Linux系统编程【2】——编写who命令
学到的知识点
通过实现who命令,学到了:
- 1.使用man命令寻找相关信息
- 2.基于文件编程
- 3.体会到c库函数与系统调用的不同
- 4.加深对缓冲技术的理解
who命令的作用
who命令的使用
在控制终端输入:
man who
结果如下图所示

可以看出,who命令的使用很简单,直接在终端输入:
who
作用就是显示当前登录的用户信息。
who命令的显示结果含义

第一列表示已登录用户,第二列表示终端名,第三列表示登录时间,第四列表示用户的登录地址。
如何实现who命令
逆向推导
定位文件
who命令的运行结果有四列,那么只要找到存储这些信息的地方,把它们从其中拿出来显示就可以了。
那么如何找到这些信息的存放位置呢?还是通过 man who命令,找到file相关的信息:

这样就找到了所需的数据在"/var/run/utmp"或者"/var/log/wtmp"这两个文件夹中
查看文件内容
顺藤摸瓜,直接去"/var/run/utmp"看一下,看里面的数据有哪些。于是笔者输入
more /var/run/utmp
但是只输出几行空白内容:

同样的,笔者又输入
more /var/log/wtmp
这次除了空白内容,还输出部分字符:

这些输出的内容并非想象的那样,但可以肯定的是,这两个文件里面一定有内容,不然who命令那些字段也会为空。那么出现这种情况,可能与文件格式有关。接着笔者利用file命令来查看文件属性:

这两个文件都是DBT类型的文件,与常规的ASCII text文件不同,所以没法正常显示。
笔者又尝试使用vim /var/run/utmp命令来查看,结果如下:

同理,使用vim /var/log/wtmp命令查看,结果如下:

这次虽然其中有大部分看不懂的符号,但显示出了一些有用的信息。如:用户名、终端。从两个文件显示的内容多少和其中的字段信息,能够看出:
- /var/run/utmp存储的是当前登录的用户信息
- /var/log/wtmp存储的是历史登录用户信息
虽然笔者还未找到能够正常显示该文件类型的命令,但是通过vim也能够看个大概。因为要获得当前登录用户信息,所以接下来就只需研究"/var/run/utmp"这个文件了。
摸清文件结构
那么现在的问题就是,如何读取文件内容。在之前笔者已经试过了,采用more命令无法正常读取并显示。为此,笔者又使用自己编写的more02命令(见Linux系统编程【1】——编写more命令),在不同的地方加入输出语句,来定位问题所在。
more02的主体流程是:
用fopen打开文件,返回文件指针fp ----> 用fgets获得fp指向的文件内容,存入字符数组line ---> 用fputs字符数组line中字符显示到屏幕上。
fopen函数能正常打开"/var/run/utmp",fp指向的缓存内容也和ls -al列出来的文件大小一致。而fgets得到的都是空内容。换成getc也是同样如此。
为了弄清楚fgets和getc这两个函数,输入:man fgets查看
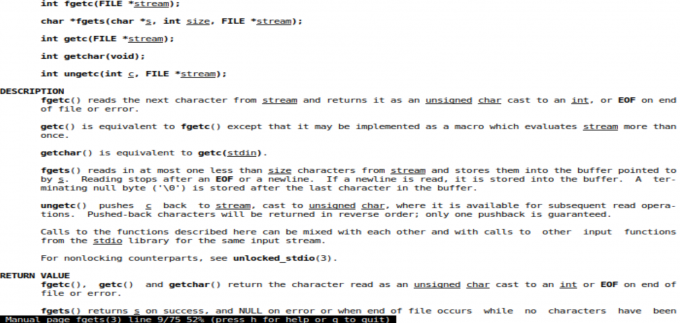
即fgets和getc在遇到文件结束符或者发生错误时返回NULL 或 EOF。综合之前vim中显示的内容,可以猜测fgets或getc在读取"var/run/utmp"的fp缓存内容时遇到非法字符,导致读取失败。
既然不能将其按照文本流的形式处理,那么就需要搞清楚文件的存储结构。为了获得更多的信息,输入
man utmp
从帮助手册中可以看到,utmp时一个结构体,"/var/run/utmp"中存储的就是这个结构体,utmp结构体定义如下:
//引用自linux源代码
#define EMPTY 0 /* Record does not contain valid info(formerly known as UT_UNKNOWN on Linux) */
#define RUN_LVL 1 /* Change in system run-level (see init(8)) */
#define BOOT_TIME 2 /* Time of system boot (in ut_tv) */
#define NEW_TIME 3 /* Time after system clock change(in ut_tv) */
#define OLD_TIME 4 /* Time before system clock change(in ut_tv) */
#define INIT_PROCESS 5 /* Process spawned by init(8) */
#define LOGIN_PROCESS 6 /* Session leader process for user login */
#define USER_PROCESS 7 /* Normal process */
#define DEAD_PROCESS 8 /* Terminated process */
#define ACCOUNTING 9 /* Not implemented */
#define UT_LINESIZE 32
#define UT_NAMESIZE 32
#define UT_HOSTSIZE 256
struct exit_status { /* Type for ut_exit, below */
short int e_termination; /* Process termination status */
short int e_exit; /* Process exit status */
};
struct utmp {
short ut_type; /* Type of record */
pid_t ut_pid; /* PID of login process */
char ut_line[UT_LINESIZE]; /* Device name of tty - "/dev/" */
char ut_id[4]; /* Terminal name suffix,or inittab(5) ID */
char ut_user[UT_NAMESIZE]; /* Username */
char ut_host[UT_HOSTSIZE]; /* Hostname for remote login, or kernel version for run-level messages */
struct exit_status ut_exit; /* Exit status of a process marked as DEAD_PROCESS; not used by Linux init (1 */
/* The ut_session and ut_tv fields must be the same size when
compiled 32- and 64-bit. This allows data files and shared
memory to be shared between 32- and 64-bit applications. */
#if __WORDSIZE == 64 && defined __WORDSIZE_COMPAT32
int32_t ut_session; /* Session ID (getsid(2)),used for windowing */
struct {
int32_t tv_sec; /* Seconds */
int32_t tv_usec; /* Microseconds */
} ut_tv; /* Time entry was made */
#else
long ut_session; /* Session ID */
struct timeval ut_tv; /* Time entry was made */
#endif
int32_t ut_addr_v6[4]; /* Internet address of remote host; IPv4 address uses just ut_addr_v6[0] */
char __unused[20]; /* Reserved for future use */
};
/* Backward compatibility hacks */
#define ut_name ut_user
#ifndef _NO_UT_TIME
#define ut_time ut_tv.tv_sec
#endif
#define ut_xtime ut_tv.tv_sec
#define ut_addr ut_addr_v6[0]
我们需要的就是utmp结构体中的ut_name(登录的用户名)、ut_line(登录终端)、ut_time(登录时间)、ut_host(登录地址)。至此,已经了解"/var/run/utmp"文件结构。
打开并读取"/var/run/utmp"
利用open、read、close这三个系统调用分别完成文件的打开、读取和关闭。这几个命令和之前实现的more02所需的函数fopen、fgets、fclose看起来很相似,那么为什么不直接使用之前的这几个呢?
带着这个疑问,笔者查看了这几个函数的函数原型,得出了它们之间的不同之处。
open/fopen,read/fgets,close/fclose找不同
参考:
https://blog.csdn.net/oscarjulia/article/details/72638060
https://blog.csdn.net/yanglianzhuang/article/details/83546696
open
int open(const char *path, int access,int mode)
/* path 要打开的文件路径和名称
* access 访问模式,宏定义和含义如下:
* O_RDONLY 1 只读打开
* O_WRONLY 2 只写打开
* O_RDWR 4 读写打开
*/
fopen
FILE *fopen(char *filename, char *mode)
/* filename 文件名称
* mode 打开模式:
* r 只读方式打开一个文本文件
* rb 只读方式打开一个二进制文件
* w 只写方式打开一个文本文件
* wb 只写方式打开一个二进制文件
* a 追加方式打开一个文本文件
* ab 追加方式打开一个二进制文件
* r+ 可读可写方式打开一个文本文件
* rb+ 可读可写方式打开一个二进制文件
* w+ 可读可写方式创建一个文本文件
* wb+ 可读可写方式生成一个二进制文件
* a+ 可读可写追加方式打开一个文本文件
* ab+ 可读可写方式追加一个二进制文件
*/
open与fopen的不同
-
1、缓冲文件系统与非缓冲系统的区别
-
缓冲文件系统(fopen) :在内存为每个文件开辟一个缓存区,当执行读操作,从磁盘文件将数据读入内存缓冲区,装满后从内存缓冲区依次读取数据。写操作同理。内存缓冲区的大小影响着实际操作外存的次数,缓冲区越大,操作外存的次数越少,执行速度快,效率高。缓冲区大小由机器而定。借助文件结构体指针对文件管理,可读写字符串、格式化数据、二进制数据。
-
非缓冲文件系统(open):依赖操作系统功能对文件读写,不设文件结构体指针,只能读写二进制文件。
-
open无缓冲,fopen有缓冲
-
2、open属于低级IO,fopen属于高级IO。
-
3、open返回文件描述符,属于用户态,读写需进行用户态与内核态切换。fopen返回文件指针。
-
4、open是系统函数,不可移植。fopen是标准C函数,可移植。
-
5、一般用fopen打开普通文件,open打开设备文件。
-
6、 如果顺序访问文件,fopen比open快。如果随机访问文件,open比fopen快。
read
ssize_t read(int fd,void *buf,size_t nbyte)
/*参数:
* fd 文件描述符
* buf 用来存放数据的目的缓冲区
* qty 要读取的字节数
*
*返回值:
* -1 遇到错误
* numread 成功读取
*/
fgets
char * fgets ( char * str, int num, FILE * stream )
/*参数:
* str 用来存放数据的目的缓冲区
* num 要读取的字节数
* stream 被读取的文件的文件指针
*/
read和fgets的不同
-
read函数是负责从fd中读取最多nbytes个字节到buf,在读取数据时会将最后的回车(\n)同时读入到buf中,但是 不会在后面加上字符串结束符(\0)。成功时,read返回实际所读的字节数,如果返回的值是0,表示已经读到文件的结束了.若返回负值(通常为-1)表示发生了错误。
-
fgets负责从stream(通常是文件或者标准输入stdin)中读取num个字符到str中,在读取数据时会将最后的回车(\n)同时读入到buf中,并且会在后面加上字符串结束符(\0)。成功返回非空指针,失败返回空指针。
close
int close(int fd);
/*参数:
* fd 文件描述符
*
*返回值:
-1 遇到错误
0 成功关闭
*/
fclose
int fclose(FILE *stream);
/*参数:
* stream 文件流,即文件指针
*
*返回值:
0 成功关闭
-1 遇到错误
*/
close和fclose的不同
-
close()是与文件描述符相关的函数。在open()的帮助下打开文件并将描述符赋值给int fd。使用close()关闭打开的文件。
-
fclose()是与文件流相关的函数。在fopen()的帮助下打开文件并将流分配给FILE * ptr。使用fclose()关闭打开的文件。
文件指针和文件描述符的联系
相对底层的系统调用,如open函数,返回的是一个文件描述符。而相对高层的c库函数,如fopen,返回的是一个文件指针。
这两者的主要联系在于:文件指针指向的FILE结构体中,就包含了文件描述符,还包含对于缓冲和I/O的管理,是对文件描述符的包装。
小结
上述三对函数每对之间共有的不同就是,一个是系统调用,一个是封装好的c库函数,前者不可移植,后者可移植。这也符合越底层越不可移植,越高层越抽象越可移植的观点。
经过比对之后,笔者发现出问题的地方就在于fgets用来接收读取的内容是字符指针类型,并且其在最后会自动加上'\0',这就可能导致无法正常的读取结构体内容。所以使用更纯粹的read函数(读取时不会在后面加'\0',并且接收读取的内容是void类型指针),利用read函数能够完成自定义更高的操作,更灵活。
于是,确定实现who的流程便是:
step1.用open函数打开"/var/run/utmp",获得文件描述符utmpfd
step2.依据utmpfd,用read函数读取文件内容到一个utmp结构体指针
step3.打印出读取的utmp结构体指针指向的结构体中的所需参数
step4.用close函数关闭打开的"/var/run/utmp"文件
初级实现代码
//who01.c
/* copyright@lularible
* 2021/02/04
*/
#include<stdio.h>
#include<utmp.h>
#include<fcntl.h>
#include<unistd.h>
#include<stdlib.h>
#include<time.h>
//辅助函数声明
void show_info(struct utmp*);
void showtime(long);
int main()
{
struct utmp current_record; //定义utmp结构体
int utmpfd; //定义文件描述符
int reclen = sizeof(current_record);//获得utmp结构体大小
//打开文件的错误处理
if((utmpfd = open(UTMP_FILE,O_RDONLY)) == -1){
perror(UTMP_FILE);
exit(1);
}
//读取文件内容并打印
while(read(utmpfd,¤t_record,reclen) == reclen){
show_info(¤t_record);
}
close(utmpfd);
return 0;
}
//打印读取到的结构体数据
void show_info(struct utmp* utbufp)
{
//当目前记录不是用户信息时,舍弃
if(utbufp->ut_type != USER_PROCESS){
return;
}
//打印用户名
printf("%-10.10s",utbufp->ut_name);
printf(" ");
//打印用户登录终端
printf("%-10.10s",utbufp->ut_line);
printf(" ");
//打印用户登录时间
showtime((long)utbufp->ut_time);
//打印用户登录地址
if(utbufp->ut_host[0] != '\0'){
printf("(%s)",utbufp->ut_host);
}
printf("\n");
}
//完成时间转换并打印
void showtime(long timeval)
{
char *cp;
cp = ctime(&timeval);
printf("%24.24s",cp);
}
优化who命令
在学习操作系统课程时,第一章就接触到了“系统调用”这个概念。系统调用是在用户态下调用“系统调用函数”,转为“内核态”去执行这个函数,然后将结果返回给用户态。这就需要完成“用户态”到“内核态”再到“用户态”之间切换。这种切换过程需要完成状态保存、参数压栈、寄存器切换等等操作,比较费事(但为了系统的安全稳定性,不得不这样进行状态划分)。
而我们的这个who01程序,运行次数最多的系统调用就是read函数(登录的用户记录可能有很多条,需要多次调用read读取),关键点就在于一次只读取了一个utmp结构体大小的数据。如果一次能够读取多条结构体数据,缓存起来,然后从缓冲中拿就行,缓冲中拿完了再调用read,这样就能减少系统调用次数,提高程序效率。
需要做的很简单,直接在read那一部分下手,修改后的代码如下:
//who2.c
/* copyright@lularible
* 2021/02/04
*/
#include<stdio.h>
#include<utmp.h>
#include<fcntl.h>
#include<unistd.h>
#include<stdlib.h>
#include<time.h>
//定义缓冲区大小
#define ITEMS 8
//辅助函数声明
void show_info(struct utmp*);
void showtime(long);
int main()
{
struct utmp current_record; //utmp结构体
struct utmp* next_record; //缓冲区中下一个要拿的结构体
int utmpfd; //文件描述符
int records_size = 0; //read一次读取的内容大小
int records_cnt = 0; //read一次读取的结构体个数
int reclen = sizeof(current_record);//获得utmp结构体大小
char utmpbuf[reclen * ITEMS]; //缓冲区
//打开文件的错误处理
if((utmpfd = open(UTMP_FILE,O_RDONLY)) == -1){
perror(UTMP_FILE);
exit(1);
}
//读取文件内容并打印
while(read(utmpfd,¤t_record,reclen) == reclen){
records_cnt = records_size / reclen; //一次读取了多少个utmp结构体
int i = 0;
//从缓冲区中拿数据并打印
for(i = 0;i < records_cnt;++i){
next_record = (struct utmp*) &utmpbuf[i * reclen];
show_info(next_record);
}
}
close(utmpfd);
return 0;
}
//打印读取到的结构体数据
void show_info(struct utmp* utbufp)
{
//当目前记录不是用户信息时,舍弃
if(utbufp->ut_type != USER_PROCESS){
return;
}
//打印用户名
printf("%-10.10s",utbufp->ut_name);
printf(" ");
//打印用户登录终端
printf("%-10.10s",utbufp->ut_line);
printf(" ");
//打印用户登录时间
showtime((long)utbufp->ut_time);
//打印用户登录地址
if(utbufp->ut_host[0] != '\0'){
printf("(%s)",utbufp->ut_host);
}
printf("\n");
}
//完成时间转换并打印
void showtime(long timeval)
{
char *cp;
cp = ctime(&timeval);
printf("%24.24s",cp);
}
总结
其实在fopen函数中,就已经采用了缓冲技术来减少系统调用,用fread函数读取并打印能起到同样的效果。这次利用open、read、close这几个系统调用函数,手动加上缓冲,加深了对系统调用和缓冲技术的了解,同时也更有趣味性(当然熟悉了以后,还是调更高层的API舒服)。
参考资料
《Understanding Unix/Linux Programming A Guide to Theory and Practice》
欢迎大家转载本人的博客(需注明出处),本人另外还有一个个人博客网站:[https://www.lularible.cn],欢迎前去浏览。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号