.charAt(i);
}
return hash & 0x7FFFFFFF;
} 
 浙公网安备 33010602011771号
浙公网安备 33010602011771号