从原理上搞定编码(二)-- Web编码
周末宅在家里睡完觉就吃饭,吃完饭接着睡觉,这日子过的实在是没劲啊。明明还有计划中的事情没有做, 为什么就是不想去做呢,这样的生活持续下去,必然会成为一个彻头彻尾的loser。上一篇写的 初识编码 ,这一篇把web编码写出来和菜鸟们分享一下。图片比较多,手机用户不要看,流量没了俺不负责。
一.html页面编码
当浏览器请求一个静态的html页面时,服务器会将html页面的字节流通过网络传输给浏览器。浏览器再将字节流解码成相应的html文本字符,然后将html元素渲染出来。在这个流程中浏览器有一个解码html字节流的过程。浏览器如何判断用什么编码格式去解码呢?在html页面的head标签中通常会包含一个指定页面编码的<meta/>标签,如果指定的是utf-8编码,浏览器就用utf-8解码html页面。问题是在浏览器解析<meta/>标签获得页面编码之前,浏览器是用什么编码来解析<meta/>标签的呢?因为html开头都是字母,基本不会存在ASCII码之外的字符,所以识别起来还是没有难度的。
如下是我的html代码,第5行和第6行,会根据不同的测试条件分别打开注释,具体打开哪个后边会有提示。
1 <?xml version="1.0" encoding="UTF-8" ?>
2 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
3 <html xmlns="http://www.w3.org/1999/xhtml">
4 <head>
5 <!-- <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> -->
6 <!-- <meta http-equiv="Content-Type" content="text/html; charset=GBK" /> -->
7 <title>utf-8 html</title>
8 </head>
9 <body>
10 <p>Get 请求</p>
11 <form action="TestServlet" method="get">
12 <input type="text" value="你好" name="txtKey"/>
13 <input type="submit" value="提交"/>
14 </form>
15 <p>Post 请求</p>
16 <form action="TestServlet" method="post">
17 <input type="text" value="你好" name="txtKey"/>
18 <input type="submit" value="提交"/>
19 </form>
20 </body>
21 </html>
演示过程用的环境是tomcat+servlet,浏览器是chrome。项目结构如下,其中有两个html页面,index.htm页面用utf-8编码存储,lindexGBK.html页面用GBK编码存储。两个页面的html代码都是上边给出的html代码。
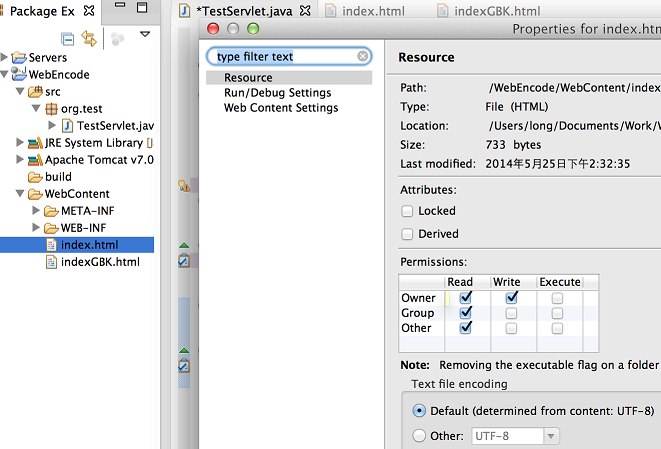
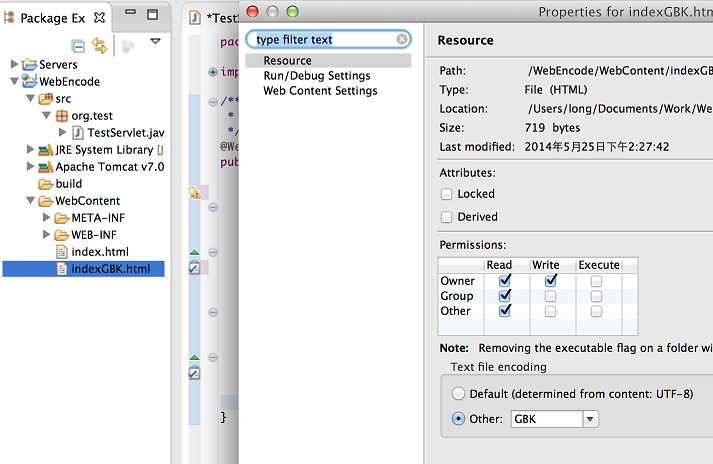
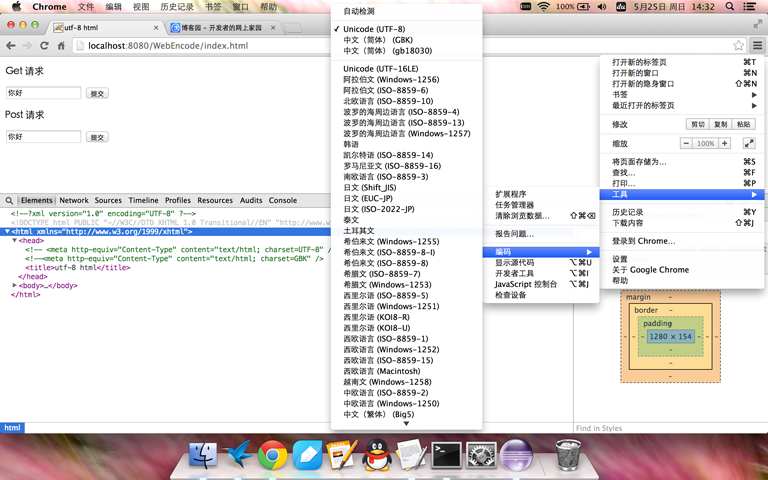
实验一: 在utf-8编码的html页面中指定不同的编码格式
启动项目,用浏览器打开index.html的url,如左下图所示,可以看出浏览器解析到<meta/>标签中的utf-8编码,并用utf-8解码html页面,页面正确显示。如果在<meta/>标签中指定页面编码为GBK,那么浏览器就用GBK解码,肯定就不能正确显示页面了,如右下图所示,页面中文出现乱码。如果想避免乱码的话,还是必须保证编解码格式统一。
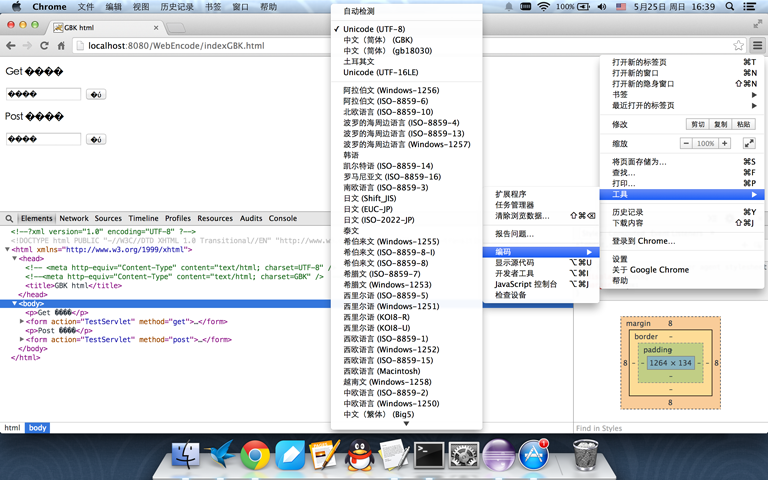
实验二: 不指定页面编码的情况下测试不同的编码页面
这次index.html和indexGBK.html都没有指定页面编码。用浏览器打开index.html对应的url,如左下图所示,可以看出浏览器用utf-8解码html页面,页面正确显示。用浏览器打开indexGBK.html对应的url,浏览器也是用utf-8解码,肯定就不能正确显示页面了,如右下图所示,页面中文出现乱码。因为在没有指定页面编码的情况下,浏览器采用操作系统默认编码,我的系统就是utf-8编码,所以index.html页面就碰巧解析正确了。
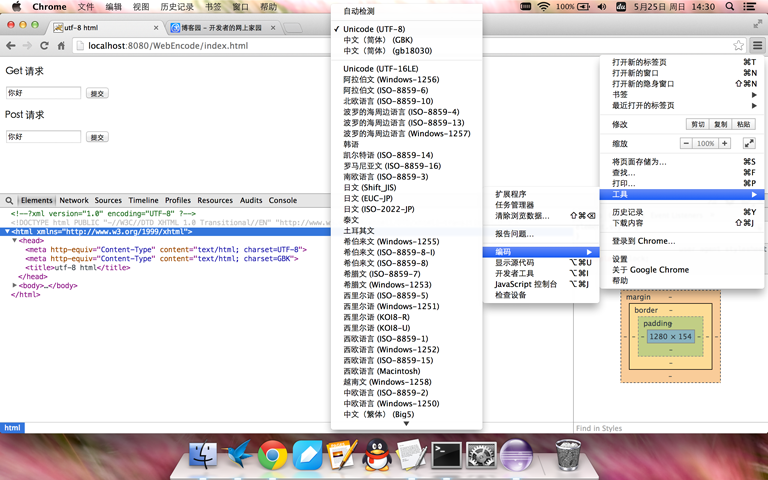
实验三: 在一个html页面中指定两个不同的编码
用浏览器打开index.html对应的url,如左下图所示,有两个<meta/>标签指定了不同的页面编码。当utf-8编码在GBK编码上面时,可以看出浏览器用utf-8解码html页面,页面正确显示。如右下图所示,如果GBK编码在utf-8编码上面,那么浏览器就用GBK解码,页面中文出现乱码。所以如果出现多个编码以第一个出现的为主,当然这种情况是不可能出现的(出现了也是代码问题),为什么会出现这种情况我觉得需要解释一下,因为浏览器在解析<meta/>标签时一旦发现页面编码,立马就用这个编码解析页面。
html的form在没有指定accept-charset属性的情况下,html的表单提交采用的编码也是指定的页面编码,如果没有指定页面编码,也是采用操作系统的默认编码。总之,html页面的加载与表单提交采用的编码格式是一样的。因为浏览器认为你指定的页面编码就是html文件的实际编码,所以不管是否乱码,它都会照做。
与html页面编码相关的还有js文件编码,默认情况下,浏览器采用html的编码格式去解码js文件。如果js文件与html页面的编码不同怎么办?script标签有一个charset属性,这个属性就决定了浏览器去加载完js,解析字节流时用的编码。
<script type="text/javascript" src="myscripts.js" charset="UTF-8"/>
二.Web后台编码
示例代码是Java写的,其他语言也是一个道理,不耽误理解。请求后台无非是GET或POST方法,原理是一样的,我只介绍POST。
html页面是utf-8格式的, 页面编码也指定为utf-8。
实验一:后台解码
后台响应代码如下所示,页面以post方式请求时会触发doPost方法。
1 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
2 System.out.println("START...");
3 String param=request.getParameter(PARAM);
4 System.out.println("原始参数");
5 System.out.println(param);
6 System.out.println("utf-8解码");
7 System.out.println(new String(param.getBytes("ISO-8859-1"),"utf-8"));
8 System.out.println("GBK解码");
9 System.out.println(new String(param.getBytes("ISO-8859-1"),"GBK"));
10 System.out.println("END...");
11 System.out.println("");
12 }
先是直接获取参数打印出来,然后又将获取的参数用ISO-8859-1编码,再用utf-8和GBK分别解码并打印出来。点击页面的Post表单提交,控制台结果如下:

html提交普通表单时,参数以字节流的方式传输到web服务器,web服务器解码字节流得到参数。tomcat默认采用ISO-8859-1编解码,所以直接获取参数是乱码,以ISO-8859-1编码回原本的字节流再用utf-8重新解码就可以得到正确的参数。
为什么tomcat采用ISO-8859-1为默认的编码格式,导致解码流程这么复杂?在servlet规范中明确规定:如果客户端请求没有指定字符编码,web容器用来创建请求读取器和解析POST 数据的编码必须是“ISO-8859-1”。为什么会有这么奇葩的规定呢?我猜可能是适应早期的浏览器吧,早期的浏览器大多采用ISO-8859-1为默认编码,这个编码的应用是非常广泛的,觉得陌生或不可思议只是因为我们在中国。稍微捋一下,ASCII码是1967年的,ISO-8859-1是1987年的,unicode是1994定稿,浏览器是在94年底95年初发布,所以估计早期的浏览器来不及用unicode作为默认编码。我是用这么一套理论来说服自己的,对不对就不重要了,总之ISO-8859-1在很多国家是普遍采用的,在人家的圈子里做东西采用人家的编码也是正常的。
可以在获取任何参数前调用 request.setCharacterEncoding("utf-8") ,即可用utf-8解码参数,就不用那么麻烦了。其他语言在原理上也都是相同的。
实验二:响应编码
响应代码更改为如下代码。
1 protected void doPost(HttpServletRequest request,
2 HttpServletResponse response) throws ServletException, IOException {
3 // response.setCharacterEncoding("utf-8"); ①
4 // response.setContentType("text/html; charset=UTF-8"); ②
5 // response.setHeader("Content-Type", "text/html; charset=UTF-8"); ③
6 PrintWriter writer = response.getWriter();
7 writer.print("<html><head><meta charset=\"utf-8\"/></head><body><font color=\"red\">你好</font></body></html>");
8 writer.close();
9 }
只在响应的html页面中指定了页面编码,显示是乱码,如左下图所示。因为在输出时并没有指定编码格式,默认采用ISO-8859-1编码,浏览器用utf-8解码自然就是乱码了。
代码中注释掉的三行,是java常用的设置响应编码方式。②跟③的效果是一样一样的,只讨论①和②。将注释①打开,响应如右下图所示,指定了响应编码为utf-8,浏览器用utf-8解码正确显示。
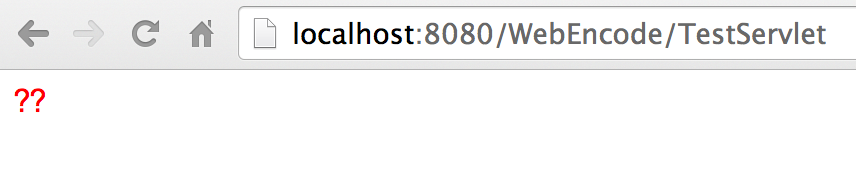
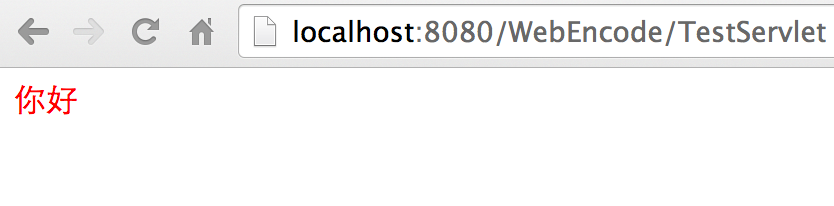
setCharacterEncoding只是把响应字符按指定格式编码,setContentType除此之外,还在header里添加了contentType属性。只把注释②打开也可以正常显示,在下图右侧ResponseHeaders中有Content-Type属性 “text/html; charset=utf-8” 。当header中出现Content-Type属性并出现指定编码,浏览器将忽略html里<meta/>标签中指定的编码,以header中的编码解码html页面。

当setCharacterEncoding和setContentType同时出现时,后边的编码会覆盖前边的编码。响应代码更改为如下所示。
1 protected void doPost(HttpServletRequest request, 2 HttpServletResponse response) throws ServletException, IOException { 3 response.setContentType("text/html; charset=utf-8"); 4 response.setCharacterEncoding("GBK"); 5 PrintWriter writer = response.getWriter(); 6 writer.print("<html><head><meta charset=\"utf-8\"/></head><body><font color=\"red\">你好</font></body></html>"); 7 writer.close(); 8 }
响应编码设为GBK,contentType属性指定的编码却是utf-8,浏览器按照contentType指定的编码来解码岂不是乱码?如下图所示,答案是否定的,真实的contentType是“text/html; charset=GBK”,这是为什么,明明设置的“text/html; charset=utf-8”。因为contentType包含的其实是两部分,一部分是text/html,第二部分是charset=utf-8。设置了contentType之后,这两部分是分别存储的,setCharacterEncoding会把第二部分编码的值覆盖掉。这时contentType就变成了“text/html; charset=GBK”。

实验四:浏览器对动态页面与静态页面在默认编码上的区别
前边说过了,html静态页面在没有指定页面编码的时候是按照系统默认编码解码的。响应代码更改如下所示。
1 protected void doPost(HttpServletRequest request,
2 HttpServletResponse response) throws ServletException, IOException {
3 response.setCharacterEncoding("utf-8");
4 PrintWriter writer = response.getWriter();
5 writer.print("<html><head></head><body><font color=\"red\">你好</font></body></html>");
6 writer.close();
7 }
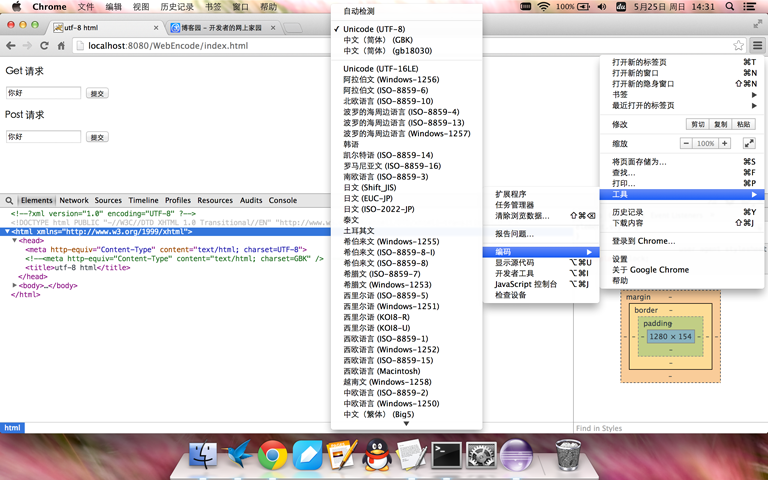
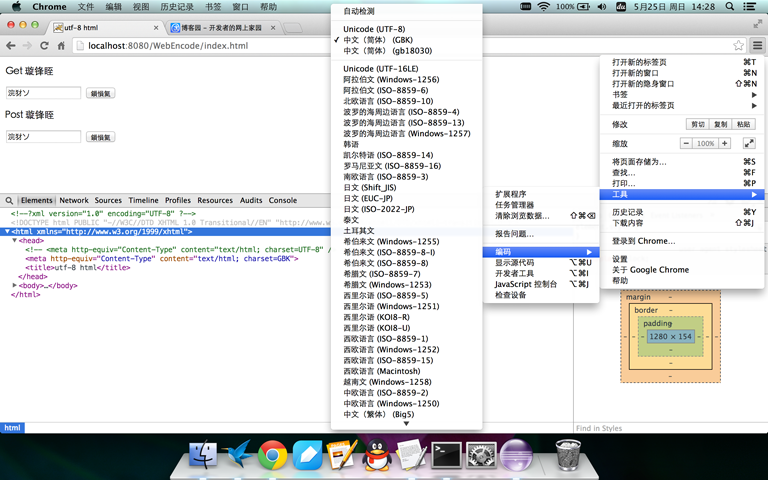
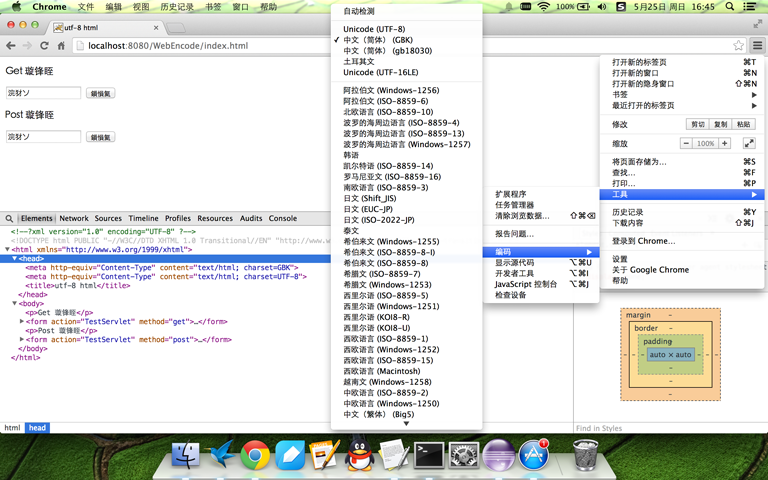
没有任何地方指定页面编码。按照静态html的规律,浏览器采用我的系统默认编码utf-8解码,不会出现乱码。但是实际情况并不是这样,如左下图所示,乱码还是出现了,因为浏览器使用的GBK去解码。这是为什么呢?打开chrome的设置-》显示高级设置-》自定义字体-》出现右下图所示的窗口,可以看到chrome的默认编码是GBK,也就说如果动态页面没有指定页面编码将会按照浏览器的默认编码来解码。为了验证我们的猜测,将chrome编码设置为utf-8,重新请求一遍,果然页面正确显示。这只是我的猜测,具体对错未知,但是未指定页面编码的情况是不多见的,大家在编码过程中一定要指定页面编码为页面实际的存储编码。
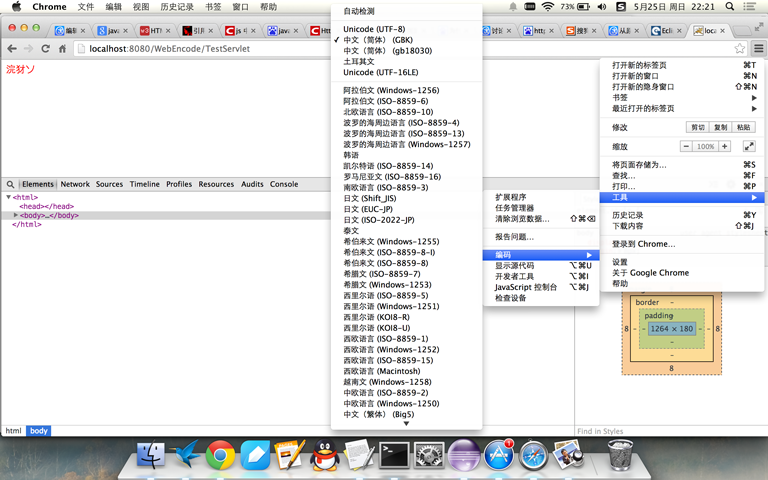

下篇文章介绍一下应用程序交互时的字节流编码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号