
Flink-v1.12官方网站翻译-P006-Intro to the DataStream API
DataStream API介绍
本次培训的重点是广泛地介绍DataStream API,使你能够开始编写流媒体应用程序。
哪些数据可以流化?
Flink的DataStream APIs for Java和Scala将让你流式处理任何它们可以序列化的东西。Flink自己的序列化器被用于
- 基本类型,即:字符串、长型、整数、布尔型、数组
- 复合类型。Tuples, POJOs, and Scala case classes.
而Flink又回到了Kryo的其他类型。也可以在Flink中使用其他序列化器。特别是Avro,得到了很好的支持。
Java元组和POJO
Flink的原生序列化器可以有效地操作元组和POJOs。
Tuples(元组)
对于Java,Flink定义了自己的Tuple0到Tuple25类型。
Tuple2<String, Integer> person = Tuple2.of("Fred", 35);
// zero based index!
String name = person.f0;
Integer age = person.f1;
POJOs
如果满足以下条件,Flink将数据类型识别为POJO类型(并允许 "按名称 "字段引用)。
- 类是公共的和独立的(没有非静态的内部类)。
- 该类有一个公共的无参数构造函数。
- 类(以及所有超级类)中的所有非静态、非瞬态字段要么是公共的(而且是非最终的),要么有公共的getter-和setter-方法,这些方法遵循Java beans中getter和setter的命名约定。
例如
public class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
. . .
};
}
Person person = new Person("Fred Flintstone", 35);
Flink的序列化器支持POJO类型的模式进化。
Scala元组和案例类
就像你期望的那样生效。
一个完整的例子
这个例子将一个关于人的记录流作为输入,并将其过滤为只包括成年人。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
public class Example {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print();
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
流执行环境
每个Flink应用都需要一个执行环境,本例中的env。流式应用需要使用一个StreamExecutionEnvironment。
在你的应用程序中进行的DataStream API调用建立了一个作业图,这个作业图被附加到StreamExecutionEnvironment上。当调用env.execute()时,这个图会被打包并发送给JobManager,JobManager将作业并行化,并将它的片断分配给任务管理器执行。你的作业的每个并行片断将在一个任务槽中执行。
注意,如果你不调用execute(),你的应用程序将不会被运行。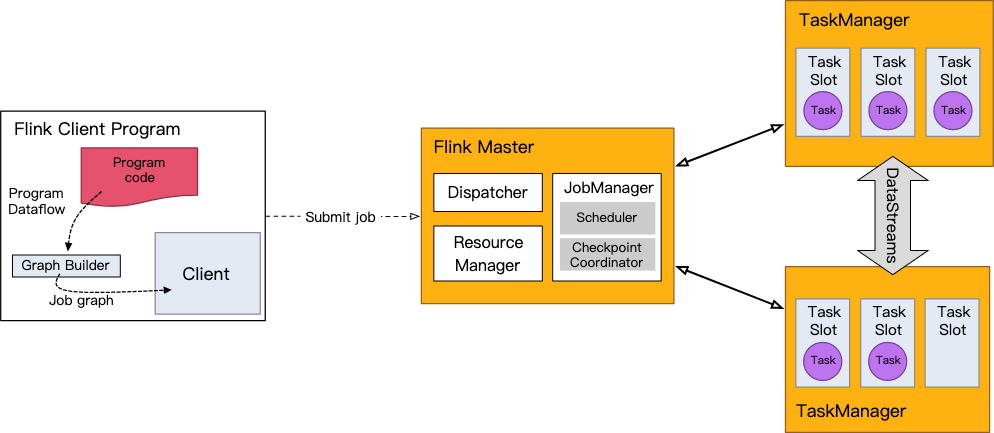
这种分布式运行时取决于你的应用程序是可序列化的。它还要求所有的依赖关系对集群中的每个节点都是可用的。
基础数据流来源
上面的例子使用env.fromElements(...)构造了一个DataStream<Person>。这是一种方便的方法,可以将一个简单的流组合起来,用于原型或测试。StreamExecutionEnvironment上还有一个fromCollection(Collection)方法。所以,你可以用这个方法来代替。
List<Person> people = new ArrayList<Person>();
people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));
DataStream<Person> flintstones = env.fromCollection(people);
另一种方便的方法是在原型开发时将一些数据导入流中,使用socket
DataStream<String> lines = env.socketTextStream("localhost", 9999)
或文件
DataStream<String> lines = env.readTextFile("file:///path");
在实际应用中,最常用的数据源是那些支持低延迟、高吞吐量并行读取并结合倒带和重放的数据源--这是高性能和容错的先决条件--如Apache Kafka、Kinesis和各种文件系统。REST API和数据库也经常被用于流的丰富。
基本数据流汇集
上面的例子使用 adults.print()将其结果打印到任务管理器的日志中(当在 IDE 中运行时,它将出现在你的 IDE 的控制台中)。这将在流的每个元素上调用toString()。
输出结果看起来像这样
1> Fred: age 35
2> Wilma: age 35其中1>和2>表示哪个子任务(即线程)产生的输出。
在生产中,常用的汇包括StreamingFileSink、各种数据库和一些pub-sub系统。
调试
在生产中,你的应用程序将在远程集群或一组容器中运行。而如果它失败了,它将会远程失败。JobManager和TaskManager日志对调试此类故障非常有帮助,但在IDE内部进行本地调试要容易得多,Flink支持这一点。你可以设置断点,检查本地变量,并逐步检查你的代码。你也可以步入Flink的代码,如果你好奇Flink是如何工作的,这可以是一个很好的方式来了解它的内部结构。
实践
在这一点上,你知道了足够的知识,可以开始编码和运行一个简单的DataStream应用程序。克隆flink-training repo,按照README中的说明操作后,进行第一个练习。过滤一个流(Ride Cleansing)。
进一步阅读
- Flink Serialization Tuning Vol. 1: Choosing your Serializer — if you can
- Anatomy of a Flink Program
- Data Sources
- Data Sinks
- DataStream Connectors

