【学习笔记】RNN算法的pytorch实现
一些新理解
之前我有个疑惑,RNN的网络窗口,换句话说不也算是一个卷积核嘛?那所有的网络模型其实不都是一个东西吗?今天又听了一遍RNN,发现自己大错特错,还是没有学明白阿。因为RNN的窗口所包含的那一系列带有时间序列的数据,他们再窗口内是相互影响的,这也正是RNN的核心,而不是像卷积那样直接选个最大值,RNN会引入新的参数以保证每个时刻的值都能参与进去,影响最终结果。而且这里的窗口大小,实质上是指你循环网络的层数
构造RNN
- 方式一:做自己的RNN cell,自己写处理序列的循环
- 方式二:直接使用RNN
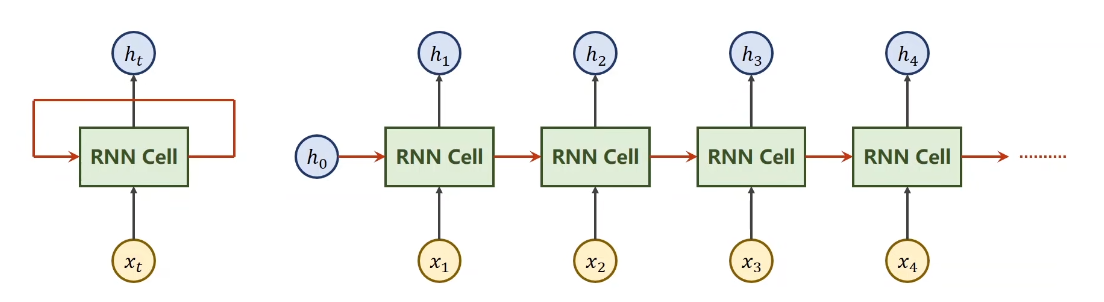
RNN cell
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
input_size这个是你输入的维度,hidden_size这个是你隐藏层的维度,只有你有了这两个值,你才能把权重和偏置的维度都确定下来
所以调用的时候不仅要给当前时刻的输入,再加上当前的hidden
hidden = cell(inpput, hidden)
比如input是x1,hidden是h0,经过cell后就算出了h1,这里有一个点很关键,就是这个input的维度和hidden的维度
input的维度包括batch和input_size,由于我们是批量输入x,所以应该是输入nx,因此batch是n,input_size就是x,而隐层的batch应该就是x乘以隐层的维度,输出维度也是相同
举例,代码和解释注释如下
import torch
batch_size = 1 # 数据量
seq_len = 3 # 序列的个数与
input_size = 4 # 输入数据的维度
hidden_size = 2 # 隐层维度
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size) # 确定cell维度
dataset = torch.rand(seq_len, batch_size, input_size) # 随便设置下数据集
hidden = torch.zeros(batch_size, hidden_size) #随便设置下隐层数据权重
for idx, input in enumerate(dataset):
print('='*20, idx, '='*20)
print('input size:', input.shape)
hidden = cell(input, hidden) //RNN计算
print('outputs size:', hidden.shape)
print(hidden)
直接使用RNN
cell = torch.nn.RNN(input_size=input_size,hidden_szie=hidden_size, num_layers=num_layers) ##num_layers代表RNN层数
out, hidden = cell(inputs, hidden) # inputs就是输入序列,hn给到out,所有的h序列给到hidden
这里输入维度要求有序列长度,batch,input_size,而隐层维度则多了一个numplayers,因为要考虑网络的层数
而输出的维度变成seqlen,batch和hidden_size,
代码如下
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
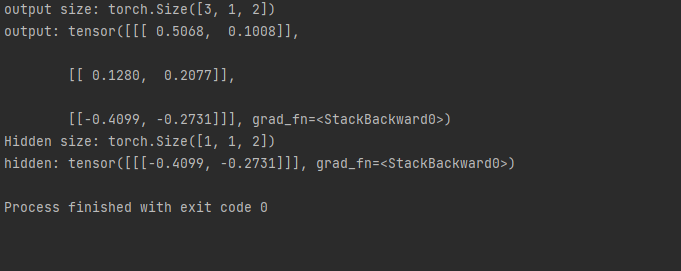
print('output size:', out.shape)
print('output:', out)
print('Hidden size:', hidden.shape)
print('hidden:', hidden)
这里就不同写循环了
其他参数batch_first:如果设置为Ture,就代表要把序列长度和样本数量维度进行交换
然后视频又介绍了如何使用词嵌入,写法如下
import torch
input_size = 4
hidden_size = 8
batch_size = 1
seq_len = 5
embedding_size = 3
num_class = 4
num_layers = 2
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [0, 0, 0, 0, 2]
inputs = torch.LongTensor(x_data).view(batch_size, seq_len)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('predicted :',''.join([idx2char[x] for x in idx]), end='')
print(',EPOCH[%d/100] loss=%.4f'% (epoch+1, loss.item()))
本文来自博客园,作者:Lugendary,转载请注明原文链接:https://www.cnblogs.com/lugendary/p/16162909.html

