操作系统性能监控
1. 概述
应用的性能极限是服务等级协议中关注的重点。找到性能极限的关键在于知道该监控哪些数据、监控软件栈的哪些部分以及使用哪些工具。本篇文章将介绍需要监控的操作系统数据以及可用的操作系统性能监控攻击,还会给出一般性指导原则。主要涉及的操作系统是Windows 7和Ubuntu 12.04.5 LTS。我们更多的是介绍哪些是需要重点监控的系统属性以及为何要监控他们。
找到性能问题的第一步是监控应用的行为,通过监控提供的线索,可以将性能问题进行归类。
首先要给出几个概念的定义:性能监控,性能分析和性能调优。
性能监控:一种以非侵入方式收集或查看应用运行性能数据的活动。当应用爆出性能问题却没有足以定位根本原因的线索时,首先会进行性能监控,随后是性能分析;
性能分析:一种以侵入方式收集运行性能数据的活动,它会影响应用的吞吐量或响应性;
性能调优:一种为改善应用响应性或吞吐量而更改参数,源代码或属性配置的活动,性能调优通常是在性能监控或性能分析之后。
2. CPU
要使应用的性能或扩展性达到最高,就必须充分利用分配给它的CPU周期。特别需要注意的是:应用消耗很多CPU并不意味着性能或扩展性达到了最高。
大多数操作的CPU使用率分为用户态CPU使用率和系统态CPU使用率。用户态CPU使用率是指执行应用程序代码的时间占总CPU时间的百分比;系统态CPU使用率是指应用执行操作系统调用的时间占总CPU时间的百分比。系统态CPU使用率高意味着共享资源有竞争或IO设备之间有大量的交互。
所以在理想状态下,应用达到最高性能和扩展性时,它的系统态CPU使用率是0%,所以提供应用性能和扩展性的一个目标是尽可能降低系统态CPU使用率。
2.1 监控CPU使用率:Windows 7
Windows上最常用的CPU使用率监控工具是Task Manager(任务管理器)和Performance Monitor(性能监控器)
2.1.1 任务管理器和性能监控器
任务管理器:
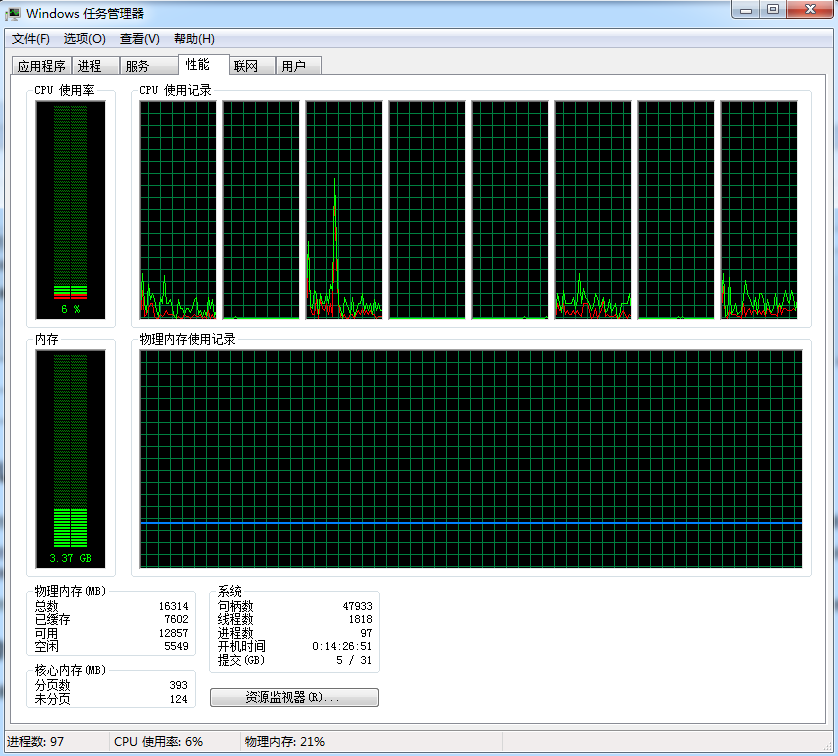
左上方CPU Usage(CPU使用率)显示了所有处理器CPU使用率的总和;
右上方CPU使用记录面板显示了每个处理器CPU使用率的历史信息,绿色线代码用户态和系统态CPU使用率的总和,红色线是系统态CPU使用率,上下两线之间的差就是用户态CPU使用率。(必须勾选菜单“查看”->“显示内核时间”才能显示系统态CPU使用率)
性能监控器:右键计算机->管理->系统工具->性能->监控工具->性能监控器
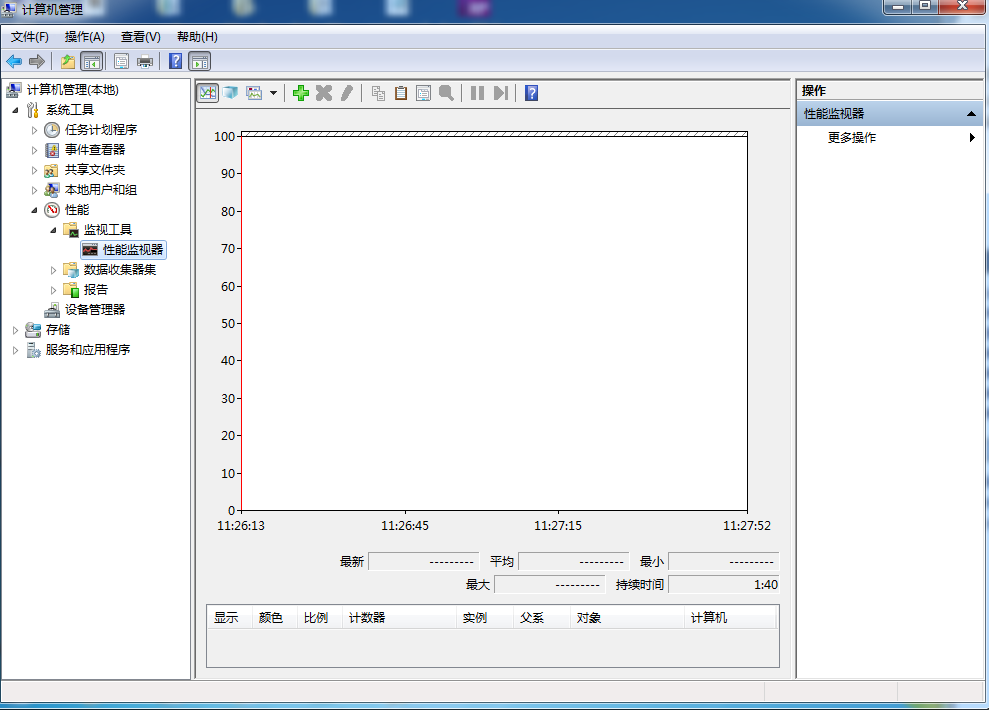
性能监控器使用了称为性能对象的概念,性能对象分为网络,内存,处理器,线程,进程,网络接口,逻辑磁盘等类别。每一类都含有特定的性能属性或计数器,可以作为监控的性能统计数据。
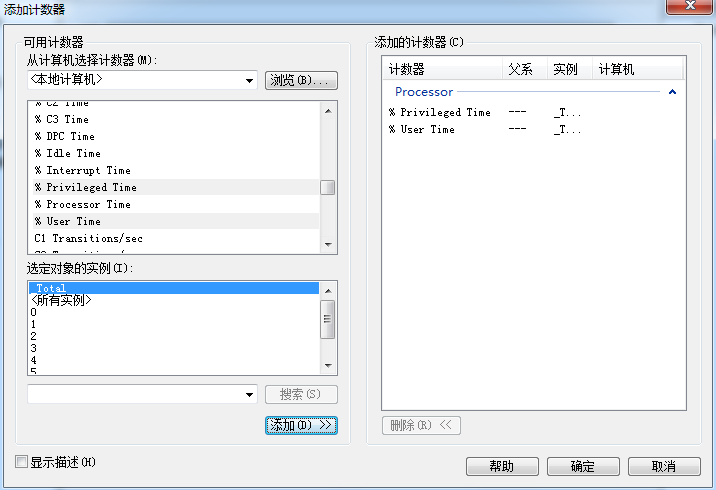
右键性能监控器的显示区域,在弹出菜单中选择Add Counters(添加计数器),选择性能对象Processor,选择计数器%User Time和%Privileged Time在点击Add按钮,即可监控用户态CPU使用率和系统态CPU使用率。注:Windows使用术语Privileged Time描述内核或系统态CPU使用率。如图:
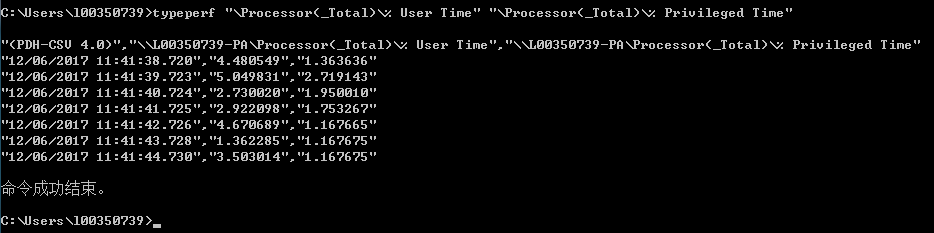
如下是实际的监控数值:
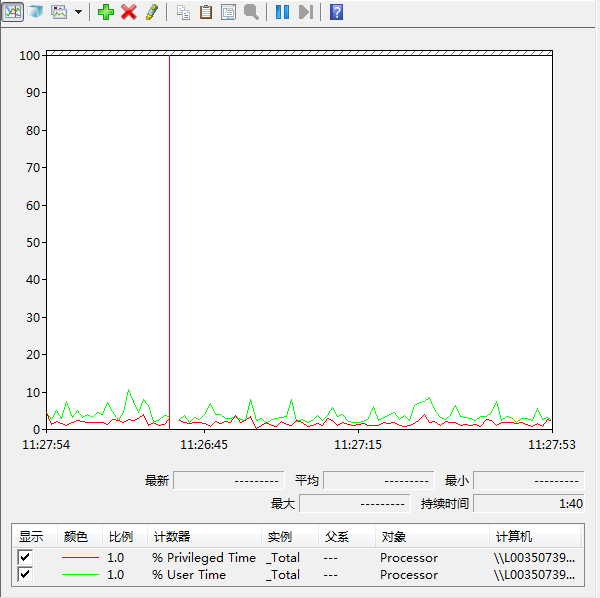
本实例中的User Time高于Privileged Time,这和预想的结果一致,即执行应用程序代码的时间超过执行操作系统内核代码的时间。
2.1.2 Windows typeperf
Windows typeperf是收集操作系统性能统计数据的命令行工具。
如果要监控User Time和Privileged Time可以使用如下命令:
typeperf "\Processor(_Total)\% User Time" "\Processor(_Total)\% Privileged Time"
输出的第一行是表头,描述所采集的数据。下面几行是数据,每行的日期时间戳标示采集相应性能计数器值的时间点,默认情况下,typeperf的报告间隔是1秒,-si可以设置间隔。
2.2 监控CPU使用率:Linux
Linux提供监控CPU使用率的命令行工具,可以保留文本形式的CPU使用率运行历史或日志。
2.2.1 vmstat
vmstat显示所有虚拟处理器的总CPU使用率,而不能查看每个CPU的使用率。
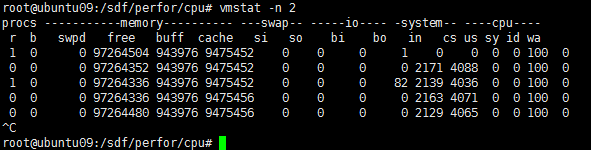
r:运行队列,运行队列中轻量级进程的实际数量;
b:阻塞的进程;
swpd:虚拟内存已使用的大小,如果大于0,标示你的物理内存不足;
free:空闲的物理内存;
buff:linux系统用来存储目录里面有什么内容,权限等的缓存;
cache:直接用来记忆我们打开的文件,给文件做缓存(把空闲的物理内存的一部分用作文件和目录的缓存,是为了提供程序执行的性能,当程序使用内存时,buffer/cached会很快被使用);
si:每秒从磁盘读入虚拟内存的大小,如果这个值大于0,标示物理内存不够用或内存泄漏;
so:每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上;
bi:块设备每秒接收的快数量;
bo:块设备每秒阿松的快数量,例如读取文件,bo就要大于0,。bi和bo一般都要接近0,不然就是IO过于频繁;
in:每秒CPU中断次数,包括时间中断;
cs:每秒上下文切换次数;
us:用户态CPU使用率;
sy:系统态CPU使用率,如果太高,标示系统调用时间长,例如是IO操作频繁;
id:空闲率或CPU可用率。us,sy的和应该等于100减去id,即100-id的值;
wa:等待IO CPU时间;
2.2.2 mpstat
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
语法:
mpstat [-P { |ALL}] [internal [count]]
-P {|ALL}表示监控哪个CPU,CPU在[0, CPU个数-1]中取值;
internal相邻的两次采样的间隔时间;
count采样的次数;
实例:
mpstat -P ALL 2分别显示所有和每个CPU的信息;
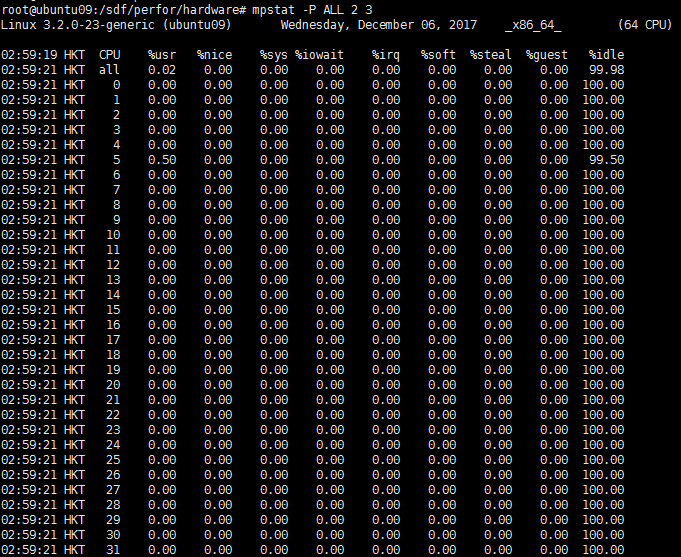
mpstat -P 0 2 3:显示CPU0的信息,mpstat 2 3:显示所有CPU的平均信息:
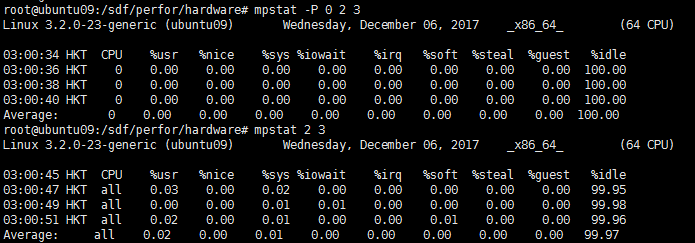
在internal时间段里,各个字段的意义:
user:用户态的CPU时间(%)
nice: 负进程的CPU时间(%)
sys:内核时间(%)
iowait:硬盘IO等待时间(%)
irq:硬中断时间(%)
soft:软中断时间(%)
idle:CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%)
2.2.3 top
top命令不仅包括CPU使用率也包括进程统计数据和内存使用率。
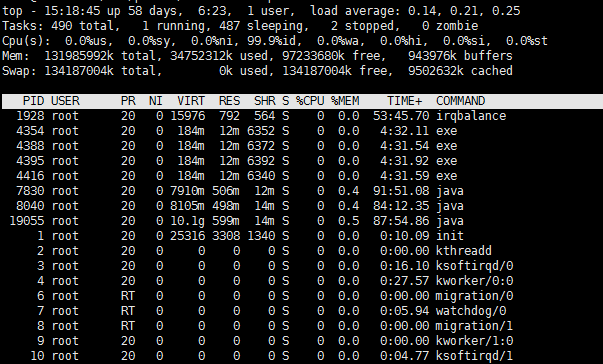
输出主要包括两部分:上半部分是整个系统的统计信息,下半部分是进程的统计信息(默认安装CPU使用率由高到低排序)
top是从进程上了解CPU使用率概况的好工具, top -p pid可以查看具体进程的CPU和内存使用率。
| 第1行 |
15:13:19 当前系统时间 xx 系统已经运行了多长时间 x users 当前有x个用户登录系统 load avage:,, 分别表示1分钟,5分钟,15分钟的负载情况;如果这个数值除以逻辑CPU的数量,结果大于5表明系统在超负荷运行 |
| 第2行 | Tasks:系统现在共有x个进程,其中处于运行中的有x个,x个在休眠(sleep),stopped状态的有x个,zombie僵尸状态的有x个。 |
| 第3行 |
us:用户空间占用CPU的百分比;sy:内核空间占用的CPU百分比;ni:改变过优先级的进程占用CPU的百分比 wa:IO等待占用CPU的百分比;hi:硬中断占用百分比,si:软中断占用百分比 |
| 第4行 |
total:物理内存总量,used:使用中的内存重量,free:空闲内存总量,buffers:缓存的内存量 used指的是现在系统内核控制的内存数,free是内核还未纳入其挂你控制范围的数量。 纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存, 内核并不把这些可被重新使用的内存交欢给free,因此linux上free内存少的时候,也不一定就是其实内存占用多。 有个近似的计算公式可以计算内存的使用量 = 第4行的free + 第4行的buffers + 第5行的cached |
| 第5行 |
total:交换区总量,used:使用的交换区总量,free:空闲交换区总量,cached:缓冲的交换区总量; 在top中要时刻监控swap交换分区的used,如果这个数值不断变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。 |
| 第6行 |
空行 |
| 第7行 |
PID进程ID;USER进程所有者;PR进程优先级,NI负值标示高优先级,正直标示低优先级;VIRT进程使用的虚拟内存总量 RES进程使用的,未被换出的物理内存大小;SHR共享内存大小;S进程状态;%CPU删词更新到现在的CPU时间占用百分比 %MEM进程使用的物理内存百分比;TIME+进程使用的CPU时间总计;COMMAND进程名称。 |
3. 内存
除了CPU使用率,还需要监控系统内存相关的属性,例如页面调度或页面交换,加锁,线程迁移中的让步式和抢占式上下文切换。系统在进行页面交换或使用虚拟内存时,Java应用或JVM会表现出明显的性能问题,当应用运行所需的内存超过可用物理内存时,就会发生页面交换。为了应对这种可能出现的情况,通常腰围系统配置swap空间。swap空间一般会在一个独立的磁盘分区上。当应用耗尽物理内存时,操作系统会将应用的一部分置换到磁盘上的swap空间,通常是应用中最少运行的部分,以免影响整个应用或应用最忙的部分。当访问应用中被置换出去的部分时,就必须将它从磁盘置换进内存,而这种砖活动会对应用的响应性和吞吐量造成很大影响。
此外,JVM垃圾收集器在系统页面交换时的性能也很差,这是由于垃圾收集器为了回收不可达对象所占用的空间,需要访问大量的内存。如果Java堆的一部分被置换出去,就必须先置换进内存以便垃圾收集器扫描存活对象,这会增加垃圾收集的持续时间。垃圾收集时一种STW操作,即停止所有正在运行的应用线程,如果此时系统正在进行页面交换,则会引起JVM长时间的停顿,如果发现垃圾收集时间变长,系统有可能正在进行页面交换。
3.1 监控内存利用率:Windows 7
在性能监控器中监控每秒内存页面调度(\Memory\Pages/Second),可用内存字节数(\Memory\Available MBytes)。当可用内存变少,而且页面调度时,系统可能正在就行页面交换。
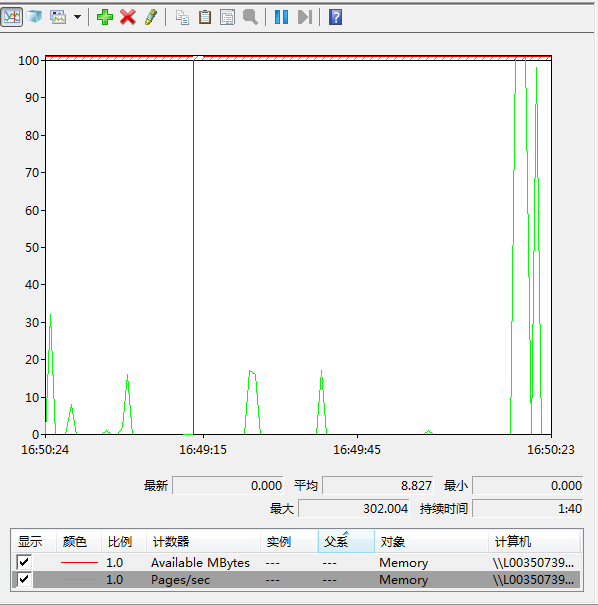
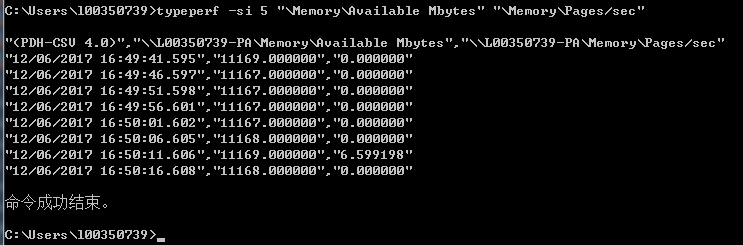
此外显示Windows页面交换的最简单方法是typeperf命令:
第一列时间戳,第二列可用内存,第三列是每秒的页面调度;
通过任务管理器可以看到大致可用的内存:
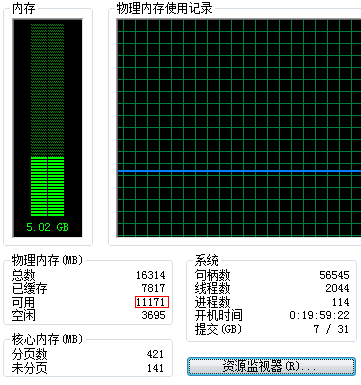
3.2 监控内存利用率:Linux
linux可以用vmstat输出中的free列监控可用内存,si和so分别表示内存页面换入和换出的量。
4. 网络IO
分布式Java应用的性能和扩展性受限于网络带宽或网络IO的性能。
4.1 监控网络IO使用率:Linux
Linux没有很好的网络工具来判断网络使用率。
4.2 监控网络IO使用率:Windows 7
Windows上监控网络使用率,不能直接通过性能监控器添加性能计数器来获得。
所以,需要知道被监控网络接口的带宽(指在单位时间(一般指的是1秒钟)内能传输的数据量,是一个理论最高值),以及网络接口传输的数据量(1秒内);
然后,利用公式计算网络IO利用率: 利用率 = 网络接口传输的数据量[1秒] / 带宽
可以从性能监控器监控:(1)Network Interface(*)\Bytes Total/sec获得网络接口传输的数据量(2)\Network Interface(*)\Current Bandwidth获取网络接口带宽
也可以通过任务管理器,直接查看网络使用率,如图:

Java网络编码建议:
单次读写数据量小而网络读写量大的应用会消耗大量的系统态CPU,产生大量的系统调用。对于这类应用,减少系统态CPU的策略是减少网络读写的系统调用;
使用非阻塞的Java NIO,而不是阻塞的java.net.Socket;
减少处理请求和发送响应的线程数,也可以改善应用性能;
从非阻塞socket中读取数据的策略是,应用在每次读请求时尽可能地读取数据,当往socket中写数据时,每个写调用应该尽可能多写入。
5. 磁盘IO
对于有磁盘操作的应用来说,查找性能问题,就应该监控磁盘IO。磁盘IO使用率是理解应用磁盘使用情况最有用的监控数据。
5.1 监控磁盘IO使用率:windows
性能监控器性能对象LogicalDisk有一些性能计数器可用来监控磁盘使用率,如图:
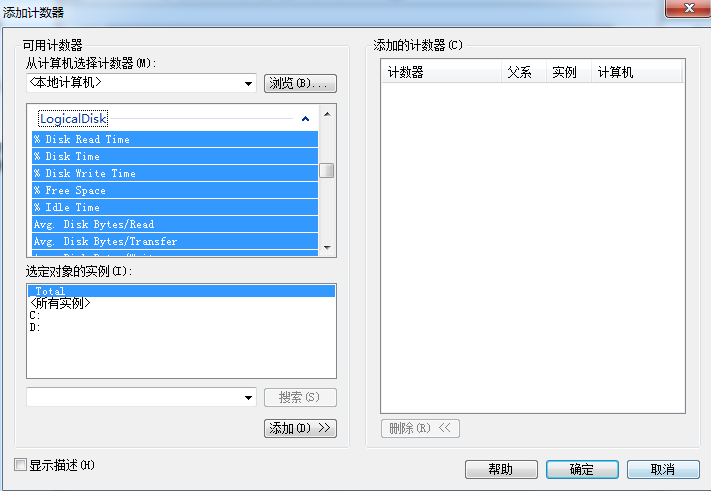
5.2 监控磁盘IO使用率:Linux
Linux可以用iostat来监控系统的磁盘使用率和系统态CPU使用率。
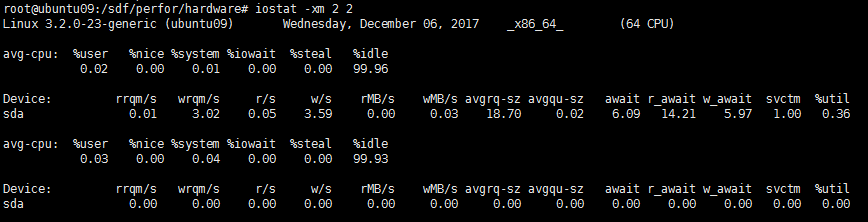
rrqm:每秒进行merge的读操作数目;wrqm:每秒进行merge的写操作数目;
r/s:每秒完成的读IO设备次数;w/s:每秒完成的写IO设备次数;
rsec/s:每秒读扇区数;wsec/s:,每秒写扇区数;
rkB/s:每秒读k字节数;wkB/s:秒写k字节数;
avgrg-sz:平均每次设备IO操作的数据大小;avgqu-sz:平均IO队列长度;
await:平均每次设备IO操作的等待时间;
svctm:平均每次设备IO操作的服务时间;
%util:每秒中有百分之几的时间用于IO操作,即被IO消耗的CPU百分比。
如果%util接近100%说明产生的IO请求太多,IO系统已经满负荷,磁盘可能存在瓶颈。如果svctm比较接近await,说明IO几乎没有等待时间;如果await远大于svctm说明IO队列太长,IO响应太慢,则需要进行必要优化。如果asgqu-sz比较大,也标示IO在等待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号