计算机视觉入门live笔记
知乎live:计算机视觉从入门到放肆--罗韵
知乎 : 计算机视觉从入门到放肆 罗韵

计算机视觉跟深度学习的结合是必然的事情
计算机视觉,图像处理 基础:
计算机视觉,机器视觉,图像处理的关系是什么?


人工智能领域下的一个分支:计算机视觉

针对场景、方法、工具都不一样

入门提前知道的东西↑
图像的基础知识:
图像深度:(存储每一个像素用到的bits),占用的bit数越多,所能表现的颜色越多,越丰富
例如 : 400*400 8位(深度)图,数据量有多少呢?
计算方法: 400*400*8/8 == 160k
根据深度的取值范围:每个像素的取值范围,决定了颜色的丰富度 2^8,0-255
图像的数据量=图像的分辨率 *图像深度/8
图像分辨率是指 一幅图像横向和纵向的像素点数相乘
图像的压缩格式:jpg,png,bmp,tif 本质上是做压缩编码
奇怪的例子:两张图的大小,长宽,位数都一样,但压缩后的大小不一样
一个很复杂的图,和一张很简单的图,他们都是一张jpg,但他们的大小是不一样的,是因为图片使用的压缩格式和编码不一样
图片的通道数:灰度图(单通道),RGBA(四通道):包括了RBG跟A(透明度)
两通道的图(一个通道放实数,另一个通道放虚数):主要为了编程的方便
16位图:本来是三通道图,为了减少数据量,压缩到16位(刚好两个通道),
常见:RGB555(R占5位,G占5位,B占5位),RGB565 古老通道形式
监控摄像头,模拟相机:yuv,yuyv这些数据格式,关乎于图片的通道数和存储方式
视频的基础知识:
IPB帧,帧率,码率,分辨率
视频分析的第一步,视频的结构,特点,比如(帧率和码率特别低,是不能套模版的)
比如做目标跟踪,人家是每秒30帧情况下跟踪效果很好,但是如果你每秒只有2帧,那你
跟踪效果,肯定会有影响(有可能人在上一帧有,下一帧就没有了,跟踪个P啊。。)
维度:
IPB:原始的视频可以理解为是一些图片的序列
而视频里面每一张有序的图片,我们叫做一帧
视频:有序的图片序列
(图片都有压缩,那视频肯定也有压缩啊)
而IPB指的是,在压缩完的视频里面,只会存在的三种帧
I帧:关键帧,(会把一张图片完整的保留下来),很重要,I帧不能出错,出错全GG
P帧:指的是当前这一帧和上一张关键帧的区别,解码的时候很简单,只需要用之前
缓存的画面叠加上这一帧的差别,就能生成最终的画面,所以我们就不需要把画面 完全保留下来,而是保留下 P帧(当前帧和上一个I帧的差别)
B帧:双向差别帧(跟上一个I帧的差别,下一个I帧的差别)
解码B帧,cpu会比较累
所以一个视频被压缩后,只有这三种帧。
视频在当前更多的使用方式,已经不是用硬盘去读取,而是用网络的形式去读取
例如:网络摄像头,视频的网络地址(对于I帧的要求更高)
如果传输却一个I帧,视频会缺一段。。。
码率:码率越大,视频体积越大,码率越小,视频体积越小
码率:视频传输的时候,单位时间传送的单位数,kb/s,
采样率:单位时间内取样越多,精确度越大
视频码率很低--->单位时间内采样率很低,
一个视频,码率不够的情况,我们得到的视频可能只有原数据的一半,就会很模糊
如果你了解到你这个视频本身码率很低的情况下,你要用的方法是低码率的方法,
如果码率很高,可以用常用的数据库和数据集去学习训练
帧率:每秒有多少帧。
分辨率:图像的大小和图像的质量 正比关系

网络摄像机:网络视频地址的形式去访问,清晰度比模拟摄像机高处不少,
比模拟摄像机的市场占有率高的多
工业摄像机:高精密仪器检测。。
焦距:决定了取景范围
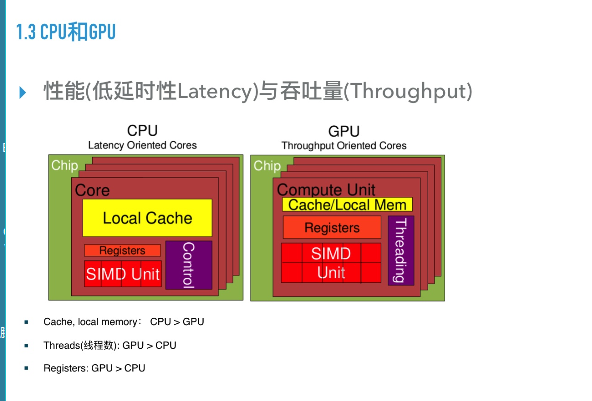
显卡GPU计算,谷歌TPU(高性能处理器)
GPU与CPU的差别:
性能(低延时性)和吞吐量
CPU:低延时性,高性能,低吞吐量,local cache比较大,同时读入大量的数据,集中分析
GPU:吞吐量很高,延时性比较高 ,cache小,并行线程非常多,处理小量数据
一张图片特别合适用GPU分析,把每一个像素,当做一个线程处理,发挥GPU性能
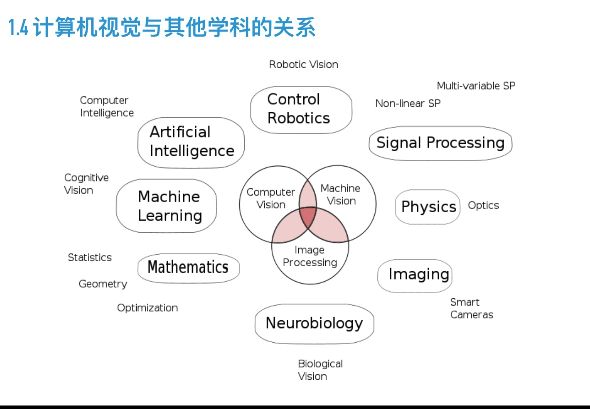
计算机视觉设计到的面非常多,除了它是人工智能的一个分支外
包括 机器学习,数学,认知神经心理学,机器人控制,信号处理。。。
计算机视觉:偏软件处理,跟应用场景相关。
机器视觉:硬件上的结合,机器人,工业级的摄像机,工业级的检测,跟计算机本身交集多
图像处理:更侧重图像像素级别的处理

cs231n 李飞飞 计算机视觉
编程语言: python(numby,scipiy,实现论文中的算法),c/c++(生产环境),熟练c/c++
Matlab(实现算法),java(实现算法)
数学基础:概率学和统计学(对样本分布的理解)---了解基本知识
几何代数,微积分,机器学习(MachineLearning)

第一本:适合入门级别(本科结束--研究生阶段,基础知识多,matlabcodes,slis(音译))
第四本:有一定计算机视觉基础(入门后),opencv软件库,非常接地气,一个情景一个 理论对应一个实现方法,快速进入开发,具备良好开发能力
第二本:对cv有一个深入的理解,计算机视觉领域的宝典,包含各个领域,权威书,工具 书
第三本:3D图形学,ar,vr,photograph,cv里面的几何知识。

两门足够了,认真看完,就是中等的cv研究人员,讲的都很深入
Cs223b,讲的更理论,纯cv
Cs231n,非常经典的课程,比223b进步的地方主要是结合深度学习的
如果主攻3D重构,图像,有cs223a(机器人导论???,live说错了吗),专门讲重构,ar,vr

非常有用的网站↑
从1994开始做的索引,涵盖了cv的所有topic,subtopic,著作,论文,教材,各类主题的关键词,会议,期刊,书籍,刚才书的第二本就有提到

深度学习的知识,唯一要看的书!
还有一些论文。。。
深度学习的入门书籍!(里面包含数学知识)
对于那行数学知识,不需要了解非常深入,但要了解到这本书前五个章节

学习一些开源的软件,框架,opencv必不可少(快速实现经典算法和函数)
重要性排序:Opencv,tensorflow(更像一门编程语言),caffe(深度学习子方向,卷积神经网络)
Torch mxnet看情况使用。。。
Ffmpeg视频转换处理,批量处理,格式的处理,很方便。

相关的论文:
每个研究方向。。
熟悉所在方向的发展历程,有那些里程碑式的文献(必须精度),研究人员写的博文
,可以从论文前言,摘要,领域的研究现状,研究过往,找到对应的文献。。
例子:利用深度学习做目标检测,这个领域在这两年里程碑式的论文,包括RNN,FAST RNN,
并且要精度。。。

每天去看一下这个网站,更新最新的研究论文。
最好写论文笔记,他解决了什么问题,用的什么方法,有没有创新点,达到了什么效果,
存在着那些缺点。


自己做的研究领域,当前顶会和顶刊,没有,可能是你after了,或者人做的少。
如果有的,你要去跟进当前最新的进展(过一遍),知道当前的潮流
----------------------------------------------------------------------------
一些问题的答案:
未来cv就业,工业应用级别C++是必须的。
cv需求还挺大
粗暴入门做项目。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号