
Python数据结构
一.列表:在其他语言中成为数组,是一种基本的数据结构类型
1.列表中的元素如何存储
2.列表提供了哪些基本操作
3.这些操作的复杂度是多少
1.列表在内存中以一块连续的空间存放,列表中存放的是每个元素的引用
2.
新增:insert,append
删除:remove,pop
修改:根据索引修改
遍历,查找
3.
insert O(n),append O(1)
remove O(n),pop O(1)
修改 O(1)
遍历 O(n)
查找 O(n)
二.栈:栈是一种数据集合,可以理解为只在一端进行插入或删除操作的列表
特点:后进先出
基本操作:
进栈:push
出栈:pop
取栈顶元素:gettop
在python中只需要用列表就可以实现栈,创建列表li=[]
进栈:append
出栈:pop
取栈顶元素:li[-1]
栈的应用:
括号匹配问题,给一个字符串中,其中包含(,[,{ 判断该字符串中的括号是否匹配.例 ()()[]{} √,([{()}]) √,[]( X,[(]) X
思路:循环字符串,创建一个空栈,如果字符串中游匹配的字符,放入栈中,如果找到相匹配的括号,将这对括号出栈


def check_kuohao(s): stack = [] for char in s: #判断字符串中如果有括号则放入栈中 if char in {'(','[','{'}: stack.append(char) #如果匹配到括号,如果栈不为空,且栈顶有括号与之匹配,则将该元素出栈 elif char == ')': if len(stack) > 0 and stack[-1] == '(': stack.pop() else: return False elif char == ']': if len(stack) > 0 and stack[-1] == '[': stack.pop() else: return False elif char == '}': if len(stack) > 0 and stack[-1] == '{': stack.pop() else: return False #如果栈为空表示所有括号匹配成功,否则失败 if len(stack) == 0: return True else: return False
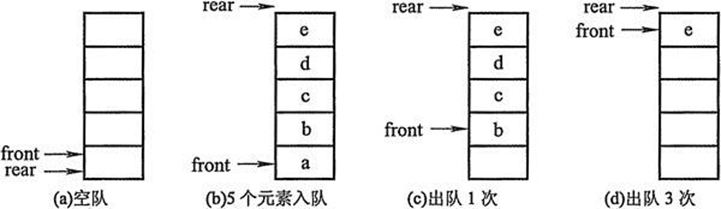
三.队列:队列是一种数据集合,仅允许在列表的一端进行插入,另一端进行删除.
插入队列的一端称为队尾,动作称为入队
删除队列的一端称为对头,动作称为出队
性质:先进先出
双向队列:队列的两头都允许进行出队和入队
使用方法: from collections import deque
创建队列: queue = deque()
进队:append
出队:popleft
双向队列队首进队:appendleft
双向队列队尾进队:pop
实现原理:
初步设想:列表+两个下标指针
实现:创建一个列表和两个变量,front指向队首,rear指向队尾,初始都为0
进队操作:元素写到li[rear]的位置,rear自增1
出队操作:返回li[front]的位置,front自减1
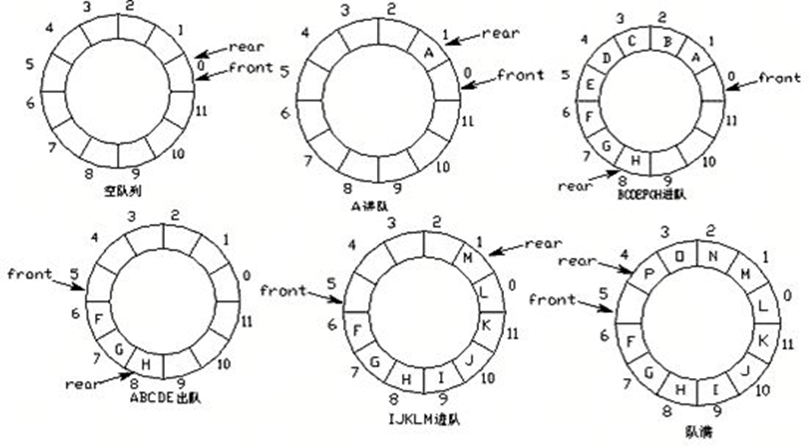
算法实现:环形队列
当队尾指针front==Maxsize+1时,在前进一个位置就自动到0
实现方式求余运算
1.队首指针前进1:front =(front+1)%Maxsize
2.队尾指针前进1:(rear+1)%Maxsize
3.队空条件: rear == front
4.队满条件: (rear+1) %Maxsize == front
四.链表:链表中每一个元素都是一个对象,每个对象称为一个节点,包含数据域和指针域,通过各个节点的相互链接,最终串成一个链表
节点定义:
class Node(object): def __init__(self,item): self.item = item self.next = None a = Node(10) b = Node(20) c = Node(30) #通过next将元素一个一个串起来 a.next = b b.next = c print(a.item) print(a.next.item)#通过next访问下一个节点 print(a.next.next.item)
遍历:
1 def travle_sal(head): 2 curNode = head 3 while curNode is not None: 4 print(curNode.item) 5 curNode = curNode.next
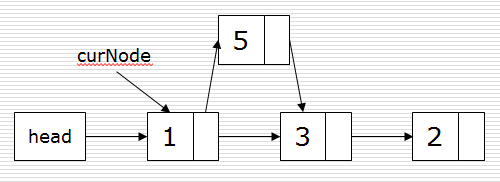
插入:
p.next = curNode.next
curNode.next = p
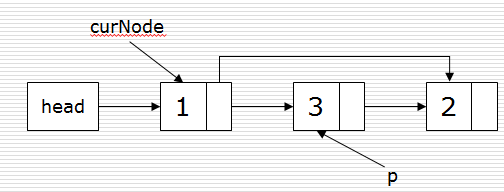
删除:
p = curNode.next
curNode.next = curNode.next.next
del p
建立链表
1.头插法
1 def createLinkListF(li): 2 l = Node() #head 3 for num in li: 4 s = Node(num) 5 s.next = l.next 6 l.next = s 7 return l
2.尾插法
1 def createLinkListF(li): 2 l = Node() 3 r = l 4 for num in li: 5 s = Node(num) 6 r.next = s 7 r = s
双向链表
双向链表的每一个节点有两个指针,一个指向右节点,一个指向左节点
节点定义
1 class Node(object): 2 def __init__(self,item): 3 self.item = item 4 self.next = None 5 self.prior = None
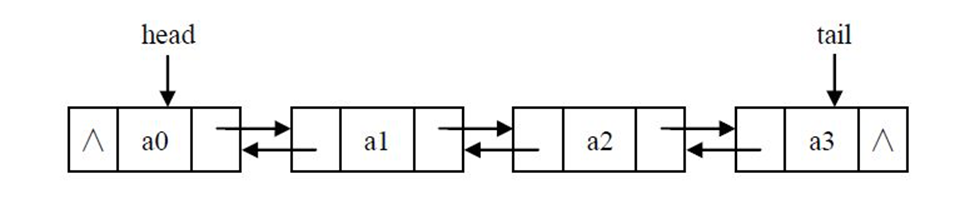
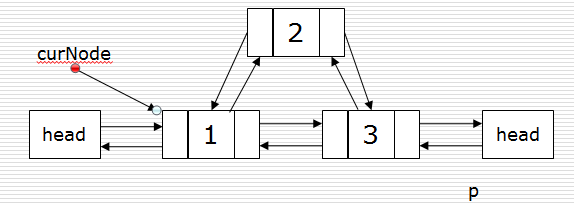
插入
p.next = curNode.next
curNode.next.prior = p
p.prior = curNode
curNode.next = p
删除
p = curNode.next
curNode.next = p.next
p.next.prior = curNode
del p
建立双向链表:
1 def createLinkListR(li): 2 l = Node() 3 r = l 4 for num in li: 5 s = Node(num) 6 r.next = s 7 s.proir = r 8 r = s 9 return l,r
链表总结
插入元素的时间复杂度 O(1)
删除元素的时间复杂度 O(1)
修改元素的时间复杂度 O(n)
查看元素的时间复杂度 O(n)
五,集合和字典
集合和字典是基于哈希表来对元素进行查找
哈希表是一种线性存储结构,通过每个对象k的关键字作为自变量,通过一个哈希函数h(k) ,把k映射到下标h(k)处,并将该对象存储到这个位置
例如:集合{1,6,7,9},假设哈希函数h(k)使得h(1) = 0,h(6)=2,h(7)=4,h(9)=5,那么哈希表被存储为[1,None,6,None,7,9],当我们查找元素6所在的位置
时,通过哈希函数获得该元素所在的下标,因此在2的位置可以找到该元素
python中的字典
例如 a={'name':'alex','age':18,'gender':'Male'}
使用哈希表存储字典,通过哈希函数将字典的key映射为下标.假设h('name') = 3,h('age') = 1,h('gender')=4,则哈希表存储为[None,18,None,'alex','Male']
在字典键值对数量不多的情况下,基本上不会发生哈希冲突,此时查找一个元素的复杂度是O(1)
哈希冲突:
由于哈希表的下标范围是有限的,而元素的关键字的值是无限的,可能会出现h(23)=56,h(1990)=56的情况,此时两个元素映射到同一个下标处,这种情况
称为哈希冲突
解决哈希冲突的方法
1.拉链法:将所有冲突的元素用链表连接
2.开发寻址法:通过哈希冲突函数得到新的地址
练习
给一个二维列表,表示迷宫,(0,通,1,阻) 给出算法,求出走出迷宫的路径

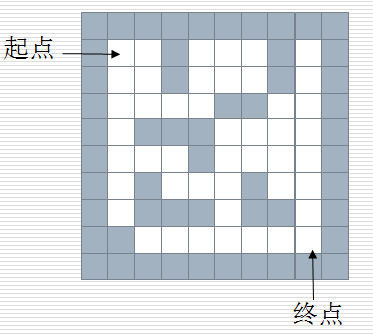
方法1:使用栈
思路:从上一个节点开始,任意找下一个能走的节点,当找到不能走的节点时,退回到上一个节点,寻找是否有其他方向的点
方法:创建一个栈,首先将入口的位置进栈,当栈不空时候循环,获取栈顶元素,寻找下一个可走的相邻方块,如果找不到可走的相邻方块,说明当前是死路,
进行回溯(将当前的点出栈,查看前面的点是否还有其他出路),体现深度优先的思想
1 maze=[ 2 [1,1,1,1,1,1,1,1,1,1], 3 [1,0,0,1,0,0,0,1,0,1], 4 [1,0,0,1,0,0,0,1,0,1], 5 [1,0,0,0,0,1,1,0,0,1], 6 [1,0,1,1,1,0,0,0,0,1], 7 [1,0,0,0,1,0,0,0,0,1], 8 [1,0,1,0,0,0,1,0,0,1], 9 [1,0,1,1,1,0,1,1,0,1], 10 [1,1,0,0,0,0,0,0,0,1], 11 [1,1,1,1,1,1,1,1,1,1], 12 ] 13 14 #方向 上右下左 15 dirs = [lambda x,y:(x+1,y), 16 lambda x,y:(x-1,y), 17 lambda x,y:(x,y-1), 18 lambda x,y:(x,y+1)] 19 20 def mpath(x1,y1,x2,y2): 21 stack = [] 22 stack.append((x1,y1)) 23 while len(stack) > 0: 24 curNode = stack[-1] 25 #找到终点 26 if curNode[0] == x2 and curNode[1] == y2: 27 for p in stack: 28 print(p) 29 return True 30 for dir in dirs: 31 nextNode = dir(*curNode) 32 #此路通的 33 if maze[nextNode[0]][nextNode[1]] == 0: 34 stack.append(nextNode) 35 #标记已走过的方格 36 maze[nextNode[0]][nextNode[1]] = -1 37 break 38 else: 39 maze[nextNode[0]][nextNode[1]] = -1 40 stack.pop() 41 return False 42 43 mpath(1,1,8,8)
方法2:使用队列
思路:从一个节点开始寻找,寻找下面能继续走的点,继续寻找直到能找出出口
方法:创建一个空队列,将起点位置入队,在队列不空时循环,出队一次,如果相邻的位置为出口,则结束.否则找出4个相邻方块中可走的方块,全部入队
体现广度优先的思想
1 from collections import deque 2 3 maze=[ 4 [1,1,1,1,1,1,1,1,1,1], 5 [1,0,0,1,0,0,0,1,0,1], 6 [1,0,0,1,0,0,0,1,0,1], 7 [1,0,0,0,0,1,1,0,0,1], 8 [1,0,1,1,1,0,0,0,0,1], 9 [1,0,0,0,1,0,0,0,0,1], 10 [1,0,1,0,0,0,1,0,0,1], 11 [1,0,1,1,1,0,1,1,0,1], 12 [1,1,0,0,0,0,0,0,0,1], 13 [1,1,1,1,1,1,1,1,1,1], 14 ] 15 16 #方向 上右下左 17 dirs = [lambda x,y:(x+1,y), 18 lambda x,y:(x-1,y), 19 lambda x,y:(x,y-1), 20 lambda x,y:(x,y+1)] 21 22 def mpath(x1,y1,x2,y2): 23 queue = deque() 24 path = [] 25 queue.append((x1,y1,-1)) 26 while len(queue) > 0: 27 curNode = queue.popleft() 28 path.append(curNode) 29 if curNode[0] == x2 and curNode[1] == y2: 30 print_p(path) 31 return True 32 33 for dir in dirs: 34 nextNode = dir(curNode[0],curNode[1]) 35 if maze[nextNode[0]][nextNode[1]] == 0: 36 queue.append((*nextNode,len(path)-1)) 37 maze[nextNode[0]][nextNode[1]] = -1 38 return False 39 40 def print_p(path): 41 curNode = path[-1] 42 realpath = [] 43 while curNode[2] != -1: 44 realpath.append(curNode[0:2]) 45 curNode = path[curNode[2]] 46 realpath.append(curNode[0:2]) 47 realpath.reverse() 48 print(realpath) 49 50 mpath(1,1,8,8)

