【机器学习 Azure Machine Learning】Azure Machine Learning 访问SQL Server 无法写入问题 (使用微软Python AML Core SDK)
问题情形
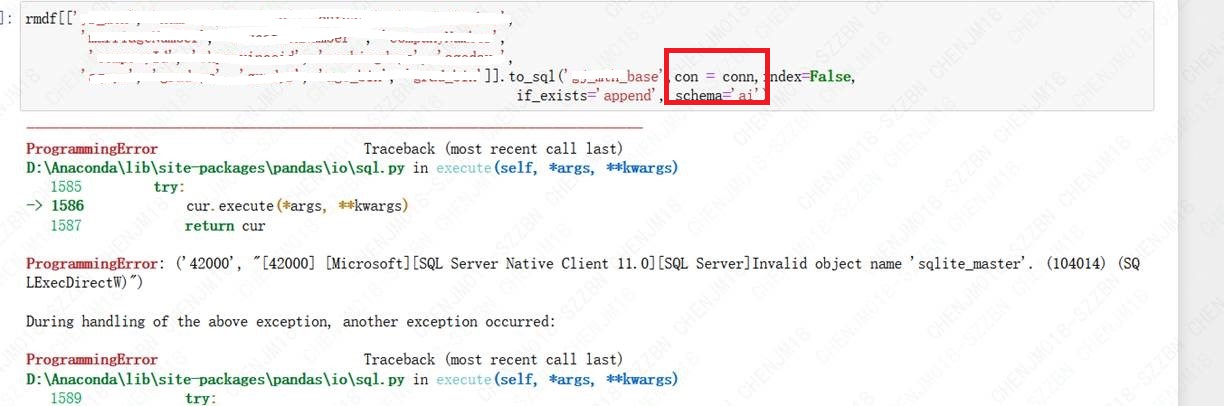
使用Python SDK在连接到数据库后,连接数据库获取数据成功,但是在Pandas中用 to_sql 反写会数据库时候报错。错误信息为:ProgrammingError: ('42000', "[42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Invalid object name 'sqlite_master'. (104014) (SQLExecDirectW)")。
出错代码片段:
import pyodbc import itertools import sys from sqlalchemy import create_engine import urllib import scipy.stats as stats conn = pyodbc.connect(r'DRIVER={SQL Server Native Client 11.0};SERVER=database.database.chinacloudapi.cn;DATABASE=db;UID=user;PWD=pwd') rmdf[[‘']].to_sql('xxxx_base',con = conn,index=False, if_exists='append', schema='ai')
错误截图:
详细日志
ActivityCompleted: Activity=to_pandas_dataframe, HowEnded=Failure, Duration=672.71 [ms], Info =
{'activity_id': 'e850f767-0c12-4864-8d01-d11dc5817ec9', 'activity_name': 'to_pandas_dataframe', 'activity_type': 'PublicApi', 'app_name': 'TabularDataset',
'source': 'azureml.dataset', 'version': '1.0.76', 'completionStatus': 'Success', 'durationMs': 6.05},
Exception=DatasetExecutionError; Could not connect to specified database.|session_id=f648402f-f619-469d-a6f4-aee7031bd438
---------------------------------------------------------------------------
ExecutionError Traceback (most recent call last) /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/data/dataset_error_handling.py in _try_execute(action, **kwargs) 82 else:
---> 83 return action() 84 except Exception as e: /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/_loggerfactory.py in wrapper(*args, **kwargs) 130 try:
--> 131 return func(*args, **kwargs) 132 except Exception as e: /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/dataflow.py
in to_pandas_dataframe(self, extended_types, nulls_as_nan) 676 self._engine_api.execute_anonymous_activity(
--> 677 ExecuteAnonymousActivityMessageArguments(anonymous_activity=Dataflow._dataflow_to_anonymous_activity_data(dataflow_to_execute)))
678 /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/_aml_helper.py in wrapper(op_code, message, cancellation_token)
37 engine_api_func().update_environment_variable(changed)
---> 38 return send_message_func(op_code, message, cancellation_token) 39 /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/engineapi/api.py
in execute_anonymous_activity(self, message_args, cancellation_token) 93
def execute_anonymous_activity(self, message_args: typedefinitions.ExecuteAnonymousActivityMessageArguments, cancellation_token: CancellationToken = None) -> None:
---> 94 response = self._message_channel.send_message('Engine.ExecuteActivity', message_args, cancellation_token)
95 return response /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/engineapi/engine.py
in send_message(self, op_code, message, cancellation_token) 118 if 'error' in response:
--> 119 raise_engine_error(response['error']) 120 elif response.get('id') == message_id: /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/errorhandlers.py
in raise_engine_error(error_response) 21 if 'ActivityExecutionFailed' in error_code:
---> 22 raise ExecutionError(error_response) 23 elif 'UnableToPreviewDataSource' in error_code: ExecutionError: Could not connect to specified database.
|session_id=f648402f-f619-469d-a6f4-aee7031bd438 During handling of the above exception, another exception occurred:
DatasetExecutionError Traceback (most recent call last) <ipython-input-7-7f54b930998f> in <module>
----> 1 dataset.to_pandas_dataframe() /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/data/_loggerfactory.py in wrapper(*args, **kwargs) 76
with _LoggerFactory.track_activity(logger, func.__name__, activity_type, custom_dimensions) as al: 77 try:
---> 78 return func(*args, **kwargs) 79 except Exception as e: 80 if hasattr(al, 'activity_info')
and hasattr(e, 'error_code'): /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/data/tabular_dataset.py
in to_pandas_dataframe(self) 138 """ 139 dataflow = get_dataflow_for_execution(self._dataflow, 'to_pandas_dataframe', 'TabularDataset')
--> 140 df = _try_execute(dataflow.to_pandas_dataframe) 141 return df
142 /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/data/dataset_error_handling.py in _try_execute(action, **kwargs)
83 return action() 84 except Exception as e:
---> 85 raise DatasetExecutionError(str(e)) DatasetExecutionError: Could not connect to specified database.|session_id=f648402f-f619-469d-a6f4-aee7031bd438
问题原因
根据代码判断,问题是在to_sql方法中使用的con对象的问题,此处需要使用的是由 sqlalchemy所创建的 create_engine对象,而不能使用 pyodbc的conn对象。 同时也必须根据环境选择正确的DB驱动。如Windows环境中,则可以使用'Driver={SQL Server};',而在Linux中,则可以使用DRIVER={SQL Server Native Client 11.0};
错误的连接对象:
import pyodbc conn = pyodbc.connect(r'DRIVER={SQL Server Native Client 11.0};SERVER=xxxx.database.chinacloudapi.cn;DATABASE=xx;UID=xx;PWD=')
正确的SQL连接对象:
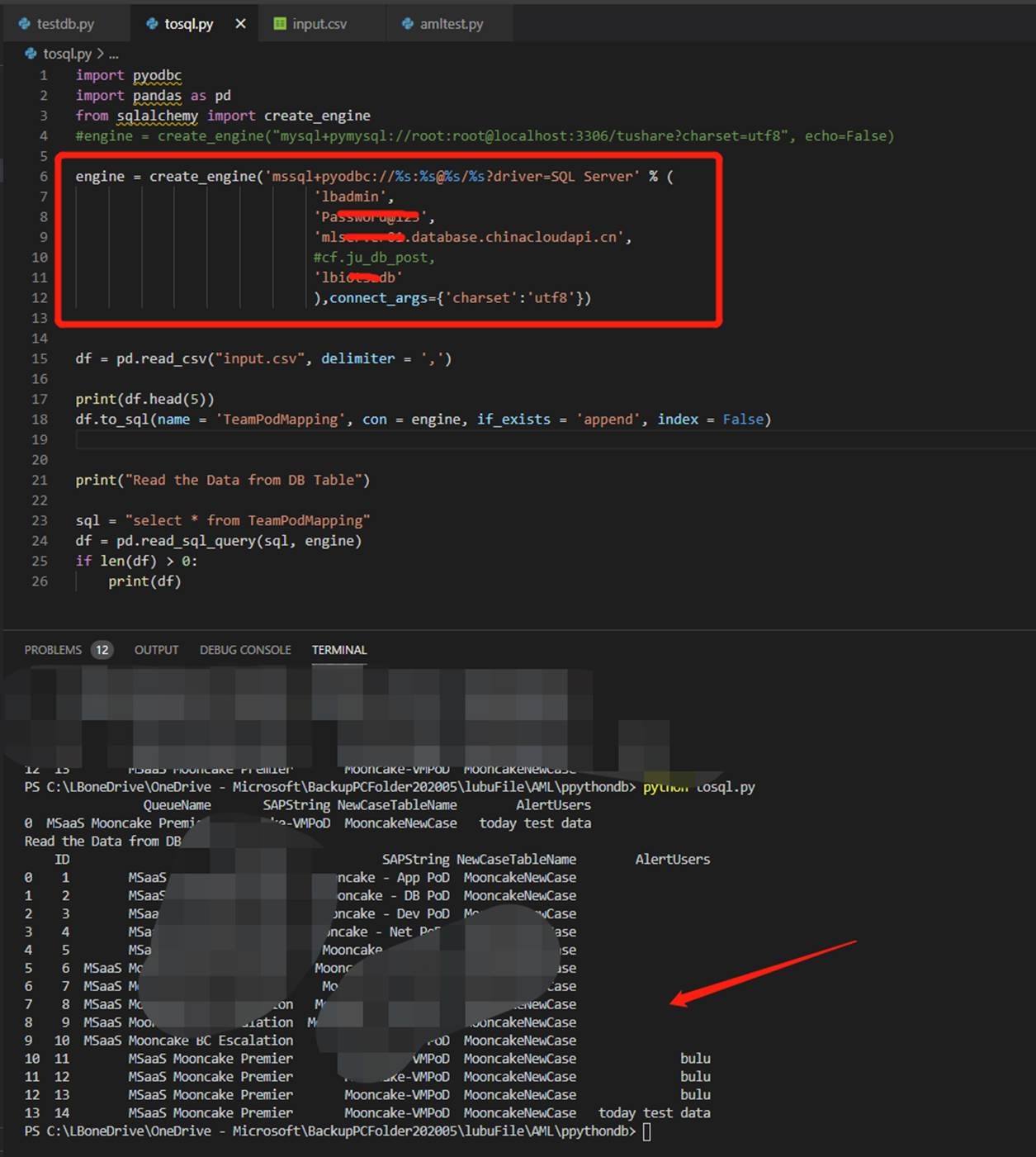
from sqlalchemy import create_engine engine = create_engine('mssql+pyodbc://%s:%s@%s/%s?driver=SQL Server' % ( 'user name', 'pwd', '<service name>.database.chinacloudapi.cn', #cf.ju_db_post, 'DB Name' ),connect_args={'charset':'utf8'})
解决方案
使用Create_engine创建engine并且使用在to_sql方法中,具体代码如下图:
注意:如出现类似错误消息是“Error: ('01000', "[01000] [unixODBC][Driver Manager]Can't open lib 'SQL Server' : file not found (0) (SQLDriverConnect)")”,则需要检查当前VM中的ODBC Driver。
参考资料:
pandas.DataFrame.to_sql:https://pandas.pydata.org/pandas-docs/version/0.23.4/generated/pandas.DataFrame.to_sql.html
当在复杂的环境中面临问题,格物之道需:浊而静之徐清,安以动之徐生。 云中,恰是如此!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号