自动猫品种分类系统的构建与实现
在现代社会,宠物猫的受欢迎程度越来越高。每种猫都有其独特的特点,从外观到性格,甚至到特定的健康需求。对于猫的爱好者和养猫新手,能够准确识别猫的品种是非常有帮助的。本项目旨在利用现代技术,特别是深度学习,来创建一个能够自动识别和分类猫的品种的系统。在这篇技术博客中,我将详细介绍如何从Bing搜索引擎爬取图片数据,使用Keras搭建卷积神经网络进行猫的品种分类,并利用GUI展示分类结果的整个过程。
1. 数据收集:使用爬虫从Bing搜索引擎中获取猫品种图片
在深度学习或机器学习项目中,数据起着至关重要的作用。特别是在图像分类任务中,数据集的质量和数量直接决定了模型的效果。考虑到猫的种类繁多并且市面上难以找到一个完善的猫品种图片数据集,我决定自己动手从Bing搜索引擎中爬取相关图片。
为此,我创建了一个简单的Python爬虫来自动化这一过程。以下是我在构建爬虫时考虑的主要步骤和策略:
- 请求头的设定:为了模拟正常的浏览器行为并避免被Bing封禁,我设定了一个请求头来模拟浏览器请求。
- URL设计:利用特定的URL模式,我可以控制搜索关键词、起始图片位置和一次加载的图片数量。
- 图片获取:为了确保爬取过程的稳定性,每次获取图片时都有一个短暂的延迟。如果尝试下载图片出现异常,则跳过该图片。
- 图片解析:使用BeautifulSoup解析缩略图列表页,再利用正则表达式从中提取原图的URL。
- 路径设置与文件保存:所有爬取的猫品种图片都按品种名称保存在特定的文件夹中。
通过这个爬虫,只需要简单地输入猫的种类,程序就会自动下载相关的图片。这大大简化了数据收集的过程,为后续的模型训练和验证提供了丰富的数据资源。
当然,这只是爬虫的简化版本,真实的网络环境可能会更加复杂,涉及到的问题也会更多,例如IP被封、图片重复度高等。但这为我们提供了一个初步的框架,我们可以根据实际需要进行进一步的优化和完善。
import os
import urllib.parse
import urllib.request
import re
from bs4 import BeautifulSoup
import time
header = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'
}
url = "https://cn.bing.com/images/async?q={0}&first={1}&count={2}&scenario=ImageBasicHover&datsrc=N_I&layout=ColumnBased&mmasync=1&dgState=c*9_y*2226s2180s2072s2043s2292s2295s2079s2203s2094_i*71_w*198&IG=0D6AD6CBAF43430EA716510A4754C951&SFX={3}&iid=images.5599"
# ... the rest of your code ...
def getImage(url, path, count):
'''从原图url中将原图保存到本地'''
try:
time.sleep(0.5)
urllib.request.urlretrieve(url, filename = path + 'rawdata' + str(count + 1) + '.jpg')
except Exception as e:
time.sleep(1)
print("本张图片获取异常,跳过...")
else:
print("成功保存 " + str(count + 1) + " 张图")
def findImgUrlFromHtml(html, rule, path, count):
'''从缩略图列表页中找到原图的url,并返回这一页的图片数量'''
soup = BeautifulSoup(html, "lxml")
link_list = soup.find_all("a", class_="iusc")
url = []
for link in link_list:
result = re.search(rule, str(link))
# 将字符串"amp;"删除
url = result.group(0)
# 组装完整url
url = url[8:len(url)]
# 打开高清图片网址
getImage(url, path, count+100)
count += 1
# 完成一页,继续加载下一页
return count
def getStartHtml(url, key, first, loadNum, sfx):
'''获取缩略图列表页'''
page = urllib.request.Request(url.format(key, first, loadNum, sfx),headers=header)
html = urllib.request.urlopen(page)
return html
if __name__ == '__main__':
name = input('请输入猫的种类:') # 图片关键词
path = './cat/rawdata/' + name +'/' # 图片保存路径
countNum = 200
key = urllib.parse.quote(name)
first = 1
loadNum = 35
sfx = 1
count = 0
rule = re.compile(r"\"murl\"\:\"http\S[^\"]+")
if not os.path.exists(path):
os.makedirs(path)
while count < countNum:
html = getStartHtml(url, key, first, loadNum, sfx)
count = findImgUrlFromHtml(html, rule, path, count)
first = count + 1
sfx += 1
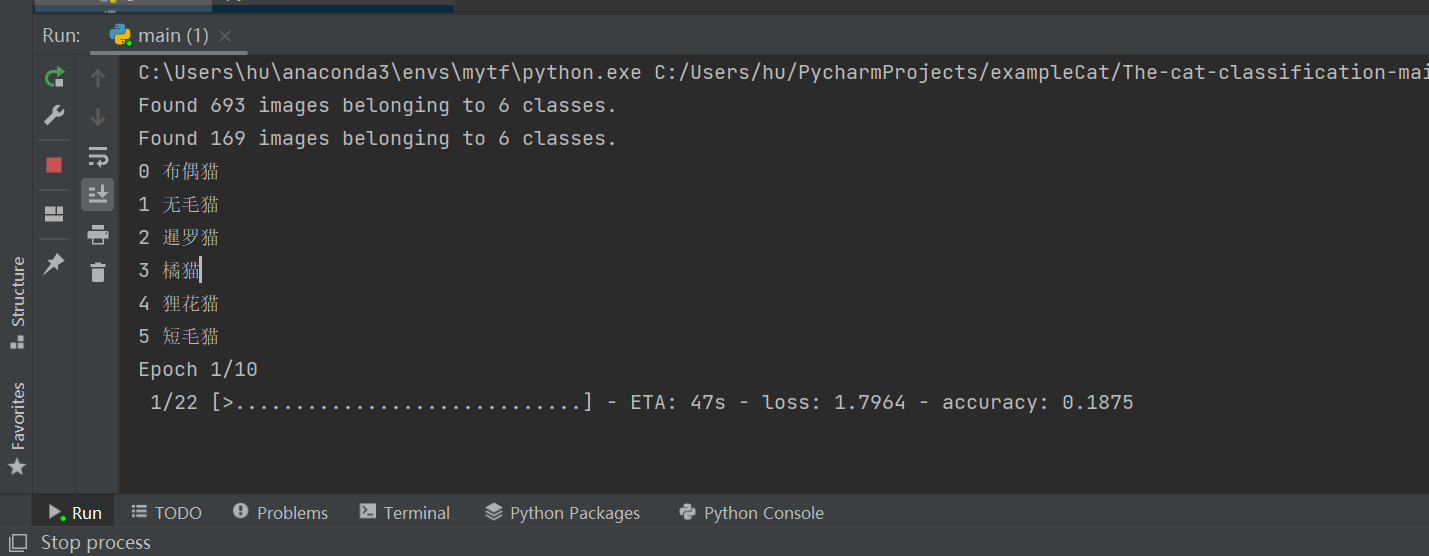
2. 深度学习模型的构建与训练
构建和训练一个深度学习模型是图像分类任务中的核心部分。为了对猫的种类进行分类,我选择了卷积神经网络(CNN)作为模型架构,并使用Keras这一深度学习框架来简化开发和训练过程。以下是模型构建与训练的详细介绍:
-
数据预处理:
- 我使用了Keras的
ImageDataGenerator工具进行数据增强,同时对图片进行了归一化处理,将像素值范围调整到0到1之间。这有助于模型更好地学习和识别图像特征。 - 为了有效评估模型性能,数据集被分为80%的训练集和20%的验证集。
- 我使用了Keras的
-
模型结构选择:
- 卷积层:卷积层可以有效地捕捉图片中的局部特征。模型中有三个卷积层,分别使用64、128和256个卷积核。
- 池化层:池化层有助于减少模型参数数量,并增强模型对位置变化的鲁棒性。
- 全连接层:全连接层将特征进行整合,输出的维度为6,表示六种猫的分类。
softmax激活函数确保输出代表每一类的概率。
-
模型编译:
- 选择了
categorical_crossentropy作为损失函数,这是多分类任务的标准选择。 adam优化器可以自动调整学习率,使模型训练更加稳定。- 为了评估模型的性能,我们使用准确率作为评价指标。
- 选择了
-
模型训练:使用fit方法,模型在10个周期上进行了训练。训练和验证集都用于监控模型的性能,并调整权重。
-
模型保存:经过训练的模型保存到指定路径,方便后续使用和部署。
训练结束后,我们可以绘制训练和验证的准确率和损失曲线,以更直观地评估模型的性能。此外,为了进一步优化模型,可以考虑使用更多的数据增强技巧、调整网络结构、或采用更复杂的预训练模型。
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
data_dir = 'C:\\Users\\hu\\PycharmProjects\\exampleCat\\The-cat-classification-main\\data\\'
datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2)
train_generator = datagen.flow_from_directory(
data_dir,
target_size=(150, 150),
batch_size=32,
class_mode='categorical',
subset='training')
validation_generator = datagen.flow_from_directory(
data_dir,
target_size=(150, 150),
batch_size=32,
class_mode='categorical',
subset='validation')
class_names = train_generator.class_indices
class_names = {v: k for k, v in class_names.items()}
for class_index, class_name in class_names.items():
print(class_index, class_name)
model = Sequential()
model.add(Conv2D(64, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(256, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(6, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(
train_generator,
steps_per_epoch=len(train_generator),
epochs=10,
validation_data=validation_generator,
validation_steps=len(validation_generator))
trained_model_path = 'C:\\Users\\hu\\PycharmProjects\\exampleCat\\The-cat-classification-main\\model.h5'
model.save(trained_model_path)
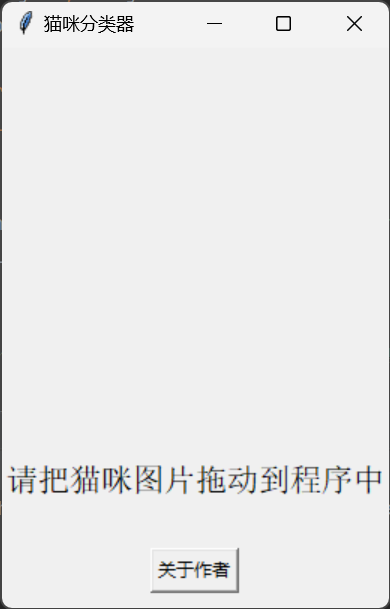
3. GUI预测展示
为了使用户能够更方便地使用我们的模型进行猫品种的分类,我们为其构建了一个图形用户界面(GUI)。在此界面上,用户只需要简单地将图片拖拽到程序窗口,即可快速得到预测结果。
以下是GUI预测展示的详细步骤和实现:
-
GUI设计和实现:
- 我们使用
tkinter库来构建主窗口和相关组件。为了支持拖放功能,我们引入了tkinterdnd2库。 - 主窗口中包含一个画布来显示用户拖放的图片、一个标签来显示预测结果,以及一个按钮,点击后可以查看关于作者的信息。
- 我们使用
-
模型集成到GUI:
- 我们首先载入了预训练的模型。然后,当用户拖放图片时,我们对图片进行预处理并使用模型进行预测。
- 图片的预处理包括尺寸调整、像素值归一化等步骤。
- 使用模型预测后,我们将得到的预测结果显示在前面提到的标签上。
-
用户交互和实际应用:
- 用户只需要将猫的图片拖放到程序窗口,就可以看到图片在画布上的显示和猫的种类预测结果。
- 另外,用户还可以通过点击“关于作者”按钮,来了解软件的开发者信息。
这个GUI为用户提供了一个直观的方式来使用我们的模型,无需深入了解背后的技术细节。在实际应用中,我们还可以进一步优化和扩展这个界面,例如添加更多的功能、支持更多的图片格式、提供更丰富的用户反馈等。
import keras
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from PIL import ImageTk, Image
import numpy as np
import tkinter as tk
from tkinter import messagebox
from tkinterdnd2 import TkinterDnD
# 载入训练好的模型
trained_model_path = 'C:\\Users\\hu\\PycharmProjects\\exampleCat\\The-cat-classification-main\\model.h5'
model = load_model(trained_model_path)
# 猫的类别
CAT_CLASSES = ['布偶猫', '无毛猫', '暹罗猫', '橘猫', '狸花猫', '短毛猫']
def prepare_image(file):
img = load_img(file, target_size=(150, 150))
img_array = img_to_array(img)
img_array_expanded_dims = np.expand_dims(img_array, axis=0)
return keras.applications.mobilenet.preprocess_input(img_array_expanded_dims)
def predict_class(file):
preprocessed_image = prepare_image(file)
predictions = model.predict(preprocessed_image)
return CAT_CLASSES[np.argmax(predictions)]
def drop(event):
# strip brackets from the file_path
file_path = event.data.strip('{}')
result = predict_class(file_path)
# Load and display image in canvas
img = Image.open(file_path)
img_width, img_height = img.size
aspect_ratio = img_width / img_height
new_width = 200
new_height = int(new_width / aspect_ratio)
img = img.resize((new_width, new_height), Image.ANTIALIAS)
img = ImageTk.PhotoImage(img)
canvas.create_image(20, 20, anchor='nw', image=img)
canvas.image = img # Keep a reference to prevent garbage collection
result_label.config(text="猫咪的种类是: " + result)
def about_author():
messagebox.showinfo('关于作者', '作者: ')
root = TkinterDnD.Tk()
root.title('猫咪分类器')
canvas = tk.Canvas(root, width=250, height=250)
canvas.pack()
result_label = tk.Label(root, text="请把猫咪图片拖动到程序中", font=("Helvetica", 16))
result_label.pack(pady=20)
about_button = tk.Button(root, text="关于作者", command=about_author)
about_button.pack(side='bottom', pady=10)
root.drop_target_register('DND_Files')
root.dnd_bind('<<Drop>>', drop)
root.mainloop()

我们的项目旨在创建一个能够识别不同猫品种的系统,从数据采集到GUI展示,全程涵盖了机器学习工程的核心步骤。通过Bing搜索引擎,我们爬取了大量的猫图片作为训练数据。借助Keras框架,我们构建并训练了一个深度学习模型,并在验证集上验证了其性能。最后,我们为模型构建了一个用户友好的图形界面,使得无需任何编程背景的用户也可以轻松地使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号