高性能MySQL基础篇
1. MySQL体系结构与存储引擎
MySQL 体系结构由 Client Connectors 层、MySQL Server 层及存储引擎层组成。

接下来我们用一条 SQL SELECT 语句的执行轨迹来说明客户端与 MySQL 的交互过程,如下图所示。
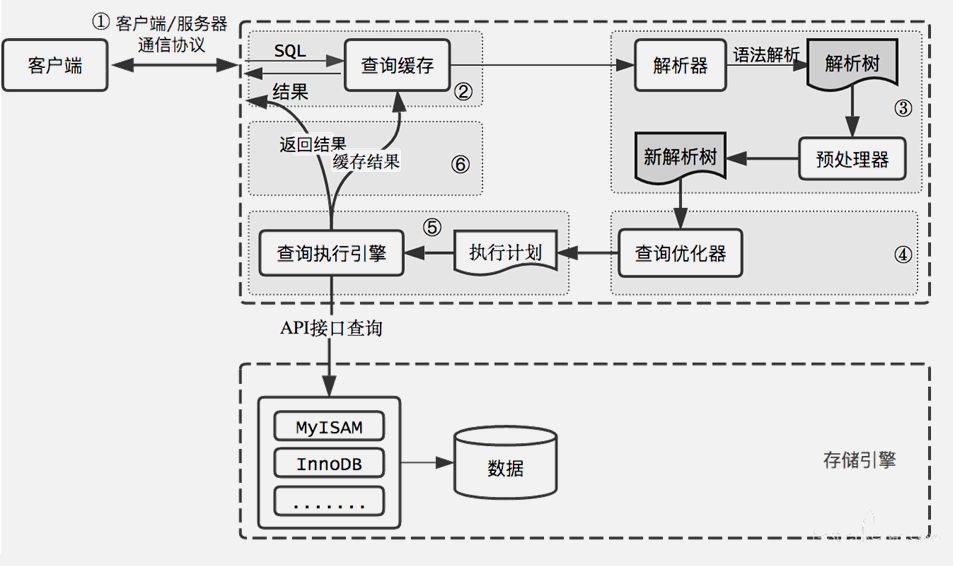
在 MySQL 5.6 版本之前,默认的存储引擎都是 MyISAM,但 5.6 版本以后默认的存储引擎就是 InnoDB 了。

2. MySQL 锁分类
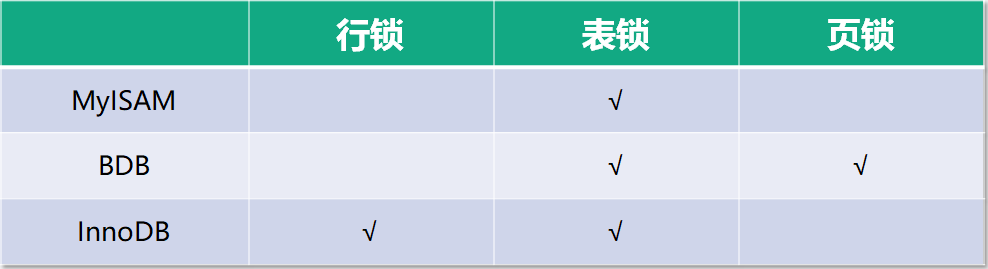
InnoDB 中的锁:在 MySQL InnoDB 存储引擎中,锁分为行锁和表锁。其中行锁包括两种锁。
1⃣️ 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
2⃣️ 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
排查 InnoDB 锁问题通常有 2 种方法。
打开 innodb_lock_monitor 表,注意使用后记得关闭,否则会影响性能。
在 MySQL 5.5 版本之后,可以通过查看 information_schema 库下面的 innodb_locks、innodb_lock_waits、innodb_trx 三个视图排查 InnoDB 的锁问题。
InnoDB 死锁
互斥条件:一个资源每次只能被一个进程使用;
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
不剥夺条件:进程已获得的资源,在没使用完之前,不能强行剥夺;
循环等待条件:多个进程之间形成的一种互相循环等待资源的关系。
建议:
加锁顺序一致;
尽量基于 primary 或 unique key 更新数据。
单次操作数据量不宜过多,涉及表尽量少。
减少表上索引,减少锁定资源。
相关工具:pt-deadlock-logger。
场景:

session1 首先拿到 id=1 的锁,session2 同期拿到了 id=5 的锁后,两者分别想拿到对方持有的锁,于是产生死锁。

session1 和 session2 都在抢占 id=1 和 id=6 的元数据的资源,产生死锁。
查看 MySQL 数据库中死锁的相关信息,可以执行 show engine innodb status\G 来进行查看,重点关注 “LATEST DETECTED DEADLOCK” 部分。
给大家一些开发建议来避免线上业务因死锁造成的不必要的影响。
更新 SQL 的 where 条件时尽量用索引;
加锁索引准确,缩小锁定范围;
减少范围更新,尤其非主键/非唯一索引上的范围更新。
控制事务大小,减少锁定数据量和锁定时间长度 (innodb_row_lock_time_avg)。
加锁顺序一致,尽可能一次性锁定所有所需的数据行。
高性能数据库表该如何设计?
1.必须指定默认存储引擎为 InnoDB,并且禁用 MyISAM 存储引擎,随着 MySQL 8.0 版本的发布,所有的数据字典表都已经转换成了 InnoDB,MyISAM 存储引擎已成为了历史。
2.默认字符集 UTF8mb4,以前版本的 UTF8 是 UTF8mb3,未包含个别特殊字符,新版本的 UTF8mb4 包含所有字符,官方强烈建议使用此字符集。
3.关闭区分大小写功能。设置 lower_case_tables_name=1,即可关闭区分大小写功能,即大写字母 T 和小写字母 t 一样。
规范命名
命名规范如下,命名时的字符取值范围为:a~z,0~9 和 _(下画线)。
1. 所有表名小写,不允许驼峰式命名;
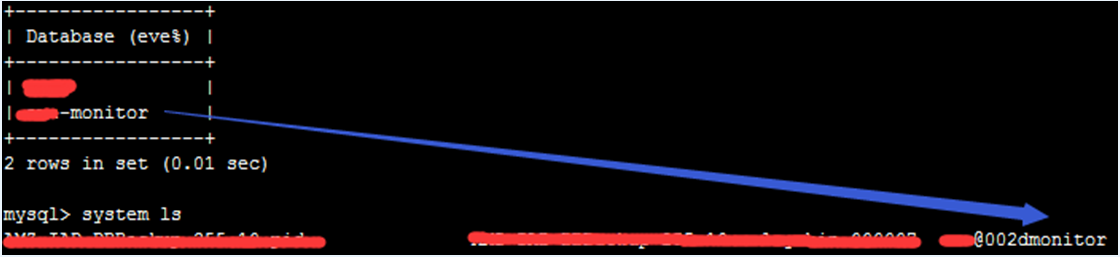
2. 允许使用 -(横线)和 (空格);如下图所示,当使用 -(横线),后台默认会转化成 @002d;
3. 不允许使用其他特殊字符作为名称,减少潜在风险。
禁用列为 NULL。
原因:
MySQL 难以优化 NULL 列;
NULL 列加索引,需要额外空间;
含 NULL 复合索引无效。
浮点数与定点数区别
浮点数:float、double(或 real)。
定点数:decimal(或 numberic)。
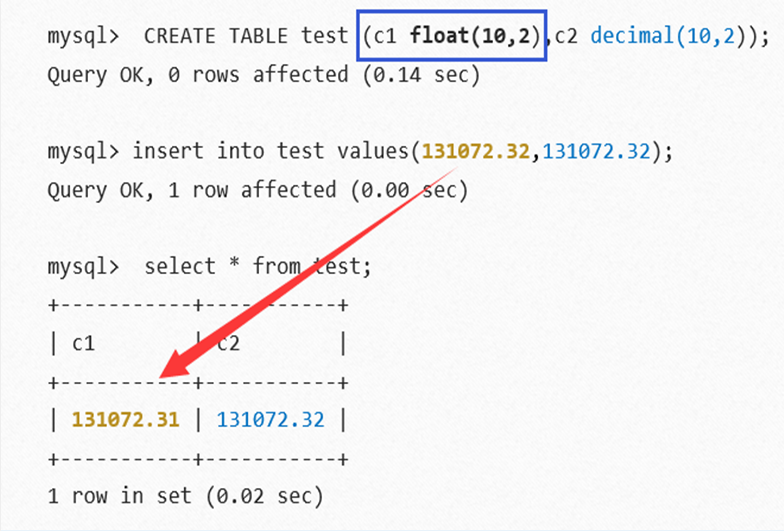
从上图中可以观察到:
1. 浮点数存在误差问题;
2. 尽量避免进行浮点数比较;
3. 对货币等对精度敏感的数据,应该使用定点数。
N 解释
字符集都为 UTF8mb4,中文存储占三个字节,而数据或字母,则只占一个字节。
1. CHAR(N) 和 VARCHAR(N) 的长度 N,不是字节数,是字符数。
如 username varchar(40) username 最多能存储 40 个字符,占用 120 个字节。
Char 与 Varchar 类型
存储字符串长度相同的全部使用 Char 类型;字符长度不相同的使用 Varchar 类型,不预先分配存储空间,长度不要超过 255。
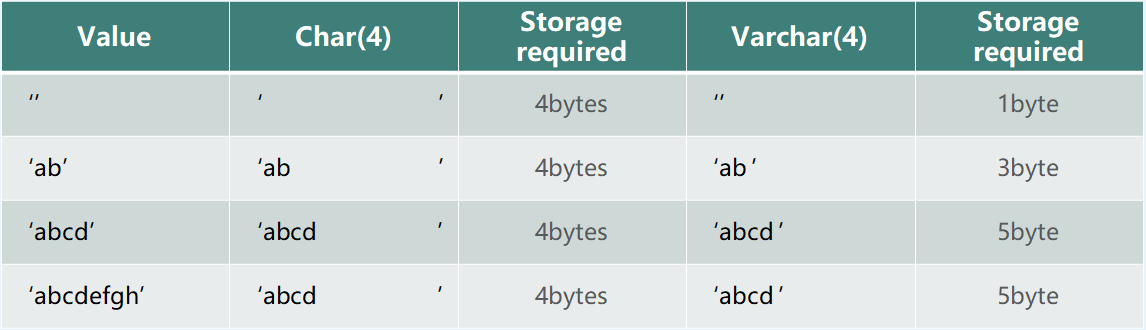
Varchar 值存储为 1 字节或 2 字节长度前缀加数据。如果值不超过 255 个字节,则列使用一个字节长度;如果值可能需要超过 255 个字节,则列使用两个字节长度。
为什么超过 255 个字节时,必须使用两个字节长度。
(28=256,1 个字节是 8 位;216=65535,2 个字节是 16 位。)
案例
1⃣️ IP处理
1. 一般使用 Char(15) 进行存储,但是当进行查找和统计时,字符类型不是很高效。
2. MySQL 数据库内置了两个 IP 相关的函数 INET_ATON()、INET_NTOA(),可以实现 IP 地址和整数的项目转换。
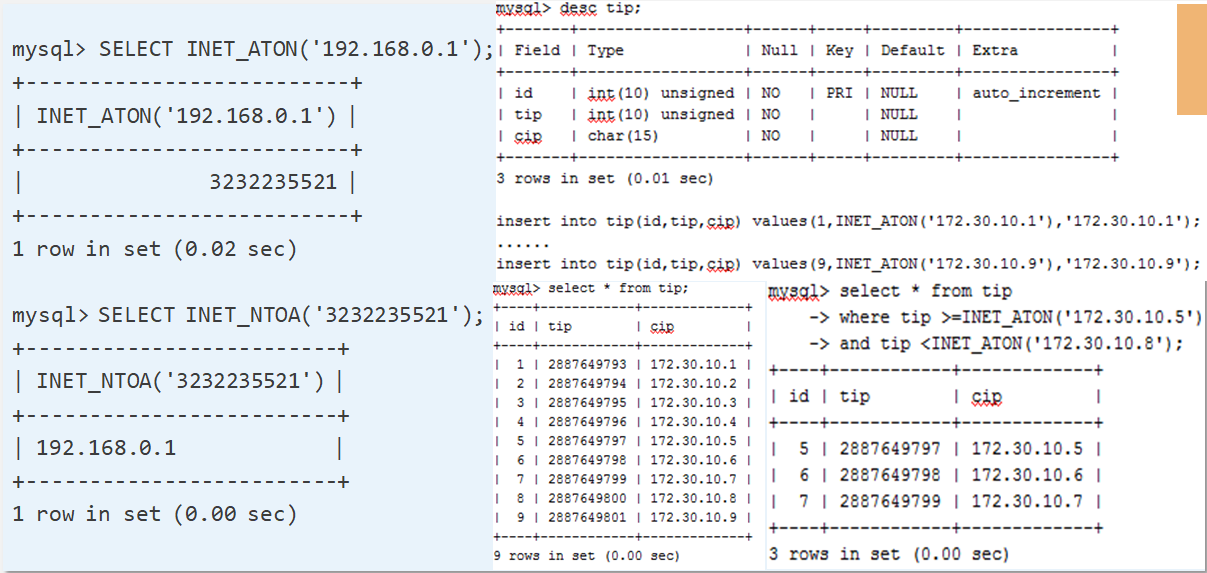
将 IP 的存储从字符型转换成整形,转化后数字是连续的,提高了查询性能,使查询更快,占用空间更小。
2⃣️ TIMESTAMP 处理
同样的方法,我们使用 MySQL 内置的函数(FROM_UNIXTIME(),UNIX_TIMESTAMP()),可以将日期转化为数字,用 INT UNSIGNED 存储日期和时间。

索引使用细节
首先是创建索引后如何确认 SQL 语句是否走索引了呢?创建索引后通过查看执行 SQL 语句的执行计划即可知道 SQL 语句是否走索引。执行计划重点关注跟索引相关的关键项,有 type、possible_keys、key、key_len、ref、Extra 等。
其中,possible_keys 表示查询可能使用的索引,key表示真正实际使用的索引,key_len 表示使用索引字段的长度。
另外执行计划中 Extra 选项也值得关注,例如 Extra 显示 use index 时就表示该索引是覆盖索引,通常性能排序的结果是 usd index > use where > use filsort,如下图所示。
key_len 计算规则
从两个方面考虑,一方面是索引字段的数据类型,另一方面是表、字段所使用的字符集。
1. 索引字段的数据类型,根据索引字段的定义可以分为变长和定长两种数据类型:
索引字段为定长数据类型,比如 char、int、datetime,需要有是否为空的标记,这个标记需要占用 1 个字节;
对于变长数据类型,比如 Varchar,除了是否为空的标记外,还需要有长度信息,需要占用 2 个字节;(备注:当字段定义为非空的时候,是否为空的标记将不占用字节)。
2. 表所使用的字符集,不同的字符集计算的 key_len 不一样,例如,GBK 编码的是一个占用 2 个字节大小的字符,UTF8 编码的是一个占用 3 个字节大小的字符。
举例说明:在四类字段上创建索引后的 key_len 如何计算呢?
Varchr(10) 变长字段且允许 NULL:10*(Character Set:utf8=3,gbk=2,latin1=1)+1(标记是否为 NULL 需要 1 个字节)+ 2(变长字段存储长度信息需要 2 个字节)。
Varchr(10) 变长字段且不允许 NULL:10*(Character Set:utf8=3,gbk=2,latin1=1)+2(变长字段存储长度信息需要2个字节),非空不再需要占用字节来标记是否为空。
Char(10) 固定字段且允许 NULL:10*(Character Set:utf8=3,gbk=2,latin1=1)+1(标记是否为 NULL 需要 1 个字节)。
Char(10) 固定字段且不允许 NULL:10*(Character Set:utf8=3,gbk=2,latin1=1),非空不再需要占用字节来标记是否为空。
判断性能好坏

创建一个 test 表。 在 a、b、c 上创建索引,执行表中的 SQL 语句,快速定位语句孰好孰坏。
首先分析 key_len, 因为 a、b、c 不允许 NULL 的 varchar(50),那么,每个字段的 key_len 为 50×4+2=202,整个联合索引的 key_len 为 202×3=606。
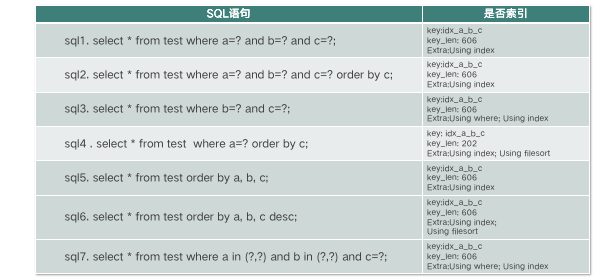
SQL1 可以使用覆盖索引,性能好;
SQL2 可以使用覆盖索引同时可以避免排序,性能好;
SQL3 可以使用覆盖索引,但是需要根据 where 字句进行过滤;
SQL4 可以使用部分索引 a,但无法避免排序,性能差;
SQL5 完全使用覆盖索引,同时可以避免排序,性能好;
SQL6 可以使用覆盖索引,但无法避免排序,这是因为 MySQL InnoDB 创建索引时默认asc升序,索引无法自动倒序排序;
SQL7 可以使用覆盖索引,但是需要根据 where 子句进行过滤(非定值查询)。
如何提高查询性能?
1. 查看 SQL 执行计划:
explain SQL;
desc 表名;
show create table 表名。
2. 通过 Profile 定位 QUERY 代价消耗:
set profiling=1;
执行 SQL;
show profiles; 获取 Query_ID。
show profile for query Query_ID; 查看详细的 profile 信息。
3. 通过 Optimizer Trace 表查看 SQL 执行计划树:
set session optimizer_trace='enabled=on';
执行 SQL;
查询 information_schema.optimizer_trace 表,获取 SQL 查询计划树;
set session optimizer_trace=‘enabled=off';开启此项影响性能,记得用后关闭。
分析慢查询常用的工具有
explain;
Mysqldumpslow,官方慢查询分析工具;
pt-query-digest,Percona 公司开源的慢查询分析工具;
vc-mysql-sniffer,第三方的慢查询抓取工具;
pt-kill,Percona 公司开源的慢查询 kill 工具,常用于生产环境的过载保护。
这里重点介绍 pt-query-digest ,它是用于分析 MySQL 慢查询的一个常用工具,先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,同时把分析结果输出到文件中。也可以结合 Anemometer 工具将慢查询平台化展示。
编写规范建议:
1. 用 IN 代替 OR。SQL 语句中 IN 包含的值不宜过多,应少于 1000 个。过多会使随机 IO 增大,影响性能。
2. 大量的更新/删除操作控制频度,例如每秒操作 2000 行以下。
3. 尽量少使用 distinct、order by、group by、union 等 SQL,排序需求可以放到前端。
4. 大事务或者长查询的需求根据业务特点拆分。
Bad SQL 案例


 浙公网安备 33010602011771号
浙公网安备 33010602011771号