
linux 三大利器 grep sed awk 正则表达式
正则表达式目标

正则表达式单字符:
特定字符
范围字符:单个字符[ ] :代表查找单个字符,括号内为字符范围
数字字符:[0-9],[259]
查找 0~9 和 2、5 、9 中的任意一个字符
小写字符:[a-z]
大写字符:[A-Z]
反向字符:[^0-9],[^0]
反向字^必须在 [ ]内才表示取反
任意字符:代表任何一个字符:‘.’
注意'[.]'和'\.'的区别:代表查找 . 本身这个字符
单字符小结:
- 特定字符 ‘ X’
- 范围字符 [ ] [^]
- 任意字符 .
正则表达式其他字符
- 边界字符: 头尾字符 ,注意以行作为边界而不是字符串
^ : ^luke 表示以luke这个单词开始的行,注意与[^]的区别;
luke@luke-virtual-machine:~$ grep '^root' passwd
root:x:0:0:root:/root:/bin/bash
$ : false$ 表示以false单词结尾的行
^$ : 表示空行
- 元字符(代表普通字符或特殊字符)
\w : 匹配任何字类字符,包括下划线([A-Za-z0-9])
\W : 匹配任何字类字符,包括下划线([A-Za-z0-9])
\b:代表单词的分隔
匹配一个单词边界,也就是指单词和空格间的位置,例如: 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的'er'。
正则表达字符组合
- 重复
* : 零次或多次匹配前面的字符或子表达式,字表达是用\(\)括起来,记住加反斜杠转义,\(se\)匹配se 0次或则多次;
+ : 一次或多次匹配前面的字符或子表达式;
?: 零次或一次匹配前面的字符或子表达式;
- 重复特定次数:{n,m} ,匹配前面的字符或子表达式 最少n次最多m次;
- 任意字符串的表示:.*
例如:^r.* ,表示以r开头的任意字符串
- 逻辑的表示
| : 'bin/\(false\|true\)' 逻辑或

实例:
匹配4~10位的QQ号: grep '^[0-9]\{4,10\}$' qq.txt
匹配15位到18位身份证号(支持带X) :^[1-9]([0-9]{13}|[0-9]{16})[0-9Xx]$
linux: grep '^[1-9]\([0-9])\{13\}\|[0-9]\{16\}\)[0-9Xx]$'
匹配密码,要求字母数字以及下划线组成 \w+
linux: '^\w\+$'
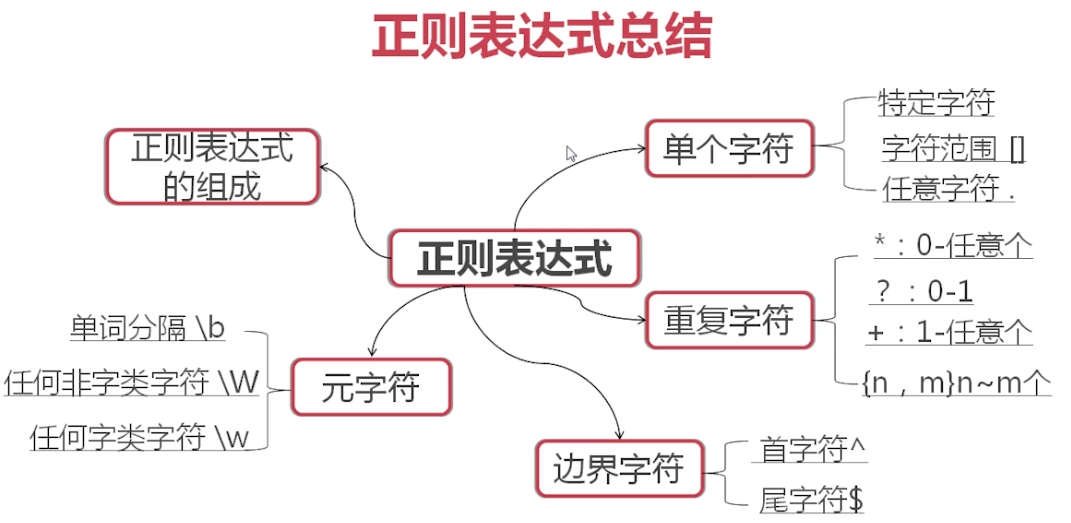
正则表达式总结:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号