
数据库架构
1. 基本概念
1.1 单库

1.2 分片

分片解决的是“数据量太大”的问题,也就是通常说的“水平切分”。
一旦引入分片,势必有“数据路由”的概念,哪个数据访问哪个库。
路由规则通常由3种方式:
(1)范围:range
优点:简单,容易扩展
缺点:各库压力不均(新号段更活跃)
(2)哈希:hash
优点:简单,数据均衡,负载均匀
缺点:迁移麻烦(2库扩3库数据要迁移)
(3)路由服务:router-config-server
优点:灵活性强,业务与路由算法解耦
缺点:每次访问数据库前多一次查询
大部分互联网公司采用的方案2:哈希分库、哈希路由
1.3 分组

分组解决“可用性”问题,分组通常通过主从复制的方式实现。
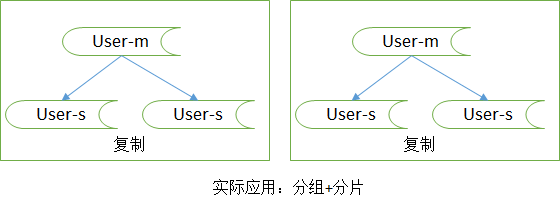
互联网公司数据库实际软件架构是:又分片、又分组(如下图)
2. 数据库架构设计思路
(1)如何保证数据可用性
(2)如何提高数据库读性能(大部分应用读多写少,读会先成为瓶颈)
(3)如何保证一致性
(4)如何提高扩展性
2.1 如何保证数据库“读”高可用
冗余读库
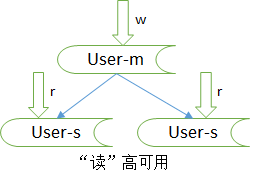
冗余读库带俩的副作用,读写有延时,可能不一致。
上面这个图中,写仍然是单点,不能保证写高可用。
2.2 如何保证数据库“写”高可用
冗余写库
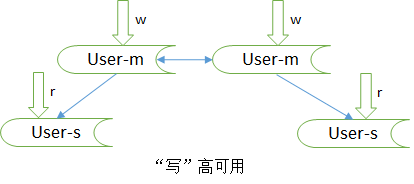
采用双主互备的方式,可以冗余写库。
带来的副作用,双写同步,数据可能冲突。
2.3 双主当主从读写
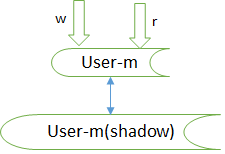
仍然是双主,但只有一个主提供服务(读+写),另一个主是“shadow-master”,只用俩保证高可用,平时不提供服务。master挂了,shadow-master顶上(virtual ip漂移,对业务层透明,不需要人工介入)
优点
(1)读写没有延时
(2)读写高可用
缺点:
(1)不能通过加从库的方式扩展读性能
(2)资源利用率为50%,一台冗余主没有提供服务
2.4 如何扩展读性能
提高读性能的方式一致有三种:(1)建立索引(2)增加从库(3)增加缓存
2.5 如何保证一致性
主从数据库的一致性,通常有两种解决方案:
(1)中间件
(2)强制读写 -- 双主当主从读写架构
数据库与缓存间的不一致:

常见的缓存架构如上,此时
写操作的顺序是:
(1)淘汰cache
(2)写数据库
读操作的顺序是:
(1)读cache,如果cache hit则返回
(2)如果cache miss,则读从库
(3)读从库后,将数据放回cache
在一些异常时序情况下,有可能从从库读到旧数据(同步还没有完成),旧数据如cache后,数据会长期不一致。
解决办法是“缓存双淘汰”,写操作时序升级为:
(1)淘汰cache
(2)写数据库
(3)在经验“主从同步延时窗口时间”后,再次发起一个异步淘汰cache的请求
这些,即使有脏数据如cache,一个小的时间窗口之后,脏数据还是会被淘汰,带来的代价是,多引入一次读miss。
2.6 如何提高数据库的扩展性
原来用hash的方式路由,分为2个库,数据量还是太大,要分为3个库,势必需要进行数据迁移。
如何实现秒级扩容?
假设数据库架构采用:双主当主从读写
不做2库变3库的扩容,而是做2库变4库(库加倍)的扩容(未来4->8->16)
假设现在有userid=1,2,3,4,5,6,7,8的用户。
hash = userid % 2,hash如果等于0,则存储在m0库,如果等于1,则存储在m1库
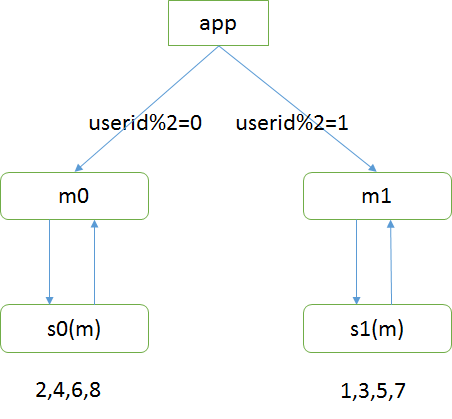
扩容步骤:
(1)将shadow-master库提升
(2)修改配置,2库变4库(原来userid%2,现在改为userid%4)
扩容成:
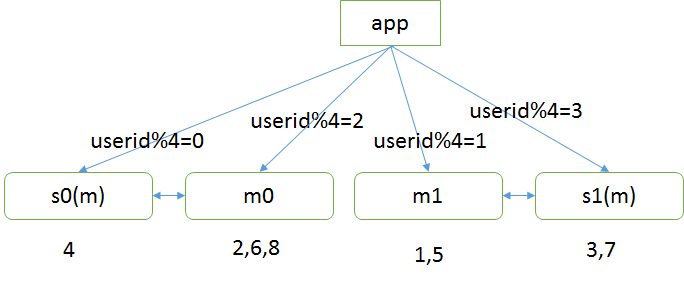
原来mod2为偶数的部分,现在会mod4余1或2
原来mod2为奇数的部分,现在会mod4余1或3
数据不需要迁移,同时互主互相同步,一边是余0,一边余2,两边数据同步也不会冲突,秒级完成扩容。
最后,要做一些收尾工作:
(1)将旧的双主同步解除
(2)增加新的双主(双主是保证可用性的,shadow-master平时不提供服务)
(3)删除多余的数据(余0的主,可以将余2的数据删除掉)
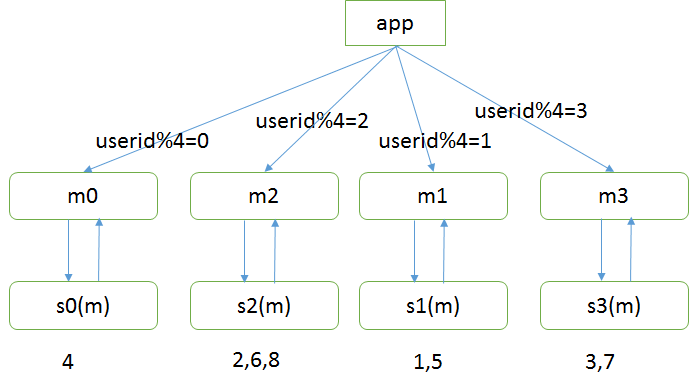
这样,秒级别内,就完成了2库变4库的扩展。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号