Flink的几种Join总结
<1st>.Regular join组
第一种:
left join
流任务中,只要left的流数据到了,就输出。如果右边流没有到,输出 [L,NULL];如果右边流到了,输出 [L, R]
第二种:
right join
流任务中,只要right的流数据到了,就输出。如果左边流没有到,输出 [NULL,R];如果右边流到了,输出 [L, R]
第三种:
inner join
流任务中,只有两条流 Join 到才输出,输出 [L, R]
第四种:
outer join(full join)全连接
流任务中,左流或右流的数据到达之后,无论有没有 Join 到另外一条流的数据,都会输出。
对右流来说:能Join 到左边就输出 +[L, R];没 Join 到输出 +[null, R];
对左流来说:能Join 到右流就输出 +[L, R],没 Join 到输出 +[L, null];
语法示例(无设置过期时间):
SELECT *
FROM Orders
INNER JOIN Product
ON Orders.product_id = Product.id;
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.id
SELECT *
FROM Orders
RIGHT JOIN Product
ON Orders.product_id = Product.id
SELECT *
FROM Orders
FULL OUTER JOIN Product
ON Orders.product_id = Product.id
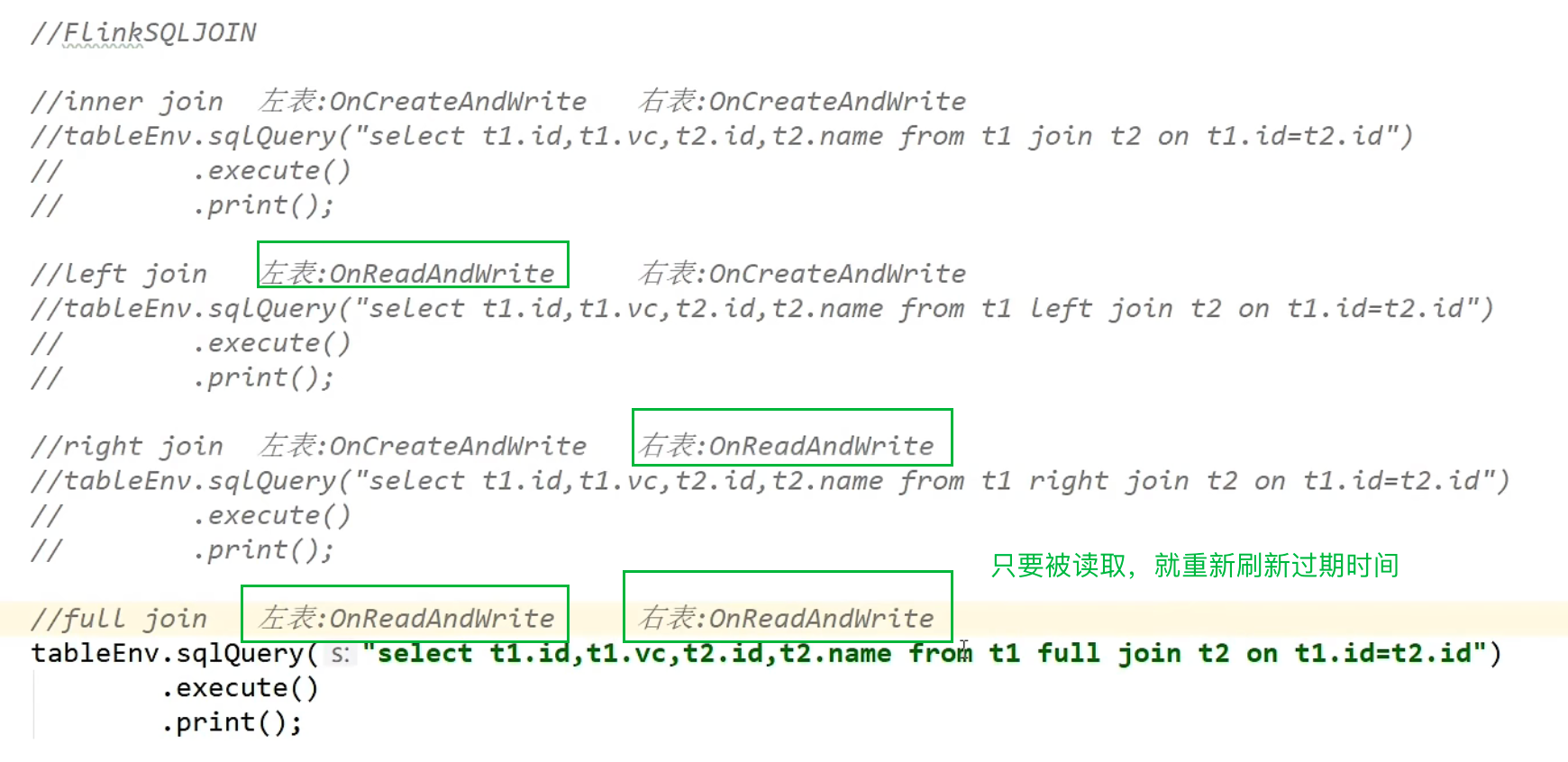
上述的这些没有设置过期时间的inner join / left join /right join /full join ,默认的数据不会过期,当然可以自己设置过期时间。
当inner join 设置了过期时间,比如10秒,那么左流和右流都是严格保存10秒,不管你是不是一直在用在read这个数据,它到时间了都会被删掉。
当left join 设置了过期时间,比如10秒,那么左流和右流是有区别的,右流还是不管你在不在用都是准时删除;而左流就是闲置10秒才会被删除,也就是如果左流的某个值一直被关联,那么就一直不会过期。
当right join 设置了过期时间,比如10秒,那么左流和右流是有区别的,左流还是不管你在不在用都是准时删除;而右流就是闲置10秒才会被删除,也就是如果右流的某个值一直被关联,那么就一直不会过期。
当 join 设置了过期时间,比如10秒,那么左流和右流都是闲置10秒才删除,也就是如果不论是左流还是右流,只要某个值一直被关联,那么就一直不会过期。
<2nd>.Interval Join组
Interval Join 可以让一条流去 Join 另一条流中前后一段时间内的数据。底层实现是同时保留2个流一定时间,然后这样一个流既可以关联另外一个流过去一段时间范围内的数据,还能关联另外一个流未来一段时间内的数据。未来的数据是指当前时刻,还没有到的数据。要做到这一点,必须要把当前流的数据也保留起来,等另外一个流的未来的数据到了,要通知到当前这条数据去重新关联一下。
第一种:
Inner Interval Join:流任务中,只有两条流 Join 到(满足 Join on 中的条件:两条流的数据在时间区间 + 满足其他等值条件)才输出,输出 +[L, R]
第二种:
Left Interval Join:流任务中,左流数据到达之后,如果没有 Join 到右流的数据,就会等待(放在 State 中等),如果之后右流之后数据到达之后,发现能和刚刚那条左流数据 Join 到,则会输出 +[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间)。如果发现发现左流 State 中的数据过期了,就把左流中过期的数据从 State 中删除,然后输出 +[L, null],如果右流 State 中的数据过期了,就直接从 State 中删除。
第三种:
流任务中,右流数据到达之后,如果没有 Join 到左流的数据,就会等待(放在 State 中等),如果之后左流之后数据到达之后,发现能和刚刚那条右流数据 Join 到,则会输出 +[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间)。如果发现发现右流 State 中的数据过期了,就把右流中过期的数据从 State 中删除,然后输出 +[L, null],如果左流 State 中的数据过期了,就直接从 State 中删除。
Full Interval Join:流任务中,左流或者右流的数据到达之后,如果没有 Join 到另外一条流的数据,就会等待(左流放在左流对应的 State 中等,右流放在右流对应的 State 中等),如果之后另一条流数据到达之后,发现能和刚刚那条数据 Join 到,则会输出 +[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间),发现 State 中的数据能够过期了,就将这些数据从 State 中删除并且输出(左流过期输出 +[L, null],右流过期输出 -[null, R])
<3rd>.Temporal Join组
Temporal Join 定义(支持 Batch\Streaming):Temporal Join 在离线的概念中其实是没有类似的 Join 概念的,但是离线中常常会维护一种表叫做 拉链快照表,使用一个明细表去 join 这个 拉链快照表 的 join 方式就叫做 Temporal Join。而 Flink SQL 中也有对应的概念,表叫做 Versioned Table,使用一个明细表去 join 这个 Versioned Table 的 join 操作就叫做 Temporal Join。Temporal Join 中,Versioned Table 其实就是对同一条 key(在 DDL 中以 primary key 标记同一个 key)的历史版本(根据时间划分版本)做一个维护,当有明细表 Join 这个表时,可以根据明细表中的时间版本选择 Versioned Table 对应时间区间内的快照数据进行 join。
Temporal Join应用场景:比如常见的汇率数据(实时的根据汇率计算总金额),在 12:00 之前(事件时间),人民币和美元汇率是 7:1,在 12:00 之后变为 6:1,那么在 12:00 之前数据就要按照 7:1 进行计算,12:00 之后就要按照 6:1 计算。在事件时间语义的任务中,事件时间 12:00 之前的数据,要按照 7:1 进行计算,12:00 之后的数据,要按照 6:1 进行计算。这其实就是离线中快照的概念,维护具体汇率的表在 Flink SQL 体系中就叫做 Versioned Table。
<4th>.Lookup Join组
Lookup Join 定义(支持 Batch\Streaming):Lookup Join 其实就是维表 Join,比如拿离线数仓来说,常常会有用户画像,设备画像等数据,而对应到实时数仓场景中,这种实时获取外部缓存的 Join 就叫做维表 Join。
Lookup Join应用场景:小伙伴萌会问,我们既然已经有了上面介绍的 Regular Join,Interval Join 等,为啥还需要一种 Lookup Join?因为上面说的这几种 Join 都是流与流之间的 Join,而 Lookup Join 是流与 Redis,Mysql,HBase 这种存储介质的 Join。Lookup 的意思就是实时查找,而实时的画像数据一般都是存储在 Redis,Mysql,HBase 中,这就是 Lookup Join 的由来
<5th>.Array Expansion组
应用场景(支持 Batch\Streaming):将表中 ARRAY 类型字段(列)拍平,转为多行
Array Expansion实际案例:比如某些场景下,日志是合并、攒批上报的,就可以使用这种方式将一个 Array 转为多行。
<6th>.Table Function组
应用场景(支持 Batch\Streaming):这个其实和 Array Expansion 功能类似,但是 Table Function 本质上是个 UDTF 函数,和离线 Hive SQL 一样,我们可以自定义 UDTF 去决定列转行的逻辑
第一种:
Inner Join Table Function:如果 UDTF 返回结果为空,则相当于 1 行转为 0 行,这行数据直接被丢弃
第二种:
Left Join Table Function:如果 UDTF 返回结果为空,折行数据不会被丢弃,只会在结果中填充 null 值
底层原理




 浙公网安备 33010602011771号
浙公网安备 33010602011771号