Numpy数组对象的操作-索引机制、切片和迭代方法
前几篇博文我写了数组创建和数据运算,现在我们就来看一下数组对象的操作方法。使用索引和切片的方法选择元素,还有如何数组的迭代方法。
一、索引机制
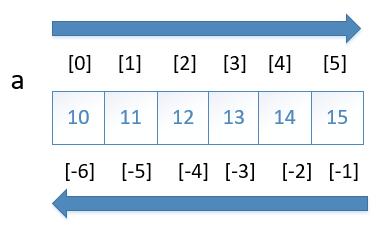
1.一维数组
In [1]: a = np.arange(10,16) In [2]: a Out[2]: array([10, 11, 12, 13, 14, 15]) #使用正数作为索引 In [3]: a[3] Out[3]: 13 #还可以使用负数作为索引 In [4]: a[-4] Out[4]: 12 #方括号中传入多数索引值,可同时选择多个元素
In [6]: a[[0,3,4]]
Out[6]: array([10, 13, 14])
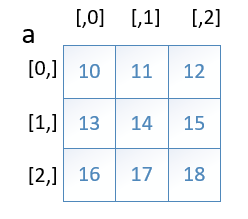
2.二维数组
二维数组也被称为矩阵,是由行和列组成的。axes为2,用0轴表示行,用1表示列。[行索引,列索引]
In [14]: A Out[14]: array([[10, 11, 12], [13, 14, 15], [16, 17, 18]])
#取出第三行第二列的元素 In [15]: A[2,1] Out[15]: 17
#可以使用方括号取出多个元素 In [17]: A[[[2,1],[1,2]]] Out[17]: array([17, 15])
二、切片操作:抽取部分数组元素生成新数组
1.一维数组切片操作
In [26]: a = np.arange(10,20) In [27]: a[2:7] Out[27]: array([12, 13, 14, 15, 16]) In [28]: a[5:8] Out[28]: array([15, 16, 17]) #设置步长 In [30]: a[2:8:2] Out[30]: array([12, 14, 16]) #省去第一个数,则认为是从0(第一个元素)开始的 In [31]: a[:8:2] Out[31]: array([10, 12, 14, 16]) #省去第二个数,则认为是取最大索引值 In [32]: a[5::2] Out[32]: array([15, 17, 19]) #省去第三个数,则认为步长为1 In [33]: a[5:8:] Out[33]: array([15, 16, 17]) #省去前两个数,则认为是选取步长为X的所有元素 In [34]: a[::2] Out[34]: array([10, 12, 14, 16, 18])
2.二维数组切片操作
二维数组的切片操作与一维数组差不多,只不过读了一个轴,那么方括号里面就要有两个值(使用逗号隔开),可以把逗号的左边和右边当做是一个一位数组,比如:A[0:2,0:2]
In [1]: A = np.arange(10,19).reshape(3,3) In [2]: A Out[2]: array([[10, 11, 12], [13, 14, 15], [16, 17, 18]]) #第一个索引使用了冒号,则代表取所有行,第二个索引是0,则代表选取第一列。即第一列的所有元素 In [3]: A[:,0] Out[3]: array([10, 13, 16]) In [4]: A[0,:] Out[4]: array([10, 11, 12])
#行选取了0:2,即第一第二行(冒号的右边表示结束值,不在选取范围之内),列也是一样的道理 In [5]: A[0:2,0:2] Out[5]: array([[10, 11], [13, 14]])
#如果要选取不连续的元素,可以将这些索引放入一个数组内。下面就是选取了第一行和第三行,第一和第二列的元素 In [6]: A[[0,2],0:2] Out[6]: array([[10, 11], [16, 17]])
3.注意:python对列表的切片得到的是数组的副本,而numpy数组切片得到的是指向相同缓冲区的视图。原数据改变,切片得到的数组也会随之改变。
三、数组的迭代
当我们用函数处理行、列或者单个元素时,会需要到数组的遍历。
1.一维数组,使用for..in循环即可
In [7]: a = np.arange(0,11) In [8]: a Out[8]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) In [9]: for i in a: ...: print i 0 1 2 3 4 5 6 7 8 9 10
2.二维数组
也可以使用for循环,嵌套使用即可。但是实际上,你会发现它总是按照第一条轴对二维数组进行扫描。
In [10]: for row in A: ...: print row ...: [10 11 12] [13 14 15] [16 17 18]
如果想遍历数组的每一个元素。可以循环遍历A.flat
In [13]: for i in A.flat: ...: print i 10 11 12 13 14 15 16 17 18
用for循环就显得没那么优雅了,numpy提供了一个更优雅的遍历方法:apply_along_axis(func,axis,arr),这个函数可以使用聚合函数对每一列或行进行处理,并返回一个数值作为结果。
这个函数接收三个参数,第一个是聚合函数,第二个是对应哪条轴(axis=0按列操作,axis=1按行操作),第三个是要处理的数组
In [14]: A Out[14]: array([[10, 11, 12], [13, 14, 15], [16, 17, 18]]) #axis为1,按行进行操作,则输出每行最大的值 In [15]: np.apply_along_axis(np.max,axis=1,arr=A) Out[15]: array([12, 15, 18]) #输出每行的平均值 In [16]: np.apply_along_axis(np.mean,axis=1,arr=A) Out[16]: array([ 11., 14., 17.])
其中,第一个参数可以传递自己写的函数
In [17]: def foo(x): ...: return x/2 In [18]: np.apply_along_axis(foo,axis=1,arr=A) Out[18]: array([[5, 5, 6], [6, 7, 7], [8, 8, 9]])
四、使用条件表达式和布尔运算符选择性地抽取元素
In [20]: B = np.random.random((3,3)) In [21]: B Out[21]: array([[ 0.11802695, 0.66445966, 0.06007488], [ 0.31908974, 0.35200425, 0.64225707], [ 0.60802331, 0.93322485, 0.28177795]]) #由条件表达式得到一个布尔数组 In [22]: B < 0.5 Out[22]: array([[ True, False, True], [ True, True, False], [False, False, True]], dtype=bool) #将条件表达式放在方括号中,可以抽取满足表达式的数组,组成一个新数组。 In [23]: B[B<0.5] Out[23]: array([ 0.11802695, 0.06007488, 0.31908974, 0.35200425, 0.28177795])
五、总结
了解的数组的索引机制,对数组的切片操作,以及遍历。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号