
设计模式20150602
1、代码规范
命名、异常情况、
2、面向对象
封装、继承、多态;
继承:成为子类的模板,所有重复的代码都应该要上升到父类中,而不是让每个子类都去重复;
3、易维护、可复用、可扩展
容易修改、易于复用、
4、不能避免重复,--不能拷贝、复制,而是复用-------简单的复制黏贴极有可能造成代码的灾难。
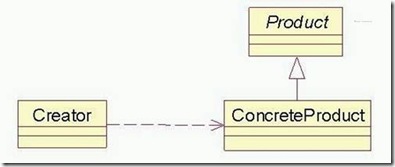
5、容易变化的地方(如添加新的运算符时),应该考虑用一个单独的类来做这个创造实例的过程。--工厂。
6.方法过长极有可能是坏味道。Long Method.即方法的责任过大、还是类的责任过大?
7.面向对象设计其实就是希望做到代码的责任分解。
什么时候需要重构?
分支如switch,重复的代码较多时,除了一点点差别之外就几乎相同时,需考虑重构。(可以把分支变成一个个独立的类,增加时不会影响其他类。然后状态的变化在各自的类中完成。-----状态模式)
5.2、类的划分是为了封装,但分类的基础是抽象,具有相同属性和功能的对象的抽象集合才是类!
如:可把打折算法抽取出来。可打折算法经常变,----算法本身只是一种策略,最重要的是这些算法是随时都可能互相替代的,这就是变化点,而封装变化点是面向对象的一种很重要的思维方式。
6、
6.1简单工厂

-算法本身只是一种策略,最重要的是这些算法是随时都可能互相替代的,这就是变化点,而封装变化点是面向对象的一种很重要的思维方式。--策略模式
--6.2策略模式Strategy
如何让算法和对象分开来,使得算法可以独立于使用它的客户而变化?
定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。

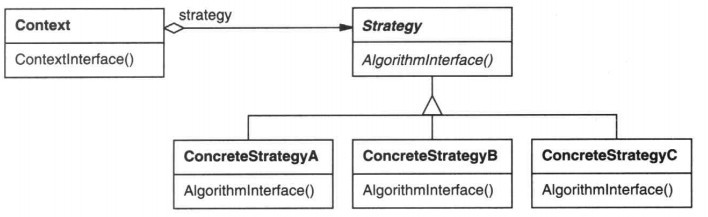
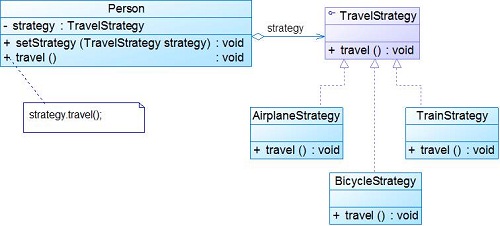
实际整个Strategy的核心部分就是抽象类的使用,使用Strategy模式可以在用户需要变化时,修改量很少,而且快速.
Strategy和Factory有一定的类似,Strategy相对简单容易理解,并且可以在运行时刻自由切换。Factory重点是用来创建对象。
Strategy适合下列场合:
1.以不同的格式保存文件;
2.以不同的算法压缩文件;
3.以不同的算法截获图象;
4.以不同的格式输出同样数据的图形,比如曲线 或框图bar等
解决了每次变换算法时都要修改工厂的弊端,可导致判断过程放到了客户端。
解决方式:
策略模式与简单工厂的结合,将判断过程switch,放在Context中。
再者,客户端只需要认识Context,CashContext,即可。
用途:
在不同时间应用不同的业务规则时,变化频繁时。
当不同的行为堆砌在一个类中,就很难避免使用条件语句来选择合适的行为。将这些行为封装在一个个独立的Strategy中,可在使用这些行为的类中消除条件语句。
不足之处:
在CashContext中还是用到了switch,----反射技术。抽象工厂模式
6.3、装饰模式
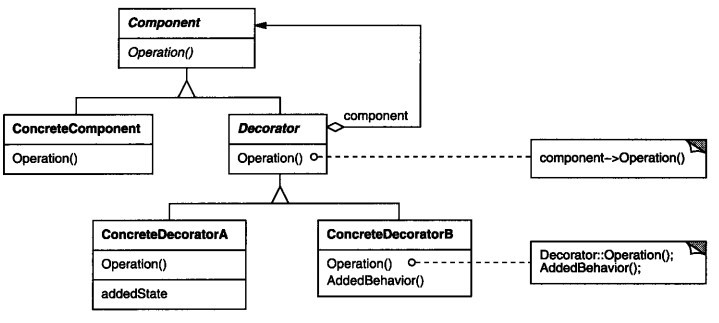
1. 概述
若你从事过面向对象开发,实现给一个类或对象增加行为,使用继承机制,这是所有面向对象语言的一个基本特性。如果已经存在的一个类缺少某些方法,或者须要给方法添加更多的功能(魅力),你也许会仅仅继承这个类来产生一个新类—这建立在额外的代码上。
通过继承一个现有类可以使得子类在拥有自身方法的同时还拥有父类的方法。但是这种方法是静态的,用户不能控制增加行为的方式和时机。如果 你希望改变一个已经初始化的对象的行为,你怎么办?或者,你希望继承许多类的行为,改怎么办?前一个,只能在于运行时完成,后者显然时可能的,但是可能会导致产生大量的不同的类—可怕的事情。
2. 问题
你如何组织你的代码使其可以容易的添加基本的或者一些很少用到的 特性,而不是直接不额外的代码写在你的类的内部?
3. 解决方案
装饰器模式: 动态地给一个对象添加一些额外的职责或者行为。就增加功能来说, Decorator模式相比生成子类更为灵活。
装饰器模式提供了改变子类的灵活方案。装饰器模式在不必改变原类文件和使用继承的情况下,动态的扩展一个对象的功能。它是通过创建一个包装对象,也就是装饰来包裹真实的对象。
当用于一组子类时,装饰器模式更加有用。如果你拥有一族子类(从一个父类派生而来),你需要在与子类独立使用情况下添加额外的特性,你可以使用装饰器模式,以避免代码重复和具体子类数量的增加。
-
在不影响其他对象的前提下,以动态、透明的方式给单个对象添加职责。
-
处理那些可以撤消的职责。
-
当不能采用生成子类的方法进行扩充时。一种情况是,可能有大量独立的扩展,为支持每一种组合将产生大量的子类,使得子类数目呈爆炸性增长。另一种情况可能是因为类定义被隐藏,或类定义不能用于生成子类。
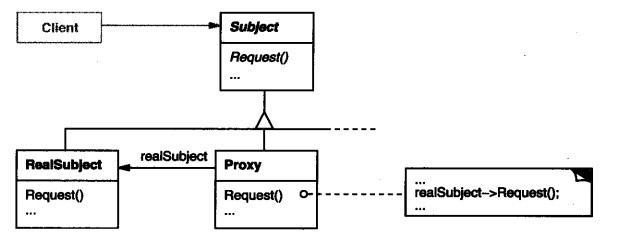
6.4、代理模式
代理人和被代理人有同样的行为;被代理人不认识目标。目标使用代理,就好像使用被代理人一样。
定义:
为其他对象提供一种代理以控制对这个对象的访问。
问题:
你怎样才能在不直接操作对象的情况下,对此对象进行访问?
-
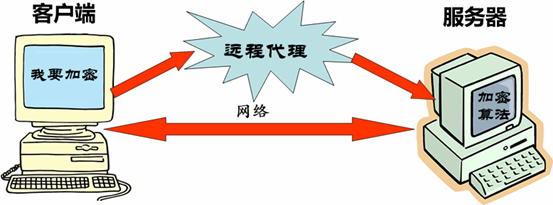
远程代理(Remote Proxy)为一个对象在不同的地址空间提供局部代表。
-
虚代理(Virtual Proxy)根据需要创建开销很大的对象。
-
保护代理(Protection Proxy)控制对原始对象的访问。保护代理用于对象应该有不同 的访问权限的时候。
-
智能指引(Smart Reference)取代了简单的指针,它在访问对象时执行一些附加操作。 它的典型用途包括:
-
对指向实际对象的引用计数,这样当该对象没有引用时,可以自动释放它(也称为SmartPointers)。
-
当第一次引用一个持久对象时,将它装入内存。
-
在访问一个实际对象前,检查是否已经锁定了它,以确保其他对象不能改变它
7.工厂模式(reference)
简单工厂具有生产这种新产品的能力,如何实现?你自然会想到多添一条case语句不就完了?然而事情并没有那么简单,因为你在添加case语句的同时也就意味着你修改了工厂类本身—违反了设计原则中最重要的一条OCP原则。开放封闭原则要求避免直接修改类而是应当通过继承来扩展类的功能。此外过多的case语句也容易混乱逻辑,造成工厂类的稳定性下降。那么对于新产品的增加,怎样才能妥善的处理并且又不违反设计原则呢?于是—工厂方法(Factory Method)登场了。
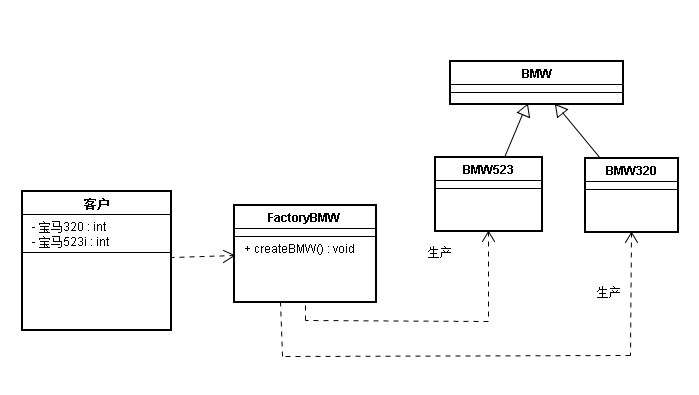


工厂方法(Factory Method)仍然有值得商榷的地方:
首先,逻辑相对复杂,不易使用。是否每个人都可以随意的在项目中熟练的运用工厂方法模式呢?
其次,可以看到在每增加一种新产品类型的时候,我们都需要多添加一个生产该产品的工厂,这便带来了业务需求之外的工作量。
新的解决方案
借助第三节中所提到的反射机制的运用,我思考着能否将反射机制与简单工厂相结合,仍然借助简单工厂的设计模式,而将其对产品的判断逻辑由原先的代码改为反射配置文件。
-
当一个类不知道它所必须创建的对象的类的时候。
-
当一个类希望由它的子类来指定它所创建的对象的时候。
-
当类将创建对象的职责委托给多个帮助子类中的某一个,并且你希望将哪一个帮助子类是代理者这一信息局部化的时候。
工厂的使用,选择的过程
工厂模式的使用,实际上是客户(产品的消费者)对于产品选择的过程,对于实现了相同功能的产品来讲,客户更加关心的是产品间的差异性,而工厂的作用则是将产品的生产过程封装,根据客户的要求直接返回客户需要的产品。注意,工厂只是隐藏了产品的生产过程,但是并没有剥夺客户选择的权利,那么客户的这个选择过程又是如何体现的呢?在简单工厂中,客户通过参数的形式告诉工厂需要什么样的产品,而在工厂方法中,客户通过对工厂的选择代替了直接对产品的选择,注意到工厂方法中一个工厂只有一个Create方法,也就是说一个工厂只负责生产一种产品,那么你选择了相应的工厂也就等同于你选择了对应的产品。就连改良后的反射工厂也没有消去对产品的选择,只不过是将这种选择外化(外化到配置文件中,从而使得对代码的改动最小)。可以说,正是由于产品间的差异性带给了客户选择的权利,这种权利是不应当被工厂取代的,那么工厂模式的价值又在哪里呢?答案是抽象与封装,工厂模式将由于客户的不同选择而可能导致的对已知事物的影响降到最低,途径是通过抽象产品取代具体产品,使得客户依赖于抽象(越抽象的东西越稳定),同时将客户的选择封装到一处,隔离与具体产品间的依赖。
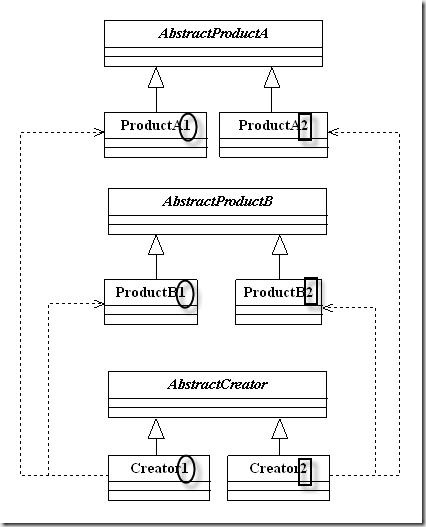
9.抽象工厂(reference)



-
一个系统要独立于它的产品的创建、组合和表示时。
-
一个系统要由多个产品系列中的一个来配置时。
-
当你要强调一系列相关的产品对象的设计以便进行联合使用时。
-
当你提供一个产品类库,而只想显示它们的接口而不是实现时。
相比工厂模式,抽象工厂模式是一个工厂负责多个对象的创建,返回
的具体的类型是这个对象的抽象类型。
9.3.1 抽象工厂模式的优点
- 封装性,每个产品的实现类不是高层模块要关系的,要关心的是什么?是接口,是抽象,它不关心对象是如何创建出来,这由谁负责呢?工厂类,只要知道工厂类是谁,我就能创建出一个需要的对象,省时省力,优秀设计就应该如此。
- 产品族内的约束为非公开状态。例如生产男女比例的问题上,猜想女娲娘娘肯定有自己的打算,不能让女盛男衰,否则女性的优点不就体现不出来了吗?那在抽象工厂模式,就应该有这样的一个约束:每生产1个女性,就同时生产出1.2个男性,这样的生产过程对调用工厂类的高层模块来说是透明的,它不需要知道这个约束,我就是要一个黄色女性产品就可以了,具体的产品族内的约束是在工厂内实现的。
9.3.2 抽象工厂模式的缺点
抽象工厂模式的最大缺点就是产品族扩展非常困难,为什么这么说呢?我们以通用代码为例,如果要增加一个产品C,也就是说有产品家族由原来的2个,增加到3个,看看我们的程序有多大改动吧!抽象类AbstractCreator要增加一个方法createProductC(),然后,两个实现类都要修改,想想看,这在项目中的话,还这么让人活!严重违反了开闭原则,而且我们一直说明抽象类和接口是一个契约,改变契约,所有与契约有关系的代码都要修改,这段代码叫什么?叫“有毒代码”,——只要这段代码有关系,就可能产生侵害的危险!
9.3.3 抽象工厂模式的使用场景
抽象工厂模式的使用场景定义非常简单:一个对象族(或是一组没有任何关系的对象)都有相同的约束,则可以使用抽象工厂模式,什么意思呢?例如一个文本编辑器和一个图片处理器,都是软件实体,但是*nix下的文本编辑器和WINDOWS下的文本编辑器虽然功能和界面都相同,但是代码实现是不同的,图片处理器也是类似情况,也就是具有了共同的约束条件:操作系统类型,于是我们可以使用抽象工厂模式,产生不同操作系统下的编辑器和图片处理器。
9.3.3.4 抽象工厂模式的注意实现
在抽象工厂模式的缺点中,我们提到抽象工厂模式的产品族扩展比较困难,但是一定要清楚是产品族扩展困难,而不是产品等级,在该模式下,产品等级是非常容易扩展的,增加一个产品等级,只要增加一个工厂类负责新增加出来的产品生产任务即可,也就是说横向扩展容易,纵向扩展困难。以人类为例子, 产品等级中只要男、女两个性别,现实世界还有一种性别:双性人,即使男人也是女人(俗语就是阴阳人),那我们要扩展这个产品等级也是非常容易的,增加三个产品类,分别对应不同的肤色,然后再创建一个工厂类,专门负责不同肤色人的双性人的创建任务,完全通过扩展来实现的需求的变更,从这一点上看,抽象工厂模式是符合开闭原则的。
工厂方法与抽象工厂的区别reference
从图中我们能够看到哪些差异?
最明显的一点就是在工厂方法的类关系图中只有一类产品,他们实现了一个统一的接口,而抽象工厂有多个类别的产品,他们分别实现了不同的功能(多个接口)。其次的一点差别就是工厂本身所具有的方法数量不同,这点差异其实也是由第一点所导致的,工厂需要有生产不同类别产品的功能,如果抽象工厂中的产品的功能简化到一个,也便成为了工厂方法。
引出类别的概念,类别是指具有相同功能的一类产品的总称。
再来看选择的过程,在工厂方法中,客户关心的只不过是实现同一样功能的不同产品间的差异,这是一个一维选择的过程。
2 IProduct productA = factory.Create(); //工厂只有一个Create方法,只能生产一种产品
而在抽象工厂中,客户首先要考虑的是需要哪一样功能,其次要考虑才是产品间的差异。也就是说这是一个二维选择的过程。
2 IProduct productA = factory.CreateProductA(); //工厂具有多个Create方法,这里选择了其中的一个
由于产品类别的增加而导致客户在考虑产品间差异的同时还要考虑产品间功能的差异,这种二维选择的过程才是工厂方法与抽象工厂之间的本质区别。
举个肯德基与麦当劳的例子,假设原来只有一家快餐店叫做麦当劳,提供的食物(具体产品)有汉堡、可乐、薯条,它们都可以满足你吃东西(抽象接口)的需求,那么你想吃快餐的时候,唯一的选择就在于吃什么,是一维选择,现在又开了一家快餐店叫做肯德基,同样供应汉堡、可乐和薯条,那么现在你若打算吃快餐,除了考虑吃什么外,还要考虑去哪里吃--肯德基还是麦当劳?这便是二维的选择。通过横向与纵向的选择才能最终锁定你要的产品。
抽象工厂的改进:
1.增加一个类,去掉工厂类,只保留产品类和新增的类A,在A中判断具体要实例化哪一个产品;可是A中却出现了很多的case,----反射+抽象工厂+配置文档,在A中使用反射,去掉case,使用配置文档来配置具体的产品。
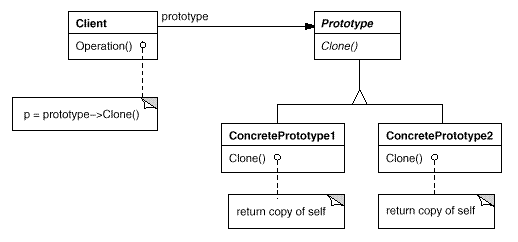
10.原型模式

-
当要实例化的类是在运行时刻指定时,例如,通过动态装载;或者
-
为了避免创建一个与产品类层次平行的工厂类层次时;或者
-
当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些
适合场合:
一般在初始化的信息不发生变化的情况下,克隆是最好的办法,既隐藏了对象创建的细节,不用重新初始化对象,而是动态地获得对象运行时的状态。
该模式的思想就是将一个对象作为原型,对其进行复制、克隆,产生一个和原对象类似的新对象。本小结会通过对象的复制,进行讲解。在Java中,复制对象是通过clone()实现的,先创建一个原型类:
public class Prototype implements Cloneable { public Object clone() throws CloneNotSupportedException { Prototype proto = (Prototype) super.clone(); return proto; } }
一个原型类,只需要实现Cloneable接口,覆写clone方法,此处clone方法可以改成任意的名称,因为Cloneable接口是个空接口,你可以任意定义实现类的方法名,如cloneA或者cloneB,因为此处的重点是super.clone()这句话,super.clone()调用的是Object的clone()方法,而在Object类中,clone()是native的。
对象深、浅复制的概念:
浅复制:将一个对象复制后,基本数据类型的变量都会重新创建,而引用类型,指向的还是原对象所指向的。(创建一个新对象,将当前对象的非静态字段复制到该新对象。若字段是值类型的,则对该字段执行逐位复制;若字段是引用类型,则复制引用但不复制引用的对象)
深复制:将一个对象复制后,不论是基本数据类型还有引用类型,都是重新创建的。简单来说,就是深复制进行了完全彻底的复制,而浅复制不彻底。
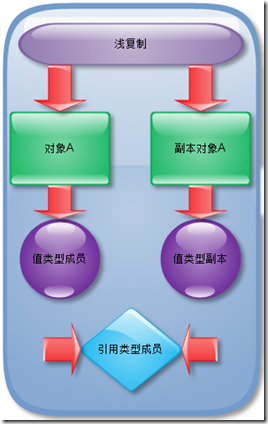
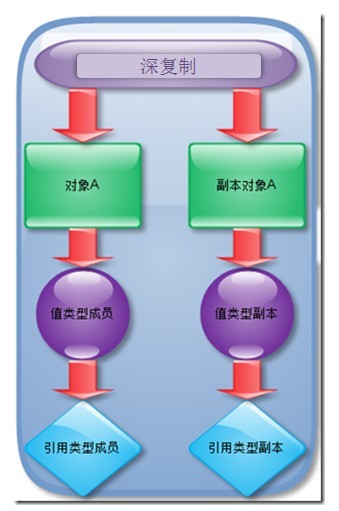
深复制到多少层?需要事先考虑好。
public class Prototype implements Cloneable, Serializable {
private static final long serialVersionUID = 1L;
private String string;
private SerializableObject obj;
/* 浅复制 */
public Object clone() throws CloneNotSupportedException {
Prototype proto = (Prototype) super.clone();
return proto;
}
/* 深复制 */
public Object deepClone() throws IOException, ClassNotFoundException {
/* 写入当前对象的二进制流 */
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
/* 读出二进制流产生的新对象 */
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return ois.readObject();
}
public String getString() {
return string;
}
public void setString(String string) {
this.string = string;
}
public SerializableObject getObj() {
return obj;
}
public void setObj(SerializableObject obj) {
this.obj = obj;
}
}
class SerializableObject implements Serializable {
private static final long serialVersionUID = 1L;
}
要实现深复制,需要采用流的形式读入当前对象的二进制输入,再写出二进制数据对应的对象。
带Prototype Manager的原型模式
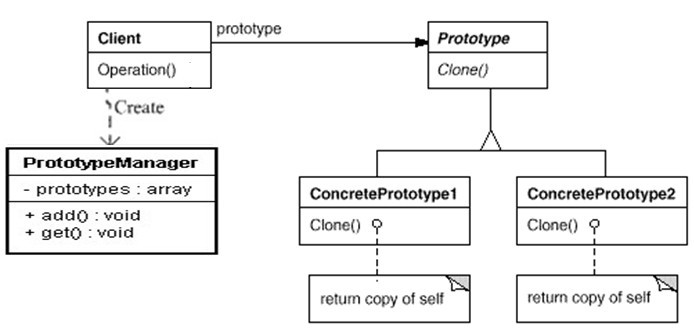
11.模板模式
问题:
如何保证架构逻辑的正常执行,而不被子类破坏 ?
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。Te m p l a t e M e t h o d 使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
当我们要完成在某一细节层次一致的一个过程或一系列步骤,但其个别步骤在更详细的层次(子类)上的实现可能不同时,我们通常考虑用模板方法模式来处理。
定义一些步骤,将一些子活动延迟到子类实现。
12.外观模式(基金的例子,将投资者分散的资金集中起来,交由专业的经理人进行管理,投资于股票、债券、外汇等领域,而基金的收益归投资者所有,管理机构收取一定比例的托管管理费用)
由于众多投资者众多国的联系太多,反而不利于操作,联系太多过于凌乱,即耦合性过高。
问题:
为了降低复杂性,常常将系统划分为若干个子系统。但是如何做到各个系统之间的通信和相互依赖关系达到最小呢?
定义:
为子系统中的一组接口提供一个一致的界面,Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。


如果我们没有Computer类,那么,CPU、Memory、Disk他们之间将会相互持有实例,产生关系,这样会造成严重的依赖,修改一个类,可能会带来其他类的修改,这不是我们想要看到的,有了Computer类,他们之间的关系被放在了Computer类里,这样就起到了解耦的作用,这,就是外观模式!
computer类,外观类,知道那些子系统类负责处理请求,将客户的请求代理给适当的子系统对象;
SubSystem Classes实现子系统的功能,处理外观类对象指派的任务。子系统类没有Facade的任何信息,即没有对Facade对象的引用。
何时使用外观模式?
1.在设计初期
应该要有意识地将不同的两个层分离,比如MVC,在层与层之间建立外观Facade.
2.在开发阶段:
为内部复杂的部件(包)提供一个外观,便于外部调用。
3.维护一个系统时
为新系统开发一个Facade类,facade与原有交互,新系统与facade交互。
13.建造者模式(好菜每回味道不同,麦当劳)

意图:
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
理解:
若没指挥者类,建造者可退化为模板模式;指挥者类与Director类是组合关系;此模式主要是用于创建一些复杂的对象,这些对象内部构建间的建造顺序通常是稳定的,但对象内部的构建通常面临复杂的变化;
此模式使得建造代码与表示代码分(将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示时),由于建造者隐藏了该产品是如何组装的,所以若需要改变一个产品的内部表示,只需要再定义一个具体的建造者即可。
适用性:
当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时。
当构造过程必须允许被构造的对象有不同的表示时。
例子:
建造小人;
#include <iostream>
#include <vector>
#include <string>
using namespace std;
//Product类
class Product
{
vector<string> parts;
public:
void Add(const string part)
{
parts.push_back(part);
}
void Show()const
{
for(int i = 0 ; i < parts.size() ; i++)
{
cout<<parts[i]<<endl;
}
}
};
//抽象builder类
class Builder
{
public:
virtual void BuildHead() = 0;
virtual void BuildBody() = 0;
virtual void BuildHand() = 0;
virtual void BuildFeet() = 0;
virtual Product GetResult() = 0;
};
//具体胖人创建类
class FatPersonBuilder :public Builder
{
private:
Product product;
public:
virtual void BuildHead()
{
product.Add("胖人头");//创建瘦人的头
}
virtual void BuildBody()
{
product.Add("胖人身体");//创建瘦人的身体
}
virtual void BuildHand()
{
product.Add("胖人手");//创建瘦人的手
}
virtual void BuildFeet()
{
product.Add("胖人脚");//创建瘦人的脚
}
virtual Product GetResult()
{
return product;
}
};
//具体瘦人人创建类
class ThinPersonBuilder :public Builder
{
private:
Product product;
public:
virtual void BuildHead()
{
product.Add("瘦人人头");//创建瘦人的头
}
virtual void BuildBody()
{
product.Add("瘦人身体");//创建瘦人的身体
}
virtual void BuildHand()
{
product.Add("瘦人手");//创建瘦人的手
}
virtual void BuildFeet()
{
product.Add("瘦人脚");//创建瘦人的脚
}
virtual Product GetResult()
{
return product;
}
};
//Director类
class Director
{
public:
void Construct(Builder &builder)
{
builder.BuildHead();
builder.BuildBody();
builder.BuildHand();
builder.BuildFeet();
}
};
int main()
{
Director *director = new Director();
Builder *b1 = new FatPersonBuilder();
Builder *b2 = new ThinPersonBuilder();
director->Construct(*b1);
Product p1 = b1->GetResult();
p1.Show();
return 0;
}
14.观察者模式,(观察者与通知者的关系)reference reference2


定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时, 所有依赖于它的对象都得到通知并被自动更新。(观察者不一定要使用抽象类,而是要使用接口)
-
当一个抽象模型有两个方面, 其中一个方面依赖于另一方面。将这二者封装在独立的对象中以使它们可以各自独立地改变和复用。
-
当对一个对象的改变需要同时改变其它对象, 而不知道具体有多少对象有待改变。
-
当一个对象必须通知其它对象,而它又不能假定其它对象是谁。换言之,你不希望这些对象是紧密耦合的。
我们再来对上面的观察者模式进行分析,可以发现,这种实现是有不足之处的:
(1)并没有完全的解除系统的耦合。
(2)所有观察者要完成的操作未必是一致的,即:未必都是Update操作,不同的观察者所要完成的事情未必一致。
推模型和拉模型
在观察者模式中,又分为推模型和拉模型两种方式。
● 推模型
主题对象向观察者推送主题的详细信息,不管观察者是否需要,推送的信息通常是主题对象的全部或部分数据。
● 拉模型
主题对象在通知观察者的时候,只传递少量信息。如果观察者需要更具体的信息,由观察者主动到主题对象中获取,相当于是观察者从主题对象中拉数据。一般这种模型的实现中,会把主题对象自身通过update()方法传递给观察者,这样在观察者需要获取数据的时候,就可以通过这个引用来获取了。
引入委托的原因:
1.观察者有可能不会实现同样的接口;(具体的观察者完全有可能是风马牛不相及的类---所以,不用抽象类,而用接口)
2.抽象通知者还是依赖抽象观察者;
3.具体的观察者不一定具有同样的更新方法,update。
若:通知者和观察者之间根本就互相不知道,由客户端来决定通知谁。---委托。
通过上述委托的使用,我们就可以减少原来观察者模式中抽象通知者对抽象观察者的依赖了。这就是委托的好处
它可以减少类之间的依赖,而且使得委托对象所搭载的方法并不属于同一个类(例子中委托对象为看股票的观察者类和看NBA的观察者类)。
当然,在使用委托时,也是有一定的要求的,那就是,委托的对象方法必须具有相同的原型和形式,也就是拥有相同的参数列表和返回值类型(例子中的两个子类对象都具有相同的形式)。
public interface Subject {
public void registerObserver(Observer o);
public void removeObserver(Observer o);
public void notifyAllObservers();
}
public interface Observer {
public void update(Subject s);
}
import java.util.ArrayList;
public class HeadHunter implements Subject{
//define a list of users, such as Mike, Bill, etc.
private ArrayList<Observer> userList;
private ArrayList<String> jobs;
public HeadHunter(){
userList = new ArrayList<Observer>();
jobs = new ArrayList<String>();
}
@Override
public void registerObserver(Observer o) {
userList.add(o);
}
@Override
public void removeObserver(Observer o) {}
@Override
public void notifyAllObservers() {
for(Observer o: userList){
o.update(this);
}
}
public void addJob(String job) {
this.jobs.add(job);
notifyAllObservers();
}
public ArrayList<String> getJobs() {
return jobs;
}
public String toString(){
return jobs.toString();
}
}
public class JobSeeker implements Observer {
private String name;
public JobSeeker(String name){
this.name = name;
}
@Override
public void update(Subject s) {
System.out.println(this.name + " got notified!");
//print job list
System.out.println(s);
}
}
public class Main {
public static void main(String[] args) {
HeadHunter hh = new HeadHunter();
hh.registerObserver(new JobSeeker("Mike"));
hh.registerObserver(new JobSeeker("Chris"));
hh.registerObserver(new JobSeeker("Jeff"));
//每次添加一个个job,所有找工作人都可以得到通知。
hh.addJob("Google Job");
hh.addJob("Yahoo Job");
}
}
似乎看起来挺完美了,但还是不够完美。因为事件被硬编码为被观察者类的属性。这样事件类型在编译时期就被定死了,如果要增加新的事件类型就不得不修改IObservable接口和Observable类,这大大削减了灵活性。
相当于被观察者耦合于这些具体的事件,那么我们如何来打破这个限制呢?
答案是引入一个新的组件,让那个组件来管理事件、观察者、被观察者之间的关系,事件发生时也由那个组件来调用观察者的回调函数。这也是一种解耦吧,有点类似Spring的IOC容器。
至于具体实现,我觉得Guava EventBus做得已经蛮好了,可以参考我前面提到的链接。
http://blog.csdn.net/yanshujun/article/details/6494447
http://zhidao.baidu.com/link?url=FTPPlU7X8pCFqYWoSduy4SWNtViF0xlVKW3TrIM7J6XdzAFoyYIYC1ba-wSYTH_T-P5Bk5DXJ7wAT6VSY5GQYCKYF2OYC86yaXOsVFx1Ira
http://blog.sina.com.cn/s/blog_4080505a0101e56j.html
15.状态模式
允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。

用处:
状态模式主要解决的是当控制一个对象的状态转换的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示不同状态的一系列类当中。可以把复杂的判断逻辑简化。
1.由于所有与状态相关的代码都存在于某个ConcreteState中,所以通过定义新的子类可以很容易的增加新的状态和转换。
2.把状态的转移从客户端中移到各个ConcreteState 中,由它们来定义状态的转移。
16.适配者模式
将一个类的接口转换成另外一个客户希望的接口。Adapter 模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
注:在GoF的设计模式中,对适配器模式讲了两种类型,类适配器模式和对象适配器模式。由于类适配器模式通过多重继承对一个接口与另一个接口进行匹配,而C#、java等语言都不支持多重继承,因而这里只是介绍对象适配器。

适用场景
5.3.1 系统需要使用现有的类,而这些类的接口不符合系统的接口。
5.3.2 想要建立一个可以重用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作。
5.3.3 两个类所做的事情相同或相似,但是具有不同接口的时候。(想使用一个已经存在的类,但如果他的接口,也就是他的方法与你的要求不相同时,也就是在双方都不太容易修改的时候再使用适配器模式适配。)
5.3.4 旧的系统开发的类已经实现了一些功能,但是客户端却只能以另外接口的形式访问,但我们不希望手动更改原有类的时候。
5.3.5 使用第三方组件,组件接口定义和自己定义的不同,不希望修改自己的接口,但是要使用第三方组件接口的功能。
17.备忘录模式
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外(另外一个对象中)保存这个状态。这样以后就可将该对象恢复到保存的状态.

其实我觉得这个模式叫“备份-恢复”模式最形象。
Memento模式的缺点是耗费大,如果内部状态很多,再保存一份,无意要浪费大量内存.
命令comment模式也有类似撤销功能,在实现命令的撤销功能,那么命令模式可以使用memento模式来存储可撤销操作的状态。
18.命令模式Command,行为封装的代表模式。

将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可取消的操作。
‘行为请求者 ’与‘行为实现者’的解耦。若是对请求排队
http://www.cnblogs.com/wangjq/archive/2012/07/11/2585930.html
http://www.cnblogs.com/lzhp/p/3395320.html
优点:
解耦了发送者和接受者之间联系。 发送者调用一个操作,接受者接受请求执行相应的动作,因为使用Command模式解耦,发送者无需知道接受者任何接口。
不少Command模式的代码都是针对图形界面的,它实际就是菜单命令,我们在一个下拉菜单选择一个命令时,然后会执行一些动作.
将这些命令封装成在一个类中,然后用户(调用者)再对这个类进行操作,这就是Command模式,换句话说,本来用户(调用者)是直接调用这些命令的,如菜单上打开文档(调用者),就直接指向打开文档的代码,使用Command模式,就是在这两者之间增加一个中间者,将这种直接关系拗断,同时两者之间都隔离,基本没有关系了.
显然这样做的好处是符合封装的特性,降低耦合度,Command是将对行为进行封装的典型模式,Factory是将创建进行封装的模式,
从Command模式,我也发现设计模式一个"通病":好象喜欢将简单的问题复杂化, 喜欢在不同类中增加第三者,当然这样做有利于代码的健壮性 可维护性 还有复用性.
如何使用?
具体的Command模式代码各式各样,因为如何封装命令,不同系统,有不同的做法.下面事例是将命令封装在一个Collection的List中,任何对象一旦加入List中,实际上装入了一个封闭的黑盒中,对象的特性消失了,只有取出时,才有可能模糊的分辨出:
典型的Command模式需要有一个接口.接口中有一个统一的方法,这就是"将命令/请求封装为对象":
| public interface Command { public abstract void execute ( ); } |
具体不同命令/请求代码是实现接口Command,下面有三个具体命令
| public class Engineer implements Command { public void execute( ) { //do Engineer's command } } public class Programmer implements Command { public class Politician implements Command { |
按照通常做法,我们就可以直接调用这三个Command,但是使用Command模式,我们要将他们封装起来,扔到黑盒子List里去:
|
public class producer{ }
|
这三个命令进入List中后,已经失去了其外表特征,以后再取出,也可能无法分辨出谁是Engineer 谁是Programmer了,看下面客户端如何调用Command模式:
|
public class TestCommand { } |
由此可见,调用者基本只和接口打交道,不合具体实现交互,这也体现了一个原则,面向接口编程,这样,以后增加第四个具体命令时,就不必修改调用者TestCommand中的代码了.
理解了上面的代码的核心原理,在使用中,就应该各人有自己方法了,特别是在如何分离调用者和具体命令上,有很多实现方法,上面的代码是使用"从List过一遍"的做法.这种做法只是为了演示.
使用Command模式的一个好理由还因为它能实现Undo功能.每个具体命令都可以记住它刚刚执行的动作,并且在需要时恢复.
19.组合模式(分公司=一部门)
组合模式,将对象组合成树形结构以表示“部分-整体”的层次结构,组合模式使得用户对单个对象和组合对象的使用具有一致性。解决整合与部分可以被一致对待问题。
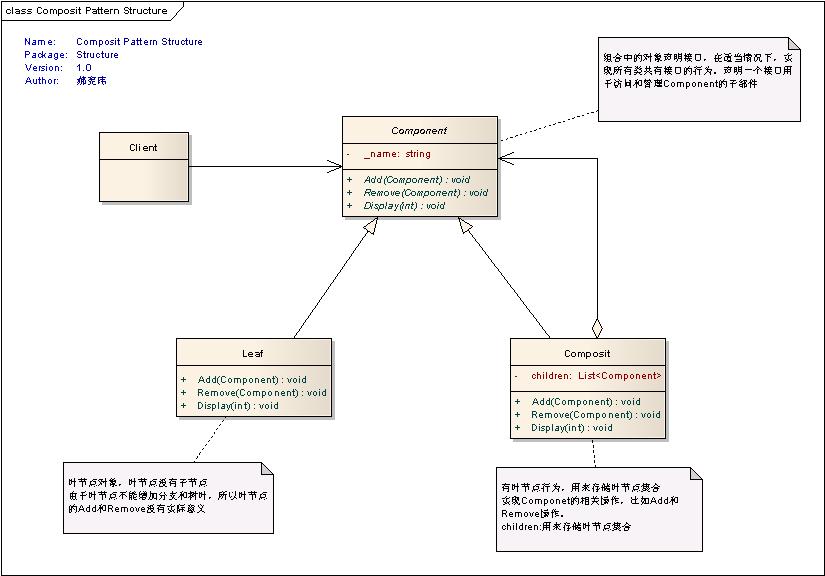
Component类:组合中的对象声明接口,在适当情况下,实现所有类共有接口的行为。声明一个接口用于访问和管理Component的子部件
Leaf类:叶节点对象,叶节点没有子节点。由于叶节点不能增加分支和树叶,所以叶节点的Add和Remove没有实际意义。
有叶节点行为,用来存储叶节点集合
Composite类:实现Componet的相关操作,比如Add和Remove操作。
children:用来存储叶节点集合
http://blog.csdn.net/xsxxxsxx/article/details/7218221
想到Composite就应该想到树形结构图。组合体内这些对象都有共同接口,当组合体一个对象的方法被调用执行时,Composite将遍历(Iterator)整个树形结构,寻找同样包含这个方法的对象并实现调用执行。可以用牵一动百来形容。
所以Composite模式使用到Iterator模式,和Chain of Responsibility模式类似。
想到Composite就应该想到树形结构图。组合体内这些对象都有共同接口,当组合体一个对象的方法被调用执行时,Composite将遍历(Iterator)整个树形结构,寻找同样包含这个方法的对象并实现调用执行。可以用牵一动百来形容。
所以Composite模式使用到Iterator模式,和Chain of Responsibility模式类似。
想到Composite就应该想到树形结构图。组合体内这些对象都有共同接口,当组合体一个对象的方法被调用执行时,Composite将遍历(Iterator)整个树形结构,寻找同样包含这个方法的对象并实现调用执行。可以用牵一动百来形容。
所以Composite模式使用到Iterator模式,和Chain of Responsibility模式类似。
Composite好处:想到Composite就应该想到树形结构图。组合体内这些对象都有共同接口,当组合体一个对象的方法被调用执行时,Composite将遍历(Iterator)整个树形结构,寻找同样包含这个方法的对象并实现调用执行。可以用牵一动百来形容。所以Composite模式使用到Iterator模式,和Chain of Responsibility模式类似。
20.责任链模式(加薪非要老总批示)
Chain of Responsibility(CoR) 是用一系列类(classes)试图处理一个请求request,这些类之间是一个松散的耦合,唯一共同点是在他们之间传递request. 也就是说,来了一个请求,A类先处理,如果没有处理,就传递到B类处理,如果没有处理,就传递到C类处理,就这样象一个链条(chain)一样传递下去。
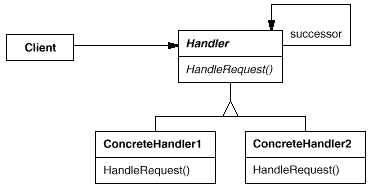
意图:
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
适用性:
有多个的对象可以处理一个请求,哪个对象处理该请求运行时刻自动确定。
你想在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。
可处理一个请求的对象集合应被动态指定。
http://www.jdon.com/designpatterns/cor.htm
http://www.cnblogs.com/beijiguangyong/archive/2010/11/15/2302807.html#_Toc281750461
21.桥接bridge模式
将抽象和行为划分开来,各自独立,但能动态的结合。
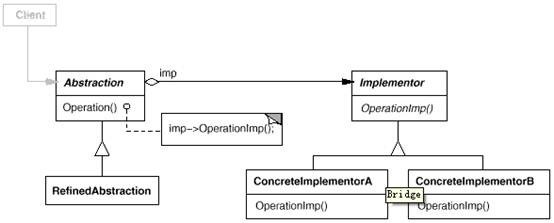
任何事物对象都有抽象和行为之分,例如人,人是一种抽象,人分男人和女人等;人有行为,行为也有各种具体表现,所以,“人”与“人的行为”两个概念也反映了抽象和行为之分。
在面向对象设计的基本概念中,对象这个概念实际是由属性和行为两个部分组成的,属性我们可以认为是一种静止的,是一种抽象,一般情况下,行为是包含在一个对象中,但是,在有的情况下,我们需要将这些行为也进行归类,形成一个总的行为接口,这就是桥模式的用处。
为什么使用?
不希望抽象部分和行为有一种固定的绑定关系,而是应该可以动态联系的。
如果一个抽象类或接口有多个具体实现(子类、concrete subclass),这些子类之间关系可能有以下两种情况:
1. 这多个子类之间概念是并列的,如前面举例,打桩,有两个concrete class:方形桩和圆形桩;这两个形状上的桩是并列的,没有概念上的重复。
2.这多个子类之中有内容概念上重叠.那么需要我们把抽象共同部分和行为共同部分各自独立开来,原来是准备放在一个接口里,现在需要设计两个接口:抽象接口和行为接口,分别放置抽象和行为.
例如,一杯咖啡为例,子类实现类为四个:中杯加奶、大杯加奶、 中杯不加奶、大杯不加奶。
但是,我们注意到:上面四个子类中有概念重叠,可从另外一个角度进行考虑,这四个类实际是两个角色的组合:抽象 和行为,其中抽象为:中杯和大杯;行为为:加奶 不加奶(如加橙汁 加苹果汁).
实现四个子类在抽象和行为之间发生了固定的绑定关系,如果以后动态增加加葡萄汁的行为,就必须再增加两个类:中杯加葡萄汁和大杯加葡萄汁。显然混乱,扩展性极差。
那我们从分离抽象和行为的角度,使用Bridge模式来实现。
手机的分类与软件的统一---使抽象部分和行为有一种固定的绑定关系。使用合成、聚合复用原则。
实现系统可能有多种角度分类,每一种分类都有可能变化,那么就把这种多角度分离出来让它们独立变化,减少它们之间的耦合。
Java:单例模式的七种写法 http://www.blogjava.net/kenzhh/archive/2013/03/15/357824.html
23.中介者模式Meditor
http://blog.csdn.net/chenhuade85/article/details/8141831
24.享元模式Flyweight
http://www.2cto.com/kf/201310/251436.html
http://www.jdon.com/31903
Flyweight的目的是为了减少内存的消耗而出现的一种模式。因此他是一种解决实现问题的模式,而不是用来解决建模问题的。
在文章的例子中说class CD是接口 Flyweight,而class Artist是ConcreteFlyweight。那就完全错了。
按照Flyweight模式,Flyweight和ConcreteFlyweight是继承关系。
而文中却成了聚合关系。
Flyweight模式中,最重要的是将对象分解成extrinsic和intrinsic两部分
在Flyweight Interface中,应该是和context有关的操作,而在例子中,看不到任何和context有关的操作。
可见作者是将flyweight模式和object pool等同起来了。但实际上两者是由本质区别的。object pool中的对象并没有extrinsic,也不知道context的存在。比如最常见的string pool。pool中的string可以用在任何地方。
您的理解完全错误。
1. Flyweight是减少内存的使用量的一种模式,间接的可能会提高性能。两者没有必然联系。
2. Flyweight和Object pool完全不同。FlyWeight内部用到的共享机制在实现上和object cache有点像,但是有本质上的区别。不要把两者混为一谈。请仔细读一下GoF的原著。
3. Flyweight未必会减少实例的创建次数。反而可能会增加实例的创建次数。(尤其对于非JAVA语言)
4. Flyweight内部的共享机制和object pool的区别。
4.1 原理不同
object pool的原理是复用(一个对象被反复使用,但同时只有一个“人”在使用),flyweight的原理是共享(同时被多个“人”使用)。
object pool有一个很重要的特点,那就是pool中的对象是同质的。也就是说,对于使用者来说,可以用pool中的任何一个object。就好像当我们需要connection时可以从connection pool中任意的拿一个出来使用,而Flyweight的每一个实例的内部属性都不同,完全是异质的。flyweight使用时,是去FlyweightFactory中找一个特定的对象出来(如果没有的话,就创建一个)。flyweight的出发点是共享。而object pool中的对象是不能共享的。
4.2 运用的场合不同
object pool对应的场景是对象被频繁创建,使用,然后销毁这样一种情况。也就是说,每个对象的生命期都很短。同一时刻内,系统中存在的对象数也比较小。而Flyweight对应的情况是在同一时刻内,系统中存在大量对象。
5. Flyweight内部共享机制和object cache的区别。
5.1 原理不同
cache的原理是程序的局部访问性原理。对一小部分经常使用到的对象/数据提供一个高速的存储。而大部分数据放在一个低速的存储中。因此有cache算法和命中率的问题。flyweight的共享机制中,并没有高速和低速的问题。也不存在命中率的问题。可能会有一个查找算法的问题。
5.2 运用场合的不同。
cache运用在一小部分对象会被经常访问到的情况。比如说论坛中置顶的帖子。
flyweight用在同时使用到大量对象的情况。比如在屏幕上绘制一张有100万个电子元器件的电路图。这个时候每个对象都被用到一次,且只被用到一次。
6 在这里再提一下Buffer这个概念。
Buffer的原理是减小访问的波动性。在软件开发上用的比较少。
23.访问者模式
http://blog.csdn.net/chenzujie/article/details/7952823
后续:
1.责任链模式与状态模式的区别
2.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号