python爬虫------------旅游的地点的爬取和可视化
选题背景
我国旅游行业的极速发展,因为之前疫情原因,使得国内旅游成为新风潮,由于国内疫情控解封,使得中国成为最先开放旅游的国家,
本次项目可视化就是分析国内旅游的数据,分析适合出行旅游的时间与地点信息。
设计方案
1.向目标网络发送请求
2.获取数据 网页源码3.筛选我们需要的数据 网页源代码
4.筛选数据 获取数据
5.for循环 获取每一页的数据
6.提前数据
出发日期 天数 人均费用 人物 玩法.....
7.保存数据
8.多页爬取
9.可视化分析根据项目主题,设计项目实施方案,包括实现思路与技术难点等
导入所需要的库

#筛选数据
import parsel
import csv
import time
import random
import pandas
import matplotlib.pyplot as plt
from pyecharts import Map
import jieba
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from PIL import Image
from os import path
##数据可视化
import matplotlib.pyplot as plt
2.数据的抓取

3.主题云词图
list_all = []
text = ''
with open('C:/Users/wdsa/Desktop/去哪儿.csv', 'r', encoding='utf8') as file:
t = file.read()
file.close()
for i in title_list:
if type(i) == float:
pass
else:
list_all.append(i)
txt = " ".join(list_all)
# 导入自定义图片作为背景
backgroud_Image = plt.imread('C:/Users/wdsa/Desktop/阳光.jpg')
print('加载图片成功!')
w = WordCloud(
# 汉字设计
font_path="msyh.ttc",
# 宽度设置
width=1000,
# 高度设置
height=800,
# 设置背景颜色
background_color="white",
# 设置停用词
stopwords=STOPWORDS,
## 设置字体最大值
max_font_size=150
)
w.generate(txt)
print('开始加载文本')
img_colors = ImageColorGenerator(backgroud_Image)
# 字体颜色为背景图片的颜色
w.recolor(color_func=img_colors)
# 显示词云图
plt.imshow(w)
# 是否显示x轴、y轴下标
plt.axis('off')
# 显示图片
plt.show()
# 获得模块所在的路径的
d = path.dirname(__file__)
# w.to_file(d,"C:/Users/wdsa/Desktop/wordcloud.jpg")!!!!!!!!!!!
print('生成词云成功!')

4.爬取浏览量前五的主题

6.出行方式云词图
list_all_1 = []
txt_1 = ''
# jieba库分词
for j in GO_list:
if i == 'nan':
pass
elif type(j) == float:
pass
else:
list_all_1.append(j)
txt_1 = " ".join(list_all_1)
# 导入自定义图片作为背景
backgroud_Image = plt.imread('C:/Users/wdsa/Desktop/阳光.jpg')
print('加载图片成功!')
pose= WordCloud(
# 汉字设计
font_path="msyh.ttc",
# 宽度设置
width=1000,
# 高度设置
height=800,
# 设置背景颜色
background_color="white",
# 设置停用词
stopwords=STOPWORDS,
## 设置字体最大值
max_font_size=150,
)
pose.generate(txt_1)
print('开始加载文本')
img = ImageColorGenerator(backgroud_Image)
# 字体颜色为背景图片的颜色
w.recolor(color_func=img)
# 显示词云图
plt.imshow(pose)
# 是否显示x轴、y轴下标
plt.axis('off')
# 显示图片
plt.show()
# 获得模块所在的路径的
d = path.dirname(__file__)
# w.to_file(d,"C:/Users/wdsa/Desktop/wordcloud.jpg")!!!!!!!!!!!
print('生成词云成功!')
完整代码
import random
import time
import pandas as pd
import requests
#筛选数据
import parsel
import csv
import time
import random
import pandas
import matplotlib.pyplot as plt
from pyecharts import Map
import jieba
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from PIL import Image
from os import path
##数据可视化
import matplotlib.pyplot as plt
csv_qne = open('C:/Users/wdsa/Desktop/去哪儿.csv',"a",encoding = "utf-8",newline = "")
csv_writer = csv.writer(csv_qne)
csv_writer.writerow(['地点','浏览量','短评','日期','人物','天数','人均消费','详情页'])
for i in range(1,5):
url = f'https://travel.qunar.com/travelbook/list.htm?page={i}&order=hot_heat'
response = requests.get(url = url )
print(response)
data_html = response.text
data_html = response.text
#print(response.text)
#筛选数据,获取数据
selector = parsel.Selector(data_html)
print(selector)
# body > div.qn_mainbox > div > div.left_bar > ul > li > h2 > a
# hrml 标签 : <a href=""></a> <img src=""></img>...
url_list= selector.css('body > div.qn_mainbox > div > div.left_bar > ul > li > h2 > a::attr(href)').getall()
#print(selector.css('body > div.qn_qn_mainbox > div > div.left_bar > ul > li > h2 > a::attr(href)').getall())
#获取每一个详情页
# 'https://travel.qunar.com/travelbook/note/7718113'
# 'https://travel.qunar.com/travelbook/note/7717935'
for i in url_list:
detail_id = i.replace('/youji/','')
datail_url = 'https://travel.qunar.com/travelbook/note/' + detail_id
#向每一页发送链接
response_1 = requests.get(url =datail_url)
#获取数据内容
data_html_1= response_1.text
#提取数据
selector_1 = parsel.Selector(data_html_1)
#获取标题
title = selector_1.css('.b_crumb_cont *:nth-child(3)::text').get()
# 短评
comment = selector_1.css('.title.white::text').get()
#获取浏览量
count = selector_1.css('.view_count::text').get()
#获取天数
data = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.when > p > span.data::text').get()
days = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howloog > p > span.data::text').get()
character = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howlong > p > span.data::text').get()
#消费
money = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.who > p > span.data::text').get()
#攻略
play_list = selector_1.css('#js_mainleft > dix.b_foreword > ul > li.f_item.how > p > span.data::text').get()
# play = " ".join(play_list)
# print(data)
# print(days)
# print(character)
# print(money)
# print(play_list)
csv_writer.writerow([title,comment,count,data,days,money,data,play_list,datail_url])
time.sleep(1)
csv_qne.close()
#获取标题
title_list = []
#浏览量
speake = []
# 出行人数
happer_day = []
#获取出发日期
count_list = []
# 获取日期
days_list = []
#获取出行天数
GO_list = []
#获取人均消费
meony_list = []
#获取详情页
url_list_to = []
#打开数据保存
# with open('C:/Users/wdsa/Desktop/去哪儿.csv',"r",encoding='UTF-8') as df:
# af =pd.DataFrame(df)
af= pd.read_csv('C:/Users/wdsa/Desktop/去哪儿.csv')
for i in af['地点']:
title_list.append(i)
for i in af['短评']:
speake.append(i)
for i in af['浏览量']:
count_list.append(i)
for i in af['日期']:
days_list.append(i)
for i in af['天数']:
happer_day.append(i)
for i in af['人物']:
GO_list.append(i)
for i in af['人均消费']:
meony_list.append(i)
for i in af['详情页']:
url_list_to.append(i)
df =pd.DataFrame(af)
#print(df)
list_all = []
text = ''
with open('C:/Users/wdsa/Desktop/去哪儿.csv', 'r', encoding='utf8') as file:
t = file.read()
file.close()
for i in title_list:
if type(i) == float:
pass
else:
list_all.append(i)
txt = " ".join(list_all)
# 导入自定义图片作为背景
backgroud_Image = plt.imread('C:/Users/wdsa/Desktop/阳光.jpg')
print('加载图片成功!')
w = WordCloud(
# 汉字设计
font_path="msyh.ttc",
# 宽度设置
width=1000,
# 高度设置
height=800,
# 设置背景颜色
background_color="white",
# 设置停用词
stopwords=STOPWORDS,
## 设置字体最大值
max_font_size=150,
)
w.generate(txt)
print('开始加载文本')
img_colors = ImageColorGenerator(backgroud_Image)
# 字体颜色为背景图片的颜色
w.recolor(color_func=img_colors)
# 显示词云图
plt.imshow(w)
# 是否显示x轴、y轴下标
plt.axis('off')
# 显示图片
plt.show()
# 获得模块所在的路径的
d = path.dirname(__file__)
# w.to_file(d,"C:/Users/wdsa/Desktop/wordcloud.jpg")!!!!!!!!!!!
print('生成词云成功!')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置画布的尺寸
plt.figure(figsize=(17, 15))
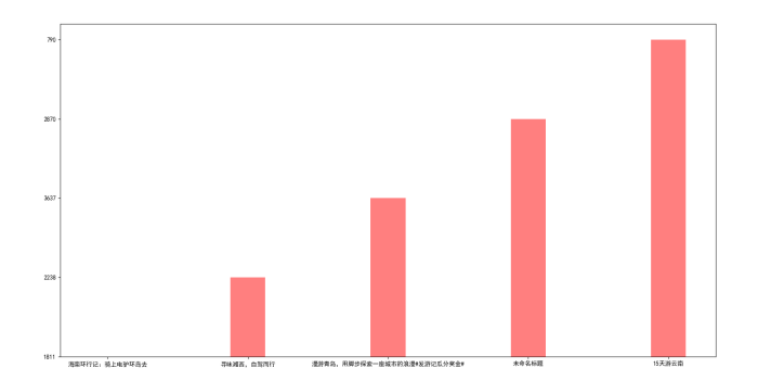
bar_width= 0.25
plt.bar(title_list[:20:4],
count_list[:5],
bar_width,
align="center",
color="red",
label="unpurchased",
alpha=0.5)
plt.show()
plt.figure(figsize=(17, 15))
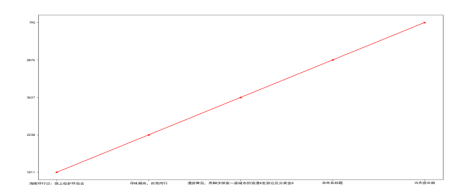
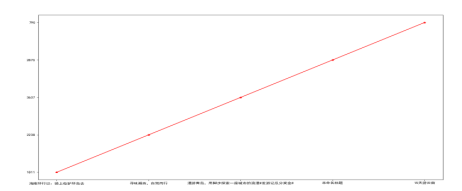
plt.plot(title_list[:20:4],
count_list[:5],
color="red",
label='浏览量',
marker='*',
)
plt.show()
list_all_1 = []
txt_1 = ''
# jieba库分词
for j in GO_list:
if i == 'nan':
pass
elif type(j) == float:
pass
else:
list_all_1.append(j)
txt_1 = " ".join(list_all_1)
# 导入自定义图片作为背景
backgroud_Image = plt.imread('C:/Users/wdsa/Desktop/阳光.jpg')
print('加载图片成功!')
pose= WordCloud(
# 汉字设计
font_path="msyh.ttc",
# 宽度设置
width=1000,
# 高度设置
height=800,
# 设置背景颜色
background_color="white",
# 设置停用词
stopwords=STOPWORDS,
## 设置字体最大值
max_font_size=150,
)
pose.generate(txt_1)
print('开始加载文本')
img = ImageColorGenerator(backgroud_Image)
# 字体颜色为背景图片的颜色
w.recolor(color_func=img)
# 显示词云图
plt.imshow(pose)
# 是否显示x轴、y轴下标
plt.axis('off')
# 显示图片
plt.show()
# 获得模块所在的路径的
d = path.dirname(__file__)
# w.to_file(d,"C:/Users/wdsa/Desktop/wordcloud.jpg")!!!!!!!!!!!
print('生成词云成功!')
运行结果图

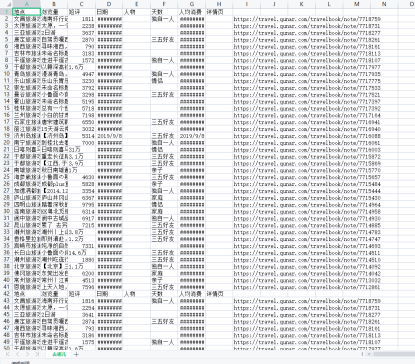
总结
综上所有数据可知,我们用去哪儿网对于国内旅游城市进行了一定的分析以及排名,让人们出游有更加合理的选择,更体现国内疫情解封后每个城市旅行的情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号