


C#字符串字节的获取
今天偶然发现一个问题——字符串字节获取的方式不同会导致获取的结果不一样。
定义如下方法,用于获取字符串的字节:

1 static byte[] GetBytes(string data) 2 { 3 using (MemoryStream ms = new MemoryStream()) 4 { 5 using (BinaryWriter bw = new BinaryWriter(ms)) 6 { 7 bw.Write(data); 8 9 } 10 return ms.ToArray(); 11 } 12 }
以下方式也可以获取字符串对应的字节:
1 UTF8Encoding encoding = new UTF8Encoding(); 2 int len1 = encoding.GetBytes(name).Length;
测试:
1 static void Main(string[] args) 2 { 3 string name = "123"; 4 5 UTF8Encoding encoding = new UTF8Encoding(); 6 int len1 = encoding.GetBytes(name).Length; 7 8 int len2 = GetBytes(name).Length; 9 10 Console.WriteLine($"len1 = {len1} \n\nlen2 = {len2}"); 11 12 Console.ReadKey(); 13 }
输出:
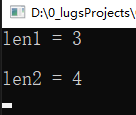
值不一样,为什么?
BinaryWriter 并没有正常地写入string的二进制,而是加了点额外的信息,这在严格要求字节正确的场景下会出问题,如http请求体,服务器会对这些多出来的字节表示懵逼。前面多出来的字节实际上是表示string的长度,叫长度前缀(length-prefixed)MSDN,据SO某答主的说法,这是供BinaryReader的ReadString方法用,知道长度,它才知道要读取到哪里。所以如果流的读取方不是BinaryReader,这些长度前缀就是多余甚至是有害的,这种情况下就不能使用BinaryWriter.Write(string)方法。要想安全地获取字符串的字节数据用UTF8Encoding的方式。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix